MindSpore AC Model of Reinforcement Learning
MindSpore AC Model of Reinforcement Learning
The actor-critic algorithm, also referred to as the AC algorithm, is an important method of reinforcement learning. It combines the advantages of the policy gradient method and the value function method. The AC algorithm mainly consists of two parts: actor and critic.
1. Actor
o An actor selects actions based on its current state.
o Generally, a policy function π(a|s) is used to represent a probability of taking action a in a given state s.
o The actor's goal is to learn a strategy to maximize long-term cumulative rewards.
2. Critic
o A critic assesses how well the actor has done.
o The value function V(s) or Q(s, a) measures the expected rewards of state s or of taking action a in state s.
o The critic's goal is to accurately predict future rewards to guide the actor's decision-making.
3. Training process
o The actor selects an action based on the current policy, and the environment returns a new state and reward based on the action.
o The critic evaluates the value of the action based on the reward and new state, and provides feedback to the actor.
o The actor adjusts its policy through a policy gradient approach based on the feedback from the critic to improve the expected reward of its future actions.
4. Algorithm features
o Balanced exploration and utilization: The AC algorithm balances exploration (exploring new actions) and utilization (repeating known good actions) by continuously updating policies.
o Reduced variance: Due to the critic's guidance, the actor's policy update is more stable, reducing the variance in the policy gradient method.
o Applicability: The AC algorithm is applicable to discrete and continuous action spaces and can handle complex decision-making problems. In terms of pseudocode, a typical procedure of the AC algorithm includes the following steps:
5. Use the policy πθ from the participant network to sample {s_t, a_t}.
6. Evaluate the advantage function A_t, which is also referred to as a TD error δt. In the AC algorithm, the advantage function is generated by the critic network.
7. Evaluate gradients using specific expressions.
8. Update the policy parameter θ.
9. Update the weight of the value-based RL (Q-learning) according to the critic. δt is equal to the advantage function.
10. Repeat the preceding steps until the optimal policy πθ is found. The AC algorithm framework is a good starting point, but its real-world application requires further development. The main challenge is how to effectively manage the gradient updates of two neural networks (actor and critic) and ensure that they are interdependent and coordinated.
Importing packages
import argparse
from mindspore_rl.algorithm.ac.ac_trainer import ACTrainer
from mindspore_rl.algorithm.ac.ac_session import ACSession
from mindspore import context
parser = argparse.ArgumentParser(description='MindSpore Reinforcement AC')
parser.add_argument('--episode', type=int, default=1000, help='total episode numbers.')
parser.add_argument('--device_target', type=str, default='Auto', choices=['Ascend', 'CPU', 'GPU', 'Auto'],
help='Choose a device to run the ac example(Default: Auto).')
parser.add_argument('--env_yaml', type=str, default='../env_yaml/CartPole-v0.yaml',
help='Choose an environment yaml to update the ac example(Default: CartPole-v0.yaml).')
parser.add_argument('--algo_yaml', type=str, default=None,
help='Choose an algo yaml to update the ac example(Default: None).')
options, _ = parser.parse_known_args()
Starting the environment
episode=options.episode
"""start to train ac algorithm"""
if options.device_target != 'Auto':
context.set_context(device_target=options.device_target)
if context.get_context('device_target') in ['CPU']:
context.set_context(enable_graph_kernel=True)
context.set_context(mode=context.GRAPH_MODE)
ac_session = ACSession(options.env_yaml, options.algo_yaml)
Managing the context
import sys
import time
from io import StringIO
class RealTimeCaptureAndDisplayOutput(object):
def __init__(self):
self._original_stdout = sys.stdout
self._original_stderr = sys.stderr
self.captured_output = StringIO()
def write(self, text):
self._original_stdout.write(text) # Print in real time.
self.captured_output.write(text) # Save to the buffer.
def flush(self):
self._original_stdout.flush()
self.captured_output.flush()
def __enter__(self):
sys.stdout = self
sys.stderr = self
return self
def __exit__(self, exc_type, exc_val, exc_tb):
sys.stdout = self._original_stdout
sys.stderr = self._original_stderr
episode=100
# dqn_session.run(class_type=DQNTrainer, episode=episode)
with RealTimeCaptureAndDisplayOutput() as captured_new:
ac_session.run(class_type=ACTrainer, episode=episode)
import re
import matplotlib.pyplot as plt
# Original output
raw_output = captured_new.captured_output.getvalue()
# Use the regular expression to extract loss and rewards from the output.
loss_pattern = r"loss is (\d+\.\d+)"
reward_pattern = r"rewards is (\d+\.\d+)"
loss_values = [float(match.group(1)) for match in re.finditer(loss_pattern, raw_output)]
reward_values = [float(match.group(1)) for match in re.finditer(reward_pattern, raw_output)]
# Draw the loss curve.
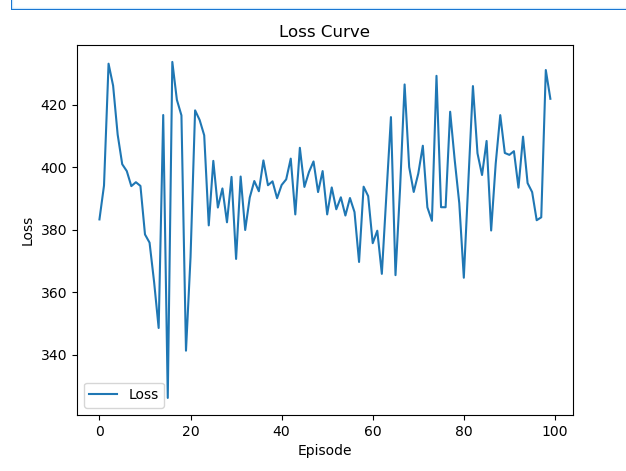
plt.plot(loss_values, label='Loss')
plt.xlabel('Episode')
plt.ylabel('Loss')
plt.title('Loss Curve')
plt.legend()
plt.show()
# Draw the rewards curve.
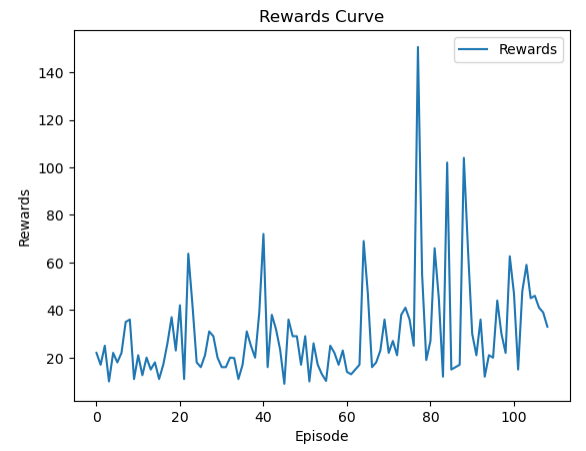
plt.plot(reward_values, label='Rewards')
plt.xlabel('Episode')
plt.ylabel('Rewards')
plt.title('Rewards Curve')
plt.legend()
plt.show()