Based on MindSpore, Noise-Robust Continual Test-Time Domain Adaptation Is Implemented
Based on MindSpore, Noise-Robust Continual Test-Time Domain Adaptation Is Implemented
Paper title:
Noise-Robust Continual Test-Time Domain Adaptation
Source:
ACM MM2023
Paper URL:
https://dl.acm.org/doi/abs/10.1145/3581783.3612071
Code URL:
https://github.com/TL-UESTC/cotta\_mindspore
As an open-source AI framework, MindSpore supports ultra-large-scale AI pre-training and brings excellent experience of device-edge-cloud synergy, simplified development, ultimate performance, and security and reliability for researchers and developers. To date, more than 1,000 papers about MindSpore have been published by universities and scientific research institutions at top AI conferences. In this blog, I'd like to share the paper of the team led by Pro. Li Jingjing, School of Computer Science and Engineering, University of Electronic Science and Technology of China.
1 Research Background
Unsupervised Domain Adaptation (UDA) aims to migrate knowledge from labeled source domains to unlabeled target domains without precision loss. Although UDA methods are theoretically attractive, they usually require exposure to source domain data during training, which may not be realistic in some application scenarios. Further, Test-time Domain Adaptation (TTDA) methods emerge, which allow a pre-trained model to be adapted to a new domain without using any source data. However, the iterative training required by TTDA may not be practical for some online devices. This leads to a more challenging scenario: Continual Test-time Domain Adaptation (CTTDA), where the model is adapted during inference while the distribution of the target domain is still changing.
Multimedia edge devices in the real world, such as autonomous vehicles, need to be updated with their model parameters to respond to a changing environment condition, for example, foggy days or blurred views. However, existing methods often ignore the noise problem introduced by multimedia edge devices. These problems are common in the real world, and may be caused by sensor degradation due to untimely maintenance or due to limited capabilities of edge devices. Given that Gaussian noise is very common in data acquisition carried out by multimedia edge devices, especially in practical scenarios involving uneven luminance, circuit element noise, and long-term operation of image sensors, additional Gaussian noise is added in the paper experiments and significant performance degradation of existing methods is observed. This highlights the importance of solving the noise problem in the target domain dataset.
This paper proposes a new method to solve the noise problem in CTTDA from the perspective of noise robustness. In this paper, three effective strategies are used to mitigate the impact of noise: Taylor cross entropy loss is used at the category level to mitigate the low confidence category deviation related to cross entropy; target samples are re-weighted at the sample level based on uncertainty to prevent the model from overfitting noise samples. Finally, in order to reduce pseudo-label noise, this paper proposes a soft ensemble negative learning mechanism, which uses ensemble supplementary pseudo-labels to guide model optimization.
2 Team Introduction
Li Jingjing, researcher and doctoral advisor in the School of Computer Science and Engineering, University of Electronic Science and Technology of China, has published more than 70 articles in JCR journals and CCFA conferences, such as TPAMI, TIP, TKDE, CVPR, and MM. His research results were highly cited and selected as the best candidate for ACM MM papers, ESI hot papers, and top 100 most internationally influential academic papers in 2019. In addition, he has won several provincial and national awards for his outstanding academic researches.
3 Introduction to the Paper

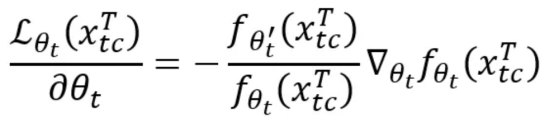

3.2 Uncertainty-Based Noise Re-weighting
The previous section discussed that the cross-entropy loss may be biased towards low-confidence categories at the category level, which may be detrimental to CTTDA. At the instance level, historical methods use the same weights for all samples during the model parameter update process. However, the paper suggests that some target samples may be unhelpful or even detrimental to the adaptation task, especially in the presence of noise and domain migration. Therefore, this paper proposes to re-weight the sample based on the output uncertainty. There are two main benefits of this operation:
(a) For some noise samples, the output uncertainty of the model is often high, and the robustness of the model can be improved by reducing the impact of noise through reweighting.
(b) During CTTDA, some difficult samples may deviate from the source model. By assigning lower weights to these samples, the possibility of catastrophic forgetting can be reduced. This paper uses the output entropy of the teacher network as an estimate of the sample uncertainty:
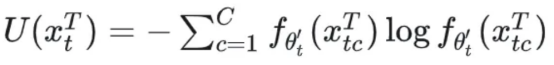
C indicates the total number of label types. The teacher network is used for uncertainty estimation because it is more stable than the student network. On the basis of this estimation, the weight of each sample is re-calibrated using a negative exponential function:
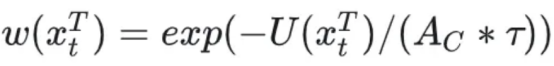

3.3 Soft Ensemble Negative Learning
In the teacher-student network, the prediction of the teacher model is used as a pseudo-label to guide student optimization. However, inaccurate teacher predictions may introduce label noise. To highlight the impact of label noise, this paper tries to generate one-hot pseudo-labels directly from the teacher's prediction. Surprisingly, this approach results in a decrease in model precision. This phenomenon can be attributed to the constant changes in the data distribution in the CTTDA setup, which leads to the accumulation of a large number of imprecise pseudo-labels.
In order to reduce the probability of pseudo labels, this paper proposes to introduce complementary labels in negative learning. It is often easier to identify the wrong category label of a sample than to identify the real label. For example, if the output of a model for a sample is [0.6, 0.3, 0.1], the simple pseudo label may be [1, 0, 0], but the corresponding complementary label may be [0, 1, 0] or [0, 0, 1]. In terms of independent label distribution, the error probability of the former is 2/3, and the error probability of the latter is only 1/3.
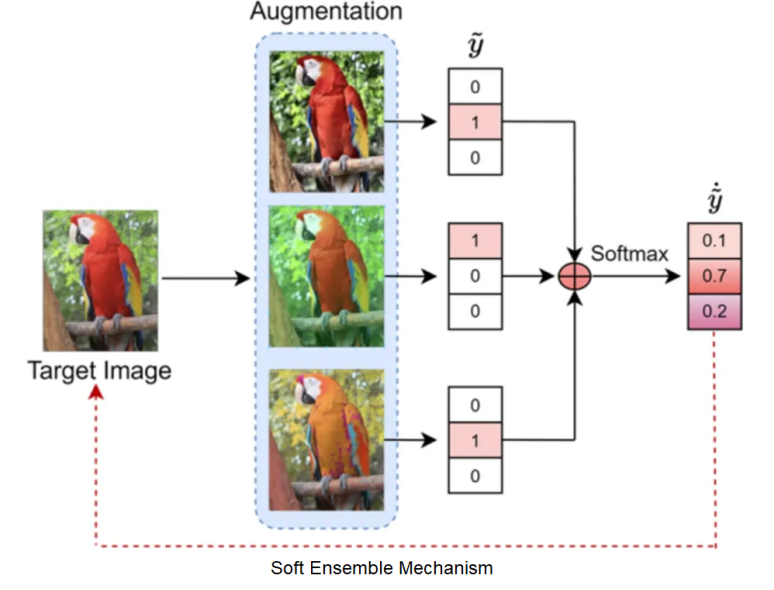
Soft ensemble mechanism
In order to improve the accuracy of complementary pseudo labels, an ensemble mechanism is also used to summarize the complementary labels output by the models of different augmented versions of the same target image. The enhancement tools include color jitter, random affine, Gaussian blur, random horizontal flipping, and Gaussian noise, as shown in the preceding figure. Finally, the softmax operation is used to simulate the real label distribution to prevent model overfitting. The process can be expressed as:
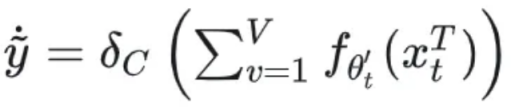

4 Experiment Results
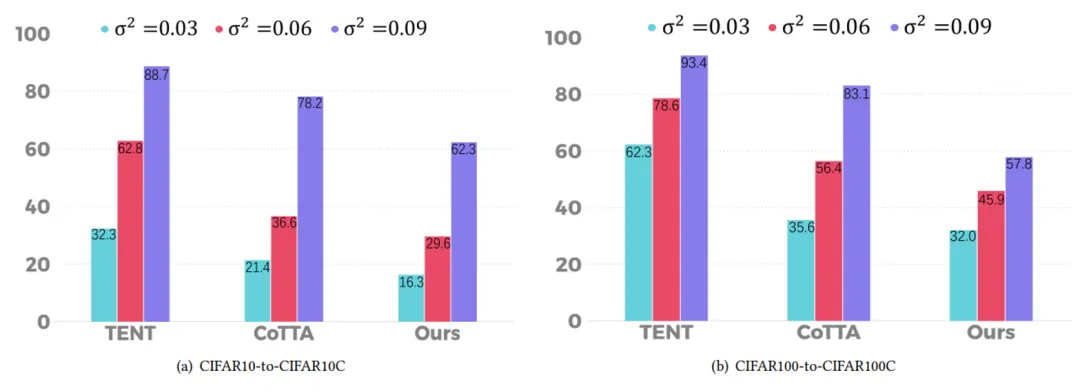
This paper experiments on multiple public datasets, including CIFAR10-to-CIFAR10C, CIFAR100-to-CIFAR100C and ImageNet-to-ImageNet-C. The experimental results show that the proposed method has better performance than other methods (the index is the classification error rate).
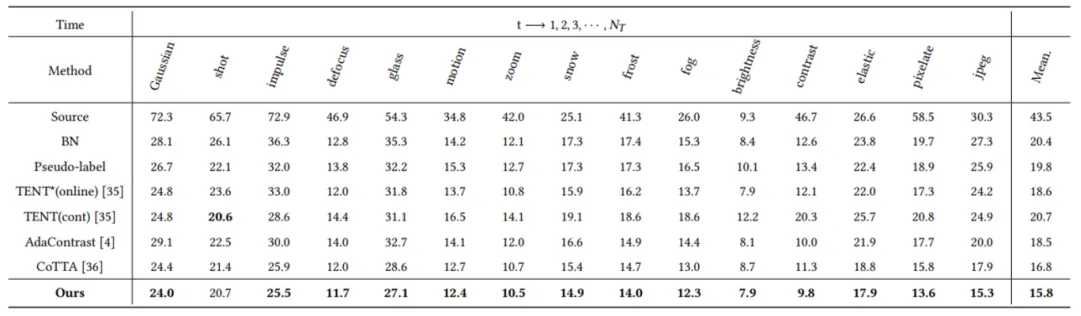
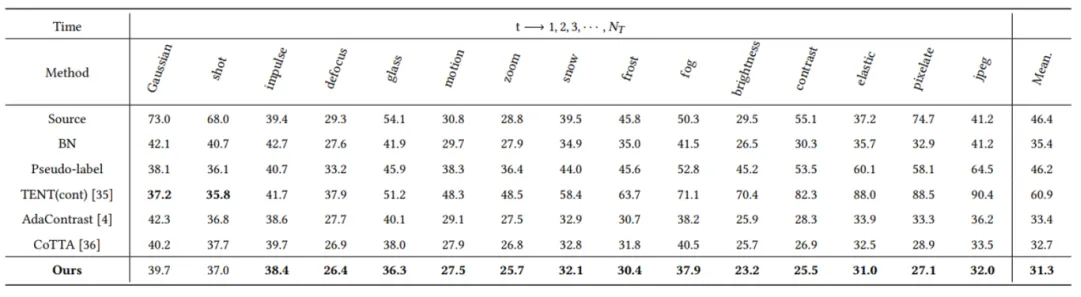
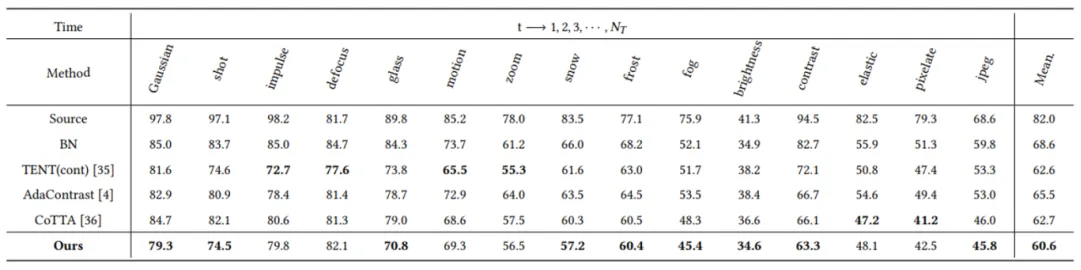
In this paper, Gaussian noises with variances of 0.03, 0.06 and 0.09 are added to each image in the target domain to test the robustness of the method against strong noise. The classification error rates (%) on the CIFAR-10C and CIFAR-100C datasets are obtained.
5 Summary and Prospects
In this paper, we propose a set of methods to improve Continual Test-Time Domain Adaptation, including soft Taylor cross entropy, uncertainty-based noise reweighting, and soft ensemble negative learning. These methods aim to address several key issues in traditional CTTDA methods, such as the overfitting of models on low-confidence categories, the impact of noise samples, and the challenges posed by label noise. Experimental results show that the proposed method significantly improves the robustness and classification precision of the model on multiple public datasets, and proves its effectiveness and wide applicability in CTTDA tasks.
In the research process, this paper uses MindSpore Deep Learning Framework for model construction and training. MindSpore provides a solid technical guarantee for research due to its efficient computing capability, flexible programming interfaces, and good support for heterogeneous hardware. The automatic parallel acceleration technology of MindSpore can also greatly improve the efficiency of model training.
We recommend that MindSpore developers make full use of its powerful capabilities and flexible interfaces to explore more efficient model training and inference methods. The MindSpore community is developing rapidly. We hope that developers can actively participate in community communication, share experience and achievements, and jointly promote the development of MindSpore.