Idea Sharing: MindSpore-Powered Implementation of Distributed Parallelism for Complex Numbers
Idea Sharing: MindSpore-Powered Implementation of Distributed Parallelism for Complex Numbers
Background
Distributed training is a commonly used method in the field of artificial intelligence, which involves distributing the model training process across multiple compute devices such as CPUs, GPUs, or Huawei NPUs, and is used for training large-scale deep learning models. As the data volume increases, a single compute node may face challenges in processing massive data sets and achieving faster training speeds. As a result, distribution becomes essential for training large-scale models.
MindScience, an AI scientific computing submodule in MindSpore, is playing an important role in many scientific fields. Regarding APIs, AI scientific computing involves some unique operators in the NumPy or SciPy library, including those for linear algebra, fast Fourier transform, and interpolation. Numerous operators in these modules necessitate handling complex data types. From a scenario standpoint, complex numbers are also frequently used in AI scientific computing, such as in electromagnetics and quantum mechanics, where they are used to represent properties of waves and fields. However, in most conventional AI applications such as image recognition, natural language processing, and sound recognition, input data (such as image pixel values, text encodings, and sound wave amplitudes) are typically represented solely by real numbers. Complex numbers are not necessary for representing data in these applications, and the AI frameworks tend to meet more widely encountered needs. Therefore, current mainstream neural network structures and learning algorithms primarily rely on real numbers. Optimization of complex numbers is not as comprehensive and efficient as that of real numbers, failing to meet the requirements for complex numbers in AI scientific computing scenarios. At present, the industry's support for complex numbers is in its nascent stages of development. This blog discusses the pain points of supporting complex numbers from the perspective of distributed parallelism, and proposes three solutions while analyzing their feasibility.
1. Analysis of Pain Points for Implementing Complex Number Distribution
In distributed training, there are certain challenges within the industry pertaining to complex numbers. In a parallel process, data communication and aggregation across different compute nodes are frequently required, in which communication operators are responsible for synchronizing model parameters and aggregating gradients across these compute nodes. The current common communication libraries used in the industry, such as NVIDIA Collective Communications Library (NCCL) and Huawei Collective Communication Library (HCCL), do not support complex numbers. This poses a significant challenge when it comes to enabling the distribution feature of complex operators.
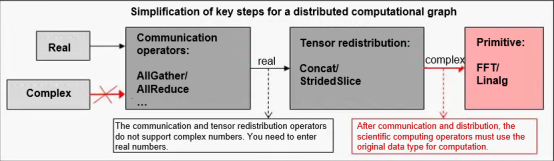
Figure 1 Simplified complex number distribution process
1.1 Communication Operators
During distributed training, the primary challenge lies in effectively processing and coordinating data and computations across multiple compute nodes. Distributed training involves partitioning large-scale datasets and distributing them to different compute nodes, which requires cooperation between nodes through synchronous and asynchronous computations. Synchronous computation requires that all nodes must wait for other nodes to complete their current computing tasks before moving on to the next step, ensuring consistency and integration of data in each step. However, this approach may cause delays in the overall training process due to slower nodes.
To improve efficiency and shorten training time, distributed training often adopts an asynchronous approach where each compute node independently performs computation and updates parameters. Although asynchronous computation can significantly accelerate the training process, it may also introduce inconsistency in parameter updates. This requires the design of synchronization mechanisms to ensure global consistency and training stability. Communication operators are a set of specially designed tools for efficiently transmitting data and synchronizing information across compute nodes. Both NCCL and HCCL contain some common communication operators.
(1) AllReduce: sums up the input tensors and produces identical output values across all involved cards.

Figure 2 AllReduce example
(2) AllGather: concatenates dimension 0 of the input tensors and produces identical output values across all involved cards.
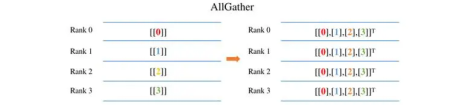
Figure 3 AllGather example
(3) ReduceScatter: sums up the inputs, splits the data along dimension 0 according to the number of cards, and distributes the data to the respective cards.
(4) Broadcast: broadcasts the input of a card to other cards. This operator is usually used for parameter initialization.
In distributed processes, communication operators are indispensable. Current mainstream communication operators lack support for the complex data type, potentially hindering model parallelism in upper-level models that use scientific computing operators and impacting both the model size and inference efficiency.
1.2 Tensor Redistribution
MindSpore has integrated the tensor redistribution technology into its parallelism policy search, which allows the device layout of output tensors to be transformed before being input to subsequent operators. After a tiling policy is configured for operators, sharding and modeling are applied to tensors at the distributed operator level. According to the tiling policy, the distributed operator defines a method for deducing the distribution model of the input and output tensors of operators.
The distributed operator further determines whether to insert additional computation and communication operations into the computational graph based on the tensor distribution model to ensure that the operator compute logic is correct. Tensor redistribution involves tensor sharding and aggregation, which primarily utilize the StridedSlice and Concat operators. Additionally, it necessitates communication across different compute nodes, and this is handled by the AllGather communication operator. To support complex numbers in distributed processes of MindSpore, the support for complex numbers in operators involved in tensor redistribution also needs to be considered.
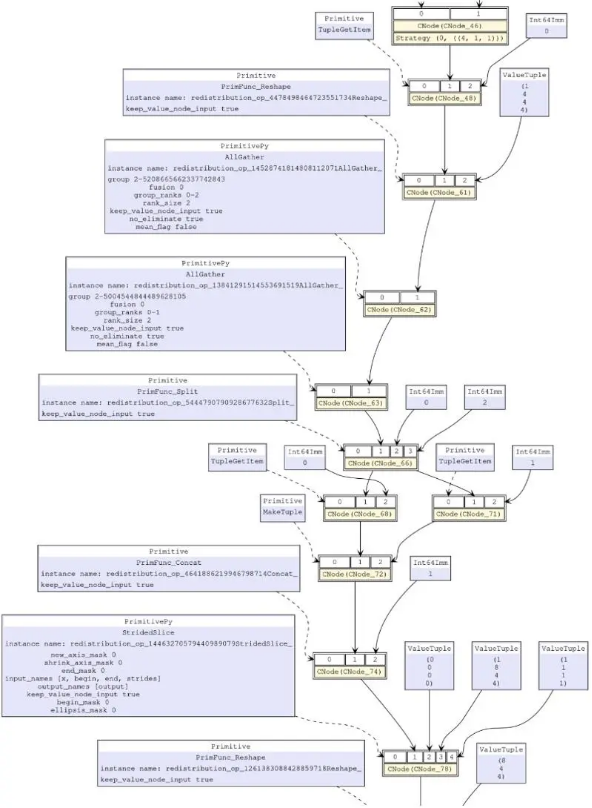
Figure 4 All operators added during a tensor redistribution
2. Possible Solutions
2.1 Adding Complex Data Types to HCCL
When a data type is not supported by operators, the most effective solution is to enable the operators' support for the data type. Specifically in this scenario, enable the communication and redistribution operators to support the complex data type. This may seem like the simplest solution, but when adding support for a data type that is not defined in a constructed framework for a particular operator, the framework's support for that type needs to be considered first. This may require modifications throughout various parts of the framework. For example, both NCCL and HCCL do not support the complex type. Adding support for the complex type requires more than just intuitive work. It is necessary to consider whether adding this support in a communication library is appropriate and reasonable; whether adding this support affects the existing support for real numbers and brings extra overheads to real number scenarios; and whether operator-level modifications need to be made for other operators involved in tensor redistribution. When considering the support for the complex data type, it is important to recognize that complex numbers are only applicable to a few specific application scenarios and are not universally applicable to typical AI training scenarios.
2.2 Changing the Call Type When Calling Communication Operators in an AI Framework
It must be clarified that if there is no intention to support complex numbers directly in communication libraries, then finding ways to accommodate complex numbers within the framework becomes a necessary approach. For reference, other frameworks utilize the view_as_real function to convert Complex64 tensors into Float32 tensors in communication operators prior to executing actual operations. If the shape of the original complex tensor is [x, y, z], it changes to [x, y, z, 2] after the conversion. That is, a dimension whose size is 2 is added to the end of the tensor, the length of the data type is halved, and the size of the occupied memory space remains unchanged. The reason why this operation is possible is due to the inherent characteristics of Complex64.
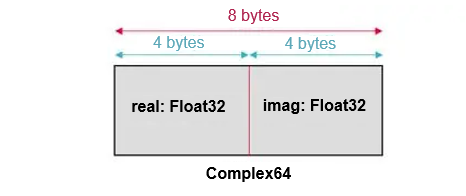
Figure 5 Comple64 memory usage example
According to simple mathematical knowledge, a complex number is actually a compound of two real numbers, one representing the real part and the other representing the imaginary part. For Complex64 data, the real and imaginary parts are represented by two Float32 data values. In memory distribution, the real and imaginary parts of each imaginary number are arranged adjacently, with the two Float32 data values forming a complex number with a length of 64. That is to say, a Complex64 tensor with a shape of [x, y, z] can actually be viewed as a tensor of type Float32 with a shape of [x, y, z, 2], where the additional dimension of 2 corresponds to the mapping of a Complex64 value to two Float32 values. Since there is no actual conversion happening, but only a change in the way tensors are viewed, the conversion function for this method is called view_as_real.
Furthermore, it should be noted that the majority of communication operators, including widely utilized ones such as AllGather, as well as other operators like Broadcast, NeighborExchange, and AlltoAll, and all redistribution operators, are solely responsible for data movements and replications, without engaging in any data computations. Theoretically, operators of this type merely require the initial data address that needs to be operated on each compute node, the length of the unit data (either 4 bytes, 8 bytes, or 16 bytes), and the quantity of unit data pieces to be processed (or the final data address) for computation. Communication operators do not have to be cognizant of the specific data type, whether it is treating a certain 64-bit data as Int64, Float64, or Complex64, it can execute the identical operation.
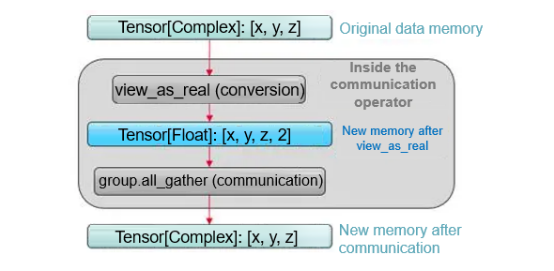
Figure 6 view_as_real conversion logic for communication operators
After comprehensive consideration, this solution can be implemented as follows: Check the tensor type before calling communication operators in the framework. If the tensor type is Complex64, synchronously modify the tensor shape (add a dimension with a size of 2 at the end) and type (change to Float32), and pass the modified output to the communication or tensor redistribution operators. Several details need to be considered when this solution is implemented in MindSpore. For example, in MindSpore, tensor information is defined and stored in related Info. Since we cannot interfere with other normal calls, the challenge lies in modifying only the content passed to communication and tensor redistribution operators, without changing the tensor information itself. Second, the shape and type information of tensors are not always integrated during modification and transmission. During solution implementation, ensure that the shape and type change at the same time. Failure to do so can lead to severe issues. Moreover, the modification is only made to the tensor information. Ensure that the memory is not modified. Failure to do so can lead to additionally memory and time overheads.
We also explore ways to enable support for complex numbers in communication operators such as AllReduce, which are frequently called for computations. For the sum operation on complex numbers, the addition logic involves separately adding the real and imaginary parts. After Complex64 is converted into Float32, the real and imaginary parts are stored alternately. As a result, direct addition yields identical results. But for more complex operations, such as maximum/minimum or product computations, it is unclear where to begin. In frameworks of competitors, these complex operations are not supported. How to support more types of AllReduce operations is a more complex problem.
The advantages and disadvantages of this solution are obvious. Since no modification is made to the memory, there is no additional runtime overhead imposed on the program. However, the stability and maintainability of the solution are also significant issues that cannot be ignored. The feasibility of implementing this solution needs to be carefully considered.
2.3 Adding Type Conversion Operators to Processing Flows
The concept behind solution 3 is essentially identical to that of solution 2; however, the implementation specifics vary significantly. In solution 2, the labeled type of data passed to communication or redistribution operators differs from the actual type of data, which introduces certain uncertainty. But if we display the conversion operation explicitly, namely adding a type conversion operator before the communication operator and including a type conversion-back operator after the communication ends, we can ensure that the input of each operator on the computational graph matches the output of the previous operator correctly. We have enhanced MindSpore by introducing the view_as_real and view_as_complex operators, modifying the computational graph, and inserting view nodes. This approach ensures that the entire tensor redistribution process uses the Float32 type for computations. Upon completion of computations, the data type is converted back to Complex64 before being handed over to scientific computing operators.
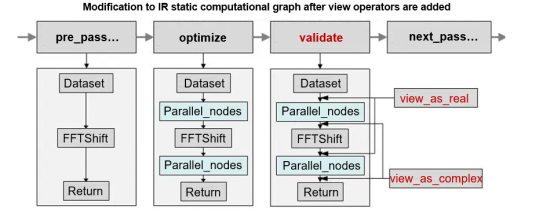
Figure 7 IR graph modified after parallel communication
Due to the specific features of MindSpore, computational graphs are sorted and compiled from the backend C++ side when static graphs are employed, which makes it impossible to implement or modify the solution on the Python or user side, as it can only be modified synchronously on the backend C++ side. This introduces some problems and challenges. Making modifications in the backend require tracing back to the insertion of communication and tensor redistribution operators for distribution in the backend of the MindSpore framework, and ensuring the coherence and consistency of the computational graph before and after the modification without affecting other optimizations and accelerations. A deep understanding of the framework's parallel process at the code level is also required, so the level of difficulty is comparable to that of reconstruction.
The impact of view operators on efficiency must also be considered. Tensor redistribution of MindSpore may call numerous and intricate operators, with multiple communication and distribution operators connected. As a result, it is important to minimize the insertion of view operators. This problem can be considered from two perspectives. If the start and end nodes of tensor redistribution can be quickly located, and view class operators can be inserted before and after the start and end nodes respectively, the number of inserted operators can be greatly reduced. This makes the process of finding the start and end nodes a major challenge. Alternatively, when performing node fusion, if the current and subsequent nodes do not involve any computation, the positions of the view class operators can be adjusted. When view_as_real and _view_as_complex appear in pairs, they can be eliminated (equivalent to a pair of inverse operations). In this case, pay attention to how to move and adjust operators.
Currently, both solutions 2 and 3 are under development, and it is expected that the distributed function of complex operators will be deployed in MindSpore soon for developers to use.
3. Summary
The primary obstacle facing scientific computing operators in terms of distribution is the need to accommodate complex data types. Complex numbers are of significant importance in scientific computing, particularly in key operators such as linear algebra and Fourier transform. The current mainstream communication libraries (such as NCCL and HCCL) do not support complex data types, which has become a critical pain point for using scientific computing operators to support the distributed function. This blog explores three methods to support the distributed function of complex types in scientific computing operators within the MindSpore+HCCL environment. These methods include directly integrating complex support in HCCL, modifying the call type for communication operators within the AI framework, and adding type conversion operators to the processing flow. They serve as valuable insights and references for enhancing AI scientific computing support.