GhostNetV2, a New SOTA for Device-Tailored Small Model Performance
GhostNetV2, a New SOTA for Device-Tailored Small Model Performance
Author: Wang Yunhe Source: Zhihu
Paper:
https://arxiv.org/abs/2211.12905
Code Implementation on MindSpore:
https://gitee.com/mindspore/models/tree/master/research/cv/ghostnetv2
Introduction
Edge devices, such as smartphones, have limited compute resources. When designing a model, it is important to consider not only its performance but also its actual inference speed. The Transformer model, renowned for its breakthroughs in computer vision and exceptional accuracy across various tasks, faces challenges in achieving real-time performance on edge devices due to its slower processing speed. The classical self-attention module exhibits a relatively high computational complexity, with the amount of computation increasing quadratically as the input resolution increases.
Although the mainstream local attention module (which divides an image into multiple regions and deploys attention modules in each region) has reduced the theoretical complexity, the image segmentation requires a large number of tensor shape transformation operations (such as reshape and transpose), which will result in high latency on the edge devices. For example, combining the local attention module with the lightweight model GhostNet increases the theoretical complexity by only 20%, but the actual inference latency doubles. Therefore, designing a hardware-friendly attention mechanism for lightweight small models is necessary.
DFC Attention: Attention Module Based on Decoupled Fully-Connected Layers
An attention module applicable to device-tailored small models should meet the following three conditions:
· Exceptional proficiency in modeling long-distance spatial information. Compared with convolutional neural networks, Transformer is powerful because it can model global spatial information. Therefore, the new attention module should also be able to capture long-distance spatial information.
· High efficiency in deployment. The attention module should be hardware-friendly and computationally efficient to prevent any lag in inference. Specifically, it should not incorporate any operations that are not hardware-friendly.
· Simple concept. To ensure the generalization capability of the attention module, the design of this module should be as simple as possible.
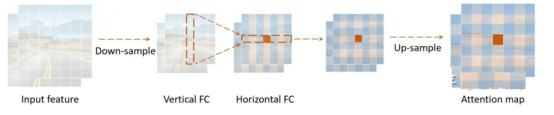
Figure: DFC attention, which captures long-distance information in both the vertical and horizontal directions.
Compared with the self-attention mechanism, the fully-connected layers with fixed weights are simpler and easier to implement, and can also be used to generate an attention map with a global receptive field. The detailed computation process is as follows:
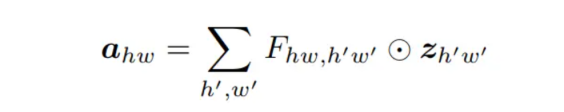
· Formula (1)
In (1), the generated feature map a is directly related to every point of the input feature, and can capture the global receptive field. However, because any two points of the input and output features are directly connected, the computation amount is also large.
In this paper, the fully-connected layer is decoupled along the horizontal and vertical directions, so two fully-connected layers are used to aggregate long-distance information in the two directions, greatly reducing the computation complexity. Such an attention module is called the decoupled fully-connected (DFC) attention.
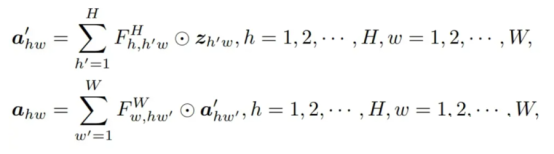
· Formula (2)
The above formulas represent the general form of DFC attention, which aggregates features in the horizontal and vertical directions respectively. This can be easily implemented with convolution by sharing some transformation weights, thereby eliminating time-consuming operations such as reshape and transpose. To process input images with different resolutions, the size of the convolution kernel can also be decoupled from the size of the feature map. That is, two depthwise convolutions with sizes of 1×K_H and K_W×1 are applied to the input feature. This strategy is well supported by deployment tools such as TensorFlow Lite and ONNX and can perform fast inference on mobile devices.
GhostNetV2:
Inserting DFC attention into the lightweight network GhostNet can improve the expressiveness capability, thus constructing a new vision backbone network GhostNetV2.
To compensate for the insufficient space dependence modeling capability of the Ghost module, this paper connects the DFC attention and Ghost modules in parallel, as shown below.
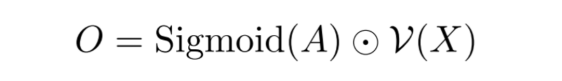
· Here, Sigmoid is the normalization function, A is the attention map, V() is the Ghost module, and X is the input data. As shown in the following figure, the final output is obtained by multiplying the features from the two branches.
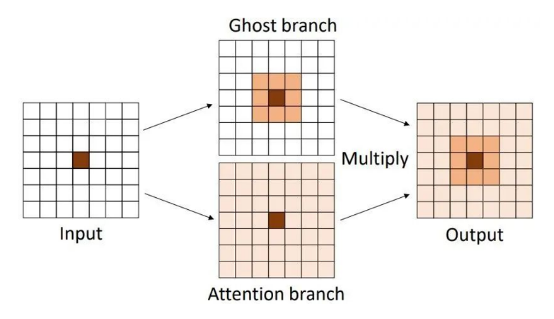
Figure: DFC attention and Ghost modules connected in parallel
To reduce the computation amount consumed by the DFC attention module, this paper downsamples the features on the DFC branch and performs a series of transformations on smaller feature maps. At the same time, this paper finds that in an inverted bottleneck structure, enhancing "expressiveness" (bottleneck intermediate layer) is more effective than increasing "capacity" (bottleneck output layer). Therefore, only intermediate features are enhanced in GhostNetV2. The following figure shows the bottleneck of GhostNetV2.
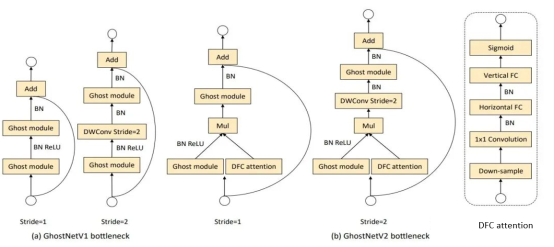
Figure: GhostNetV1 and GhostNetV2
Experimental Results
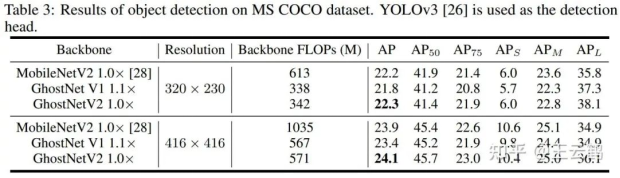
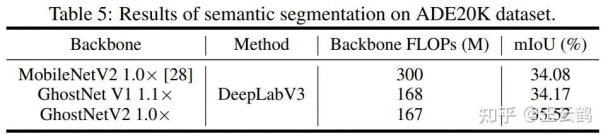
In this paper, experiments are carried out on datasets such as ImageNet (image classification), COCO (object detection), and ADE (semantic segmentation). Compared with other architectures, GhostNetV2 achieves faster inference speed and higher accuracy.
The following are the experimental results on ImageNet, which show that GhostNetV2 outperforms existing methods in terms of the theoretical computation amounts and the measured speeds on devices.
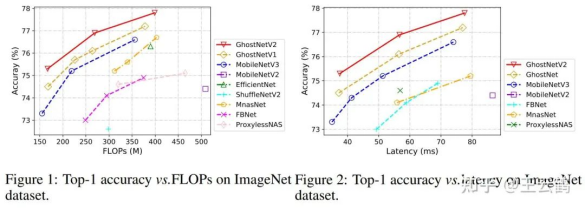
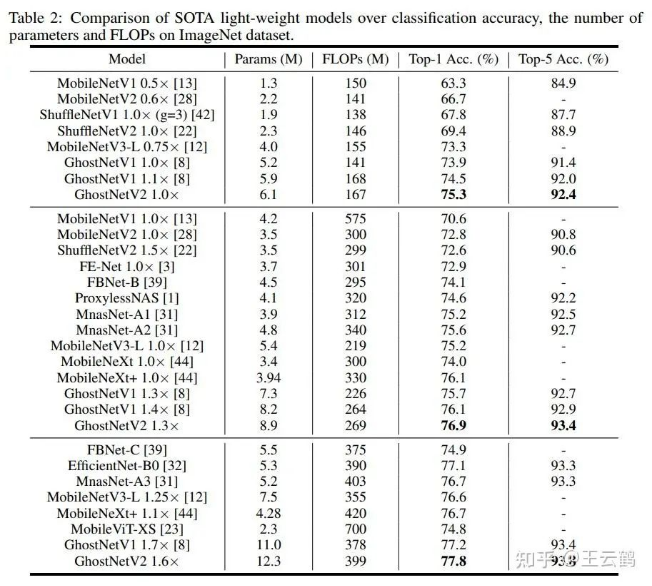
· GhostNetV2 can also be used as a backbone model for downstream tasks such as object detection and semantic segmentation. The results are as follows.