MindSpore-based Energy Hypersphere Model Improves Event-centric Structured Prediction
MindSpore-based Energy Hypersphere Model Improves Event-centric Structured Prediction
Paper Title
SPEECH: Structured Prediction with Energy-Based Event-Centric Hyperspheres
Source
ACL 2023
Paper URL
https://aclanthology.org/2023.acl-long.21/
Code URL
https://github.com/mindspore-lab/models/tree/master/research/ZJU/speech
As an open source AI framework, MindSpore supports ultra-large-scale AI pre-training and brings excellent experience of device-edge-cloud synergy, simplified development, ultimate performance, and security and reliability for researchers and developers. To date, more than 1,000 papers about MindSpore have been published by universities and scientific research institutions at top AI conferences. In this blog, I'd like to share the paper of the team led by Ningyu Zhang from Zhejiang University (ZJU) and Bryan Hooi from the National University of Singapore. This paper is published at the Association for Computational Linguistics (ACL).

01
Research Background
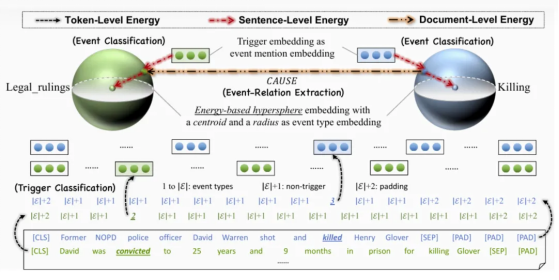
Event-centric structured prediction aims to output structured components of events. The event structures are complex with manifold dependency, including long-range dependency of tokens, association among triggers and event classes, and the dependency among event classes and event relations.
To address these issues, the authors proposed the energy-based hypersphere model SPEECH to solve event-centric structured prediction tasks. The design of the SPEECH model is mainly inspired by the law of gravity and the energy function. If an abstract event class is considered as an electron nucleus or a star, its corresponding sample can be considered as an extranuclear electron or a planet. Therefore, the authors proposed to use energy-based hyperspheres to model event classes and their samples. The model is mainly associated with the energy of three levels: token, sentence, and document.
SPEECH models complex dependency among event structured components with energy based modeling, and represents event classes with simple but effective hyperspheres. Experiments on MAVEN-ERE and OntoEvent-Doc event datasets show that the SPEECH model has significant performance in event detection and event-relation extraction tasks.
To further optimize the performance of the SPEECH model, we implemented and tested it on the MindSpore platform. As an emerging deep learning framework, MindSpore is efficient, flexible, and easy to deploy. It provides a rich tool set to accelerate model development and optimization. With the model optimization tool of MindSpore, we have iterated and tuned the structure and parameters of the SPEECH model for multiple times, further improving the model performance in event detection and event-relation extraction tasks.
02
Team Introduction
Zhang Ningyu, Associate Professor of ZJU, published multiple papers in high-level international academic journals and conferences, with research outputs covering KnowPrompt, DeepKE, EasyEdit, OceanGPT, etc. Assoc. Prof. Zhang served as the Area Chair of ACL and EMNLP, ARR Action Editor, and Senior Program Committee member of IJCAI. He also won the IJCKG Best Paper Award/nomination twice, the CCKS Best Paper Award, a provincial-level award of technology progress, and the ZJU excellent young scholar award.
03
Introduction to the Paper
The design of the SPEECH model is mainly inspired by the law of gravity and the energy function. If an abstract event class is considered as an electron nucleus or a star, its corresponding sample can be considered as an extranuclear electron or a planet. Therefore, the authors proposed to use energy-based hyperspheres to model event classes and their samples. The model is mainly associated with the energy of three levels: token, sentence, and document.
The authors mainly carried out experiments about three types of event-centric structured prediction tasks on the newly-proposed MAVEN-ERE and OntoEvent-Doc datasets. Because MAVEN-ERE does not directly publish the test set label, the datasets used were the MAVEN-ERE valid set and the OntoEvent-Doc test set.
The experiments included three types of tasks: trigger classification, event classification, and event-relation extraction.
04
Experiment Results
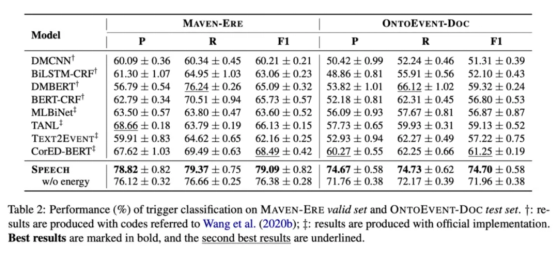
4.1 Trigger classification (for token)
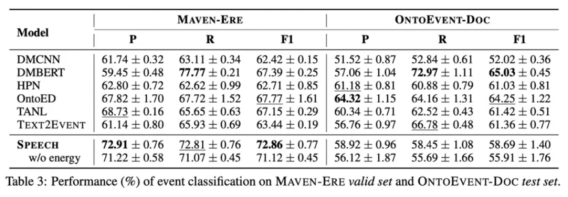
4.2 Event classification (for event mention)
4.3 Event-relation extraction (for event mention pair)
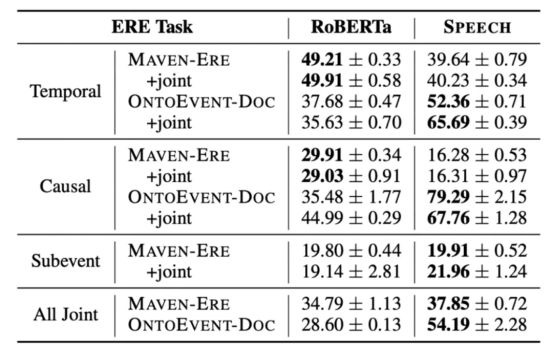
The experiment results suggested that the SPEECH model demonstrated superior performance in trigger classification and event classification tasks of MAVEN-ERE dataset, and had obvious advantages in trigger classification and event-relation classification tasks of OntoEvent-Doc dataset. Overall, the SPEECH model performed well in most of the tasks, but its effect was also affected by the datasets and data distribution.
05
Summary and Outlook
This paper proposed an energy-based hypersphere model SPEECH to solve event-centric structured prediction tasks. To solve the problem of complex event structures with manifold dependency between components, the SPEECH model used the energy function and hypersphere representation method, successfully capturing the complex dependency. The experiment results on the MAVEN-ERE and OntoEvent-Doc datasets indicated that the SPEECH model showed significant performance and precision improvement in event detection and event-relation extraction tasks.
With the continuous development of AI and deep learning technologies, MindSpore, as an efficient, flexible, and powerful framework, has a broad application prospect. It has the following advantages. The first one is efficient computing acceleration. By deeply integrating with hardware to make full use of computing resources, MindSpore significantly speeds up the model training. The second advantage is automatic mixed precision. MindSpore can automatically select proper value precision during training to reduce memory usage, improving computing efficiency. I believe that the MindSpore ecosystem will continue to expand to cover more industry applications in the future.