How Does MindNLP Adapt to SOTA Models So Fast?
How Does MindNLP Adapt to SOTA Models So Fast?
March 12, 2024
Author: Lv Yufeng | Source: Zhihu
On February 21, Google released Gemma, a new generation of lightweight open source models. Gemma is built from the same technology used to create Gemini models and comes in two sizes, 2B and 7B, containing 2 billion and 7 billion parameters respectively. Each size is released with pre-trained and instruction-tuned variants.

On the very next day, as people were excitedly discussing Google's unexpected release, the MindSpore community announced that MindSpore had been adapted to Gemma.
In the AI field, the mainstream R&D approach is based on the GPU and AI framework. The framework's ability to adapt to state-of-the-art (SOTA) models is a crucial factor for developers when selecting a framework.
So, how does MindSpore adapt to SOTA models so fast in one day?
Dynamic Graph of MindSpore
When MindSpore was first open-sourced, the framework chose the static graph approach to fully utilize the computing power of Ascend hardware. Back then no one would have known that usability is even more important than performance. Until the release of MindSpore 2.0, dynamic graphs were not paid much attention to and were used for debugging only. They would be converted to static graphs for execution. However, as time goes by, static graphs will eventually become history. We need to keep catching up with the rapid development of large language models. So, it is better if we adopt dynamic graphs as soon as possible.
Through iterations, MindSpore has formed a nearly complete dynamic graph solution.
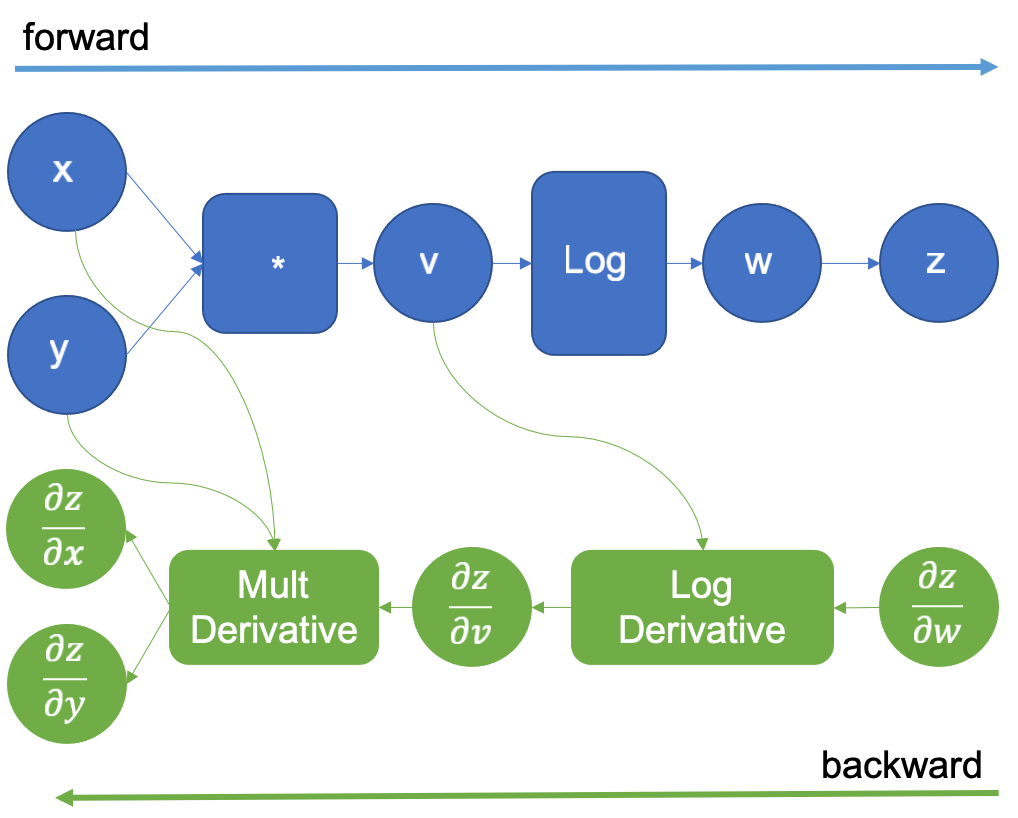
Computational graph of f(x, y) = log(x*y)
Take a simple function f(x, y) = log(x*y) as an example. The forward execution requires two operators, mul and log. The backpropagation uses the chain method for differentiation.
Current deep learning frameworks provide automatic differentiation (Autograd) to perform backpropagation (in green). Users need only to focus on the forward execution logic and ensure that the forward propagation chain is not broken. This brings the following requirements to the framework:
· No syntax restriction. (Static graphs always come with syntax restrictions.)
· Flexibility. Various Python libraries are often used.
· Good performance. (Ultimate performance is not needed.)
At this time, it seems that static graphs are incompetent. It has been a controversial topic about whether MindSpore should abandon its technology stack built on static graphs. In fact, most frameworks in the industry have completely ditched static graphs. However, any large-scale system always carries a burden during evolution. Whether the burden can be turned from an encumbrance to a driving force depends on the capability of the R&D personnel.
MindSpore chooses to reuse the existing capabilities of static graphs as much as possible to retain performance advantages.
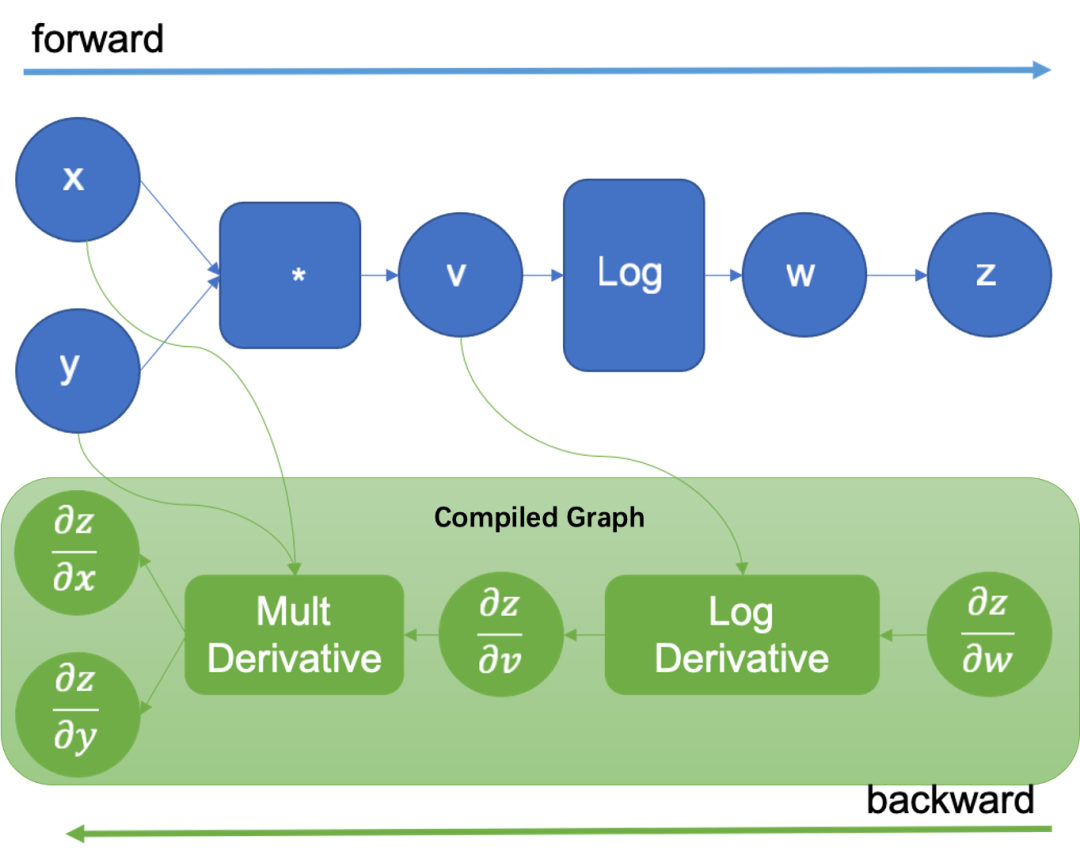
Example of a forward dynamic graph with a backward compiled graph
For framework users, there is always a trade-off between usability and performance. However, analysis found that the usability or flexibility required by users is mostly in the blue part, that is, forward execution. As backpropagation is invisible to users, a different method can be used. Therefore, MindSpore's dynamic graph solution chooses to combine Eager execution for forward calculation and compiled graphs for backpropagation. This brings the following benefits:
· User-friendliness and easy debugging
· Training performance advantage preservation
Although the operator granularity of MindSpore is very small due to the early automatic parallel design and the kernel by kernel execution speed is low, backpropagation using compiled graphs still matches or outperforms PyTorch in terms of speed. On the other hand, PyTorch is also adopting static graphs. In the end, the frameworks are all moving towards the combination of dynamic and static graphs.
Easy-to-Use APIs
Based on a proper architecture design, the next step is to "spoil" the users. Developers are already used to the APIs of other frameworks. Naturally, the best approach is to adopt the same APIs. Of course, some may question whether the APIs are really designed and developed by MindSpore or why MindSpore should be used when the APIs are the same. Also, as the APIs of other frameworks are directly used, it is difficult to decide which to keep or discard.
An AI framework typically contains the following types of APIs:
· Network construction APIs, including nn and ops
· Self-developed automatic differentiation APIs
· High-level encapsulation trainer APIs
· Self-developed dataset APIs
Although the core technologies are self-developed, the APIs should be compatible with other frameworks. You can see the mapping between MindSpore APIs and those of PyTorch at https://www.mindspore.cn/docs/en/r2.2/note/api\_mapping/pytorch\_api\_mapping.html. This is the basis for quick model migration.
MindNLP Fully Embraces Hugging Face
With matched APIs, models can be quickly migrated and adapted. However, the validity and user experience consistency also determine whether developers are willing to use the framework.
MindNLP chooses to fully embrace Hugging Face. Actually, the MindSpore community once considered directly contributing to the Hugging Face community but gave up eventually. Instead, MindNLP tries to interconnect to the largest AI community. The strategies of MindNLP are as follows:
· Goes all in on dynamic graphs.
· Fully adapts to major development libraries of Hugging Face, such as Transformers, PEFT, and TRL.
· Directly uses the datasets library and combine the library with MindSpore Dataset for the completeness of datasets.
· Uses Hugging Face test cases to test MindSpore.
These four strategies allow MindNLP to deeply interconnect with the Hugging Face community and leverage community resources to develop the ecosystem of MindNLP and MindSpore. This also meets the requirements on usability, data, and model.
MindNLP uses come tricks to adapt to Hugging Face, such as:
· Direct loading of checkpoint files without conversion
· Hugging Face model download through HF-Mirror and automatic loading using AutoModel
· Memory map data loading using the Arrow format
MindSpore community developers have migrated and adopted more than 60 models. A single model can be migrated (passes all Hugging Face unit tests) within one hour.
Community contributors
Summary
Dynamic graphs make model adaptation easy, but a framework cannot depend only on dynamic graphs.
Finally, for any required functions, feel free to submit issues to the community (https://github.com/mindspore-lab/mindnlp).