Foundation Model Learning | Transformer, an Amazing Algorithmic Model
Foundation Model Learning | Transformer, an Amazing Algorithmic Model
Author: Xiao Lifang | Source: Zhihu
Transformer, introduced by Vaswani et al. in their 2017 paper Attention Is All You Need, is a neural network structure utilized for various natural language processing tasks including machine translation, language modeling, and text generation.
1. Summary
1.1 Attention Mechanism
The attention mechanism is a technology in deep learning that simulates how human visual or auditory systems work. It draws inspiration from the perception process of humans, where selective attention is given to different parts of the input information, so that the information can be processed more effectively. This mechanism is extensively employed in deep learning for tasks like sequence data and image processing.
The basic idea of the attention mechanism is to assign different weights to information at different positions during the processing of input sequences, thereby enabling the network to concentrate more on the parts that are useful to the current task. This can improve the model's ability to handle long sequences or large-scale data, while reducing the processing complexity.
In natural language processing, the attention mechanism is typically used for tasks such as machine translation and text summarization. In image processing, it can be used for tasks such as image classification and image generation. On the basis of the attention mechanism, various variants have emerged, such as self-attention, which is used to better capture the internal dependencies within a sequence.
Specifically, the attention mechanism allows the model to assign varying weights to information at different positions during input processing, facilitating more targeted processing of input sequences. The weight allocation is dynamic and can be adjusted based on the current inputs. This ability allows the model to handle various inputs more flexibly and avoids the problem of information loss during processing of long sequences.
In natural language tasks, the importance of a word in a sentence is expressed through its attention score. A higher score indicates greater importance for task completion.
When computing the attention score, we mainly consider three factors: query, key, and value.
ž query (q): task content
ž key (k): index/tag (to help locate the answer)
ž value (v): answer
The following figure shows the relationship between q, k, and v.
In text translation, it is desired that the translated sentence conveys a similar meaning to the original sentence. As such, during attention score computation, the query is typically associated with the target sequence, namely the translated sentence, while the key is associated with the source sequence, namely the original sentence prior to translation.
There are two common methods for computing attention scores: Additive Attention and Scaled Dot Product Attention. This section focus on the second method: Scaled Dot Product Attention.
In geometry, a dot product represents the projection of one vector onto another vector. In other words, from a geometric perspective, the dot product represents how much of one vector is similar to another vector.
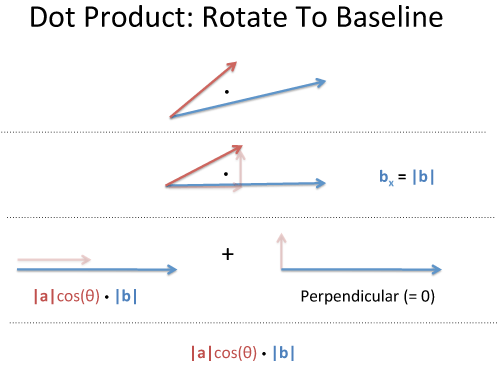
Image source: Understanding the Dot Product from BetterExplained
When applying this concept to the current scenario, we need to compute the dot product between the query and key in order to determine how much similarity exists between them.
Here is the formula of the attention mechanism:
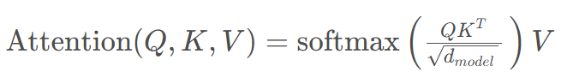
1.2 Self-Attention Mechanism
With the self-attention mechanism, we concentrate on a sentence itself, and assess the significance of each word relative to its surrounding words. This effectively clarifies the logical relationships within the sentence, including pronoun references.
For example, in the sentence "The animal didn't cross the street because it was too tired," "it" refers to "The animal", so self-attention will assign higher attention scores to "The" and "animal".
The computation of self-attention scores still follows the above formula, except that here the query, key, and value are replaced by the sentence itself, each multiplied by its respective weight.
Given a sequence 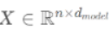 , whose length is n and dimension is
, whose length is n and dimension is 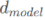 , compute the self-attention as follows:
, compute the self-attention as follows:
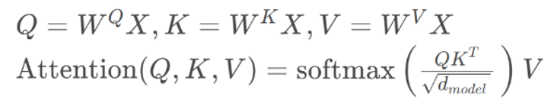
The self-attention score between the word at position i and the word at position j in the sequence is computed as follows:
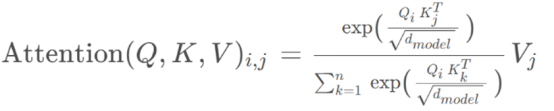
1.3 Multi-Head Attention
Multi-head attention is an extension of the attention mechanism that allows the model to attend to different parts of an input sequence in different ways, thereby improving the model training effectiveness.
Unlike the previous method of computing the attention score for the entire input, multi-head attention involves multiple computations, each of which computes the attention score for a certain part of the input sequence, and finally integrates the results.
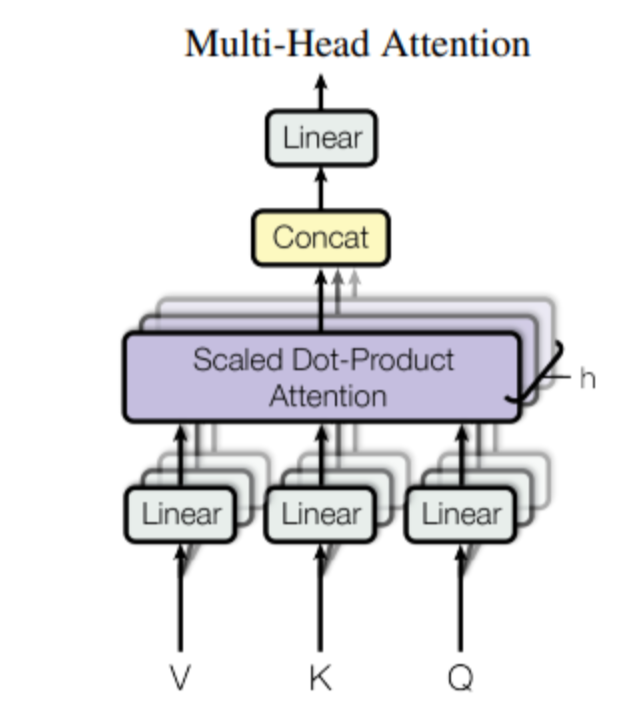
Image source: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, 2017.
Multi-head attention maps the input embeddings to multiple small-dimensional spaces by multiplying them with different weight parameters WQ, WK, and WV. Each of these spaces is referred to as a head, and each head computes its own attention score in parallel.
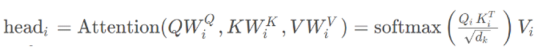
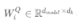 ,
,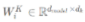
, and 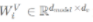 are learnable weight parameters. Generally, to balance the computation costs, we will take
are learnable weight parameters. Generally, to balance the computation costs, we will take 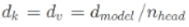 .
.
After obtaining multiple sets of self-attention scores, we combine them together to derive the ultimate output of multi-head attention. WO is a learnable weight parameter, which is used to map the combined multi-head attention output back to the original dimension.

Simply put, in multi-head attention, each head can interpret different aspects of the input content, such as capturing global dependencies, focusing on tokens in specific contexts, and recognizing syntactic relationships between words.
1.4 Transformer Structure
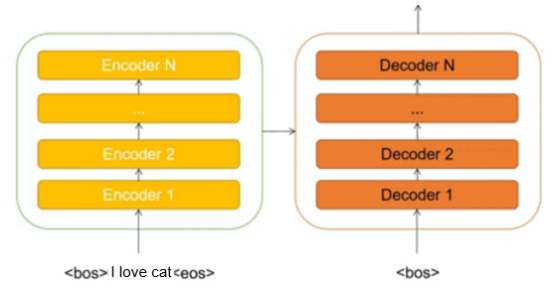
Transformer is an Encoder-Decoder structure, where the Encoder and Decoder are composed of numerous stacked encoder and decoder layers with the same structure.
For example, during machine translation, the Encoder interprets information about the source statement (sentence to be translated) and transmits the information to the Decoder. After receiving the source statement information, the Decoder predicts the next word based on the current input (translation progress) until a complete sentence is generated.
1.4.1 Positional Encoding
The Transformer model does not contain a recurrent neural network (RNN), so it cannot record timing information. As a result, the model is unable to recognize changes in sentence meaning caused by alterations to word orders, as seen in examples like "I love my cat" and "My cat loves me" in English.
To compensate for this limitation, we opt to incorporate positional encoding to provide essential positioning information to the input data.
The shape of the positional encoding P E PEPE is the same as the output X after word embedding. For the element whose index is [pos, 2i] and the element whose index is [pos, 2i+1], the positional encoding is computed as follows:
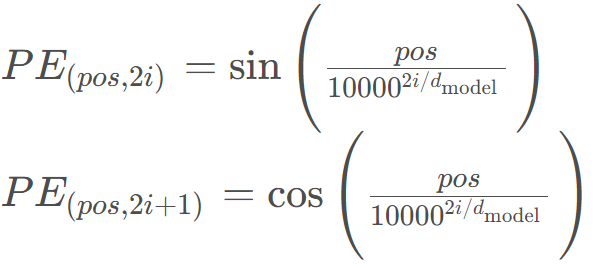
1.4.2 Encoder
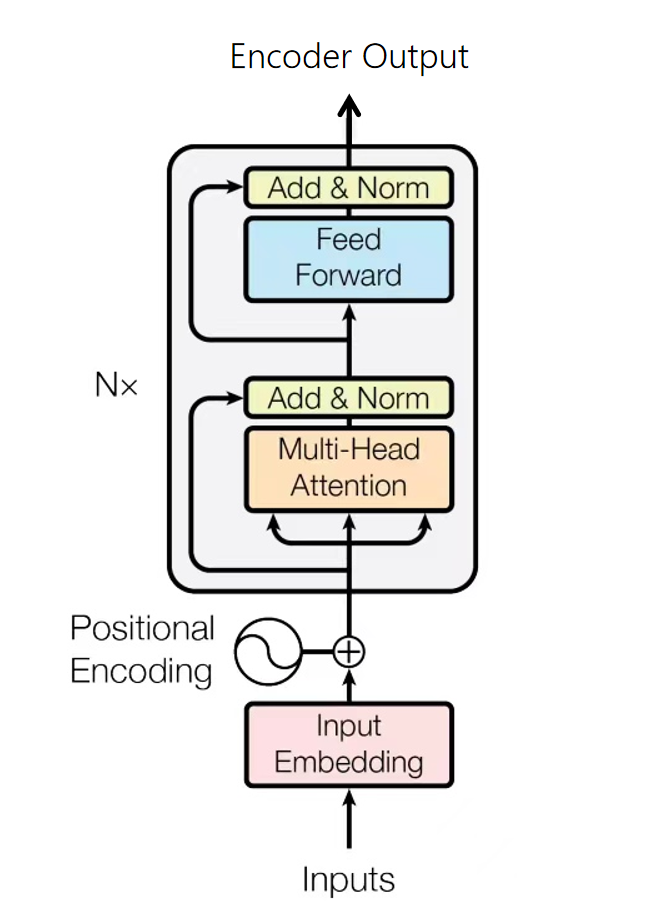
The Encoder of Transformer is responsible for processing input source sequences and integrating the input information into a series of context vectors as outputs.
There are two sublayers in each encoder layer: multi-head self-attention and position-wise feed-forward network.
The sublayers adopt the residual connection and layer normalization. They are collectively called Add&Norm.
1.4.3 Add & Norm
The Add&Norm layer is essentially a residual connection followed by a LayerNorm layer.

· Add: residual connection, which helps alleviate network degradation. Note that the shape of x must be the same as that of SubLayer(x).
· Norm: Layer normalization, which facilitates faster model convergence.
1.4.4 Decoder
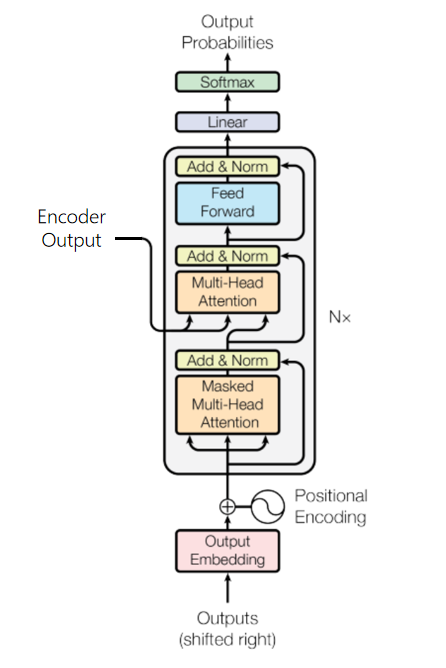
The Decoder converts the context sequences output by the Encoder into prediction result 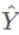 of the target sequence, which will be compared with the true target output Y in model training to compute the loss.
of the target sequence, which will be compared with the true target output Y in model training to compute the loss.
Unlike the Encoder, each decoder layer is composed of two layers of multi-head attention mechanism, followed by an additional linear layer that outputs the predicted result for the target sequence.
- Layer 1: masked multi-head self-attention for computing the attention score of the target sequence.
- Layer 2: used to compute the mapping between the context sequence and the target sequence. The output of the Decoder's masked multi-head self-attention is used as the query, and the output (context sequence) of the Encoder is used as the key and value.
2. Practice
Use Transformer to implement text machine translation.
E2E Process
Data preprocessing: Process data such as images and text into tensors that can be computed.
Modeling: Use framework APIs to build a model.
Model training: Define the model training logic, and traverse the training dataset for training.
Model evaluation: Use the trained model to evaluate the effect on a test dataset.
Model inference: Deploy the trained model and input new data to obtain the prediction result.
There is a large amount of code in the experiment. The focus is on modeling here.
Modeling
Define hyperparameters and instantiate the model.
src_vocab_size = len(de_vocab)
trg_vocab_size = len(en_vocab)
src_pad_idx = de_vocab.pad_idx
trg_pad_idx = en_vocab.pad_idx
d_model = 512
d_ff = 2048
n_layers = 6
n_heads = 8
encoder = Encoder(src_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
decoder = Decoder(trg_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
model = Transformer(encoder, decoder)
Model Training and Evaluation
Model Training Logic
MindSpore uses functional programming (FP) in model training.
Construct a function -> Transform the function -> Call the function
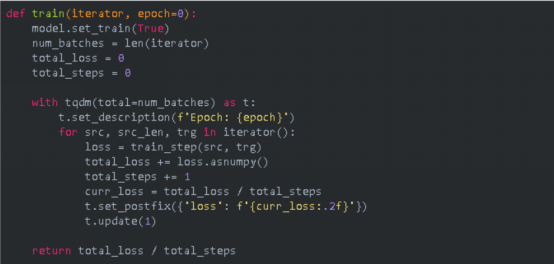
Define the model evaluation logic.
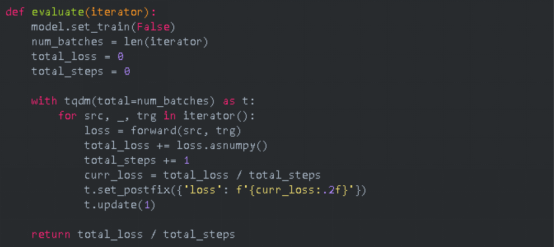
Model Training
Traverse and iterate the dataset. A complete dataset traversal forms an epoch. We print the training loss and evaluation accuracy for each epoch, and use save_checkpoint to save the CKPT file (transformer.ckpt) with the highest evaluation accuracy to home_path/.mindspore_examples/transformer.ckpt.
from mindspore import save_checkpoint
num_epochs = 10
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'transformer.ckpt')
for i in range(num_epochs):
train_loss = train(train_iterator, i)
valid_loss = evaluate(valid_iterator)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
save_checkpoint(model, ckpt_file_name)
Model Inference
Take the first group of sentences in the test dataset as an example.
example_idx = 0
src = test_dataset[example_idx][0]
trg = test_dataset[example_idx][1]
pred_trg = inference(src)
print(f'src = {src}')
print(f'trg = {trg}')
print(f"predicted trg = {pred_trg}")

3. Reflections
The integration of the attention mechanism into Transformer marks a significant innovation. Compared with a conventional RNN or a long short-term memory network (LSTM), Transformer adopts the self-attention mechanism that enables the model to better propagate information when processing long sequences. By assigning different weights to information at different positions in input sequences, Transformer performs well in tasks such as language modeling and machine translation.
The multi-head attention mechanism enables the model to focus on different subspaces at the same time, which further improves the model's learning ability. This parallelism design enables Transformer to perform well in processing large-scale data and better capture local and global dependencies in sequences.
Additionally, the introduction of positional encoding addresses the issue of Transformer's inability to handle sequence order information. By embedding positional information into input data, Transformer can better understand the relative positions of elements in sequences, which is crucial for tasks such as language translation that require consideration of word orders.
The course also delves into the training process of Transformer, including Add&Norm, residual connections, and other techniques. The application of these techniques makes Transformer easier to train and widely applicable to different types of data and tasks.
In general, Transformer is a highlight in this deep learning course. The innovative design of this model and its outstanding performance in practical tasks have greatly demonstrated the continuous progress in the field of neural networks, and have filled developers with confidence in the future of deep learning. Transformer is not only a model, but also a significant innovation in the neural network structure, providing new ideas and tools for tackling complex tasks.