MindSpore-based Accelerate Adversarial Training Algorithm Reducing Training Time Significantly
MindSpore-based Accelerate Adversarial Training Algorithm Reducing Training Time Significantly
Paper title:
Accelerate Adversarial Training with Loss Guided Propagation for Robust Image Classification
Source:
Information Processing & Management
URL:
https://www.sciencedirect.com/science/article/pii/S0306457322002448
Code URL:
https://gitee.com/chunjie-zhang/atlgp
As an open source AI framework, MindSpore supports ultra-large-scale AI pre-training and brings excellent experience of device-edge-cloud synergy, simplified development, ultimate performance, and security and reliability for researchers and developers. Since it was open-sourced on March 28, 2020, MindSpore has been downloaded for over 6.57 million times. It has also been the subject of thousands of papers presented at premier AI conferences. Furthermore, it has a large community of developers and has been introduced in over 290 top universities and 5,000 commercial applications. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumers, and smart automobiles, MindSpore has emerged as the leading open source software on Gitee. Here in this open source community, you are welcome to make contributions such as development kits, idea pooling for modeling, industry innovations and applications, algorithm innovations, academic collaborations, AI book collaborations, and your own application cases in the cloud, device, edge, security fields, and more.
Thanks to the support from scientific, industry and academic circles, MindSpore-based papers account for 7% of all papers based on all AI frameworks as of 2023, ranking No. 2 in the world for two consecutive years. The MindSpore community supports analysis on top-level conference papers and promotes original AI achievements. In this blog, we are going to share the paper by Prof. Zhang Chunjie and his team from the Institute of Information Science at Beijing Jiaotong University. This paper is published on Information Processing & Management.
1. Background
Deep learning models have achieved good performance in the computer vision field. However, researches show that deep learning models are vulnerable to adversarial examples in both the digital and physical worlds, threatening the security of deep learning models during large-scale applications. As one of the most effective defense methods, adversarial training significantly improves the performance of deep learning models in adversarial environments. However, because a large amount of computing resources is required to generate adversarial examples as training data, the existing adversarial training algorithm faces a problem of low computing efficiency.
2. Team Introduction
Xu Changkai, the first author of the paper, graduated in 2023 with a master's degree from the School of Computer and Information Technology at Beijing Jiaotong University. His research focuses on adversarial attack algorithms.
The Center of Digital Media Information Processing (MePro) at Beijing Jiaotong University started in 1998 and was recognized under the Innovation Team Development Plan of the Ministry of Education in 2012. MePro consists of 14 teachers and more than 100 master's and PhD students. Its research primarily revolves around digital media information processing, including image/video coding and transmission, digital watermark and forensics, and media content analysis and understanding. In 2022, the lab made significant contributions to the field by publishing 61 high-impact papers, including 38 papers in the esteemed international journal IEEE Trans and 23 papers presented at top-tier international conferences like NeurIPS, CVPR, ECCV, and ACM MM.
3. Introduction to the Paper
The idea of adversarial training is to introduce adversarial examples into training data to improve the performance of deep learning models under adversarial attacks. Adversarial training is one of the most effective active defense methods. However, the existing adversarial training algorithm requires a large amount of computing resources to generate adversarial examples, causing poor model training efficiency. To solve the problem, this paper proposed an accelerated adversarial training algorithm with loss guided propagation.
When generating adversarial examples, this algorithm uses loss functions as the guide to automatically control the number of gradient propagations of each training instance in different training phases. This effectively reduces the calculation workload while ensuring the model performance. In addition, this algorithm has good generalization ability and can be combined with existing accelerated adversarial training algorithms, which obtains leading acceleration effects when there are high requirements on model performance. Experimental results on three public datasets show that this algorithm, compared with other benchmark algorithms, can reduce the training time by 30% to 60%.
4. Experimental Results
In this paper, experiments are carried out on three public datasets: MNIST, CIFAR10 and CIFAR100. Comparison of the performance and training efficiency between the adversarial training method with loss guided propagation (ATLGP) and different benchmark algorithms are made. As well, the experimental results of AT, ATTA and ATLGP under various hyperparameter settings are provided, better showing the correlations of the performance and training time between the three methods.
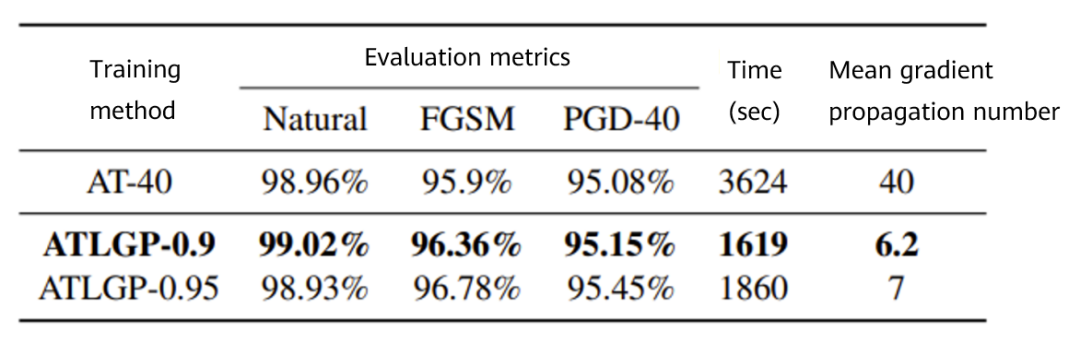
Figure 1 Performance comparison between AT and ATLGP on MNIST
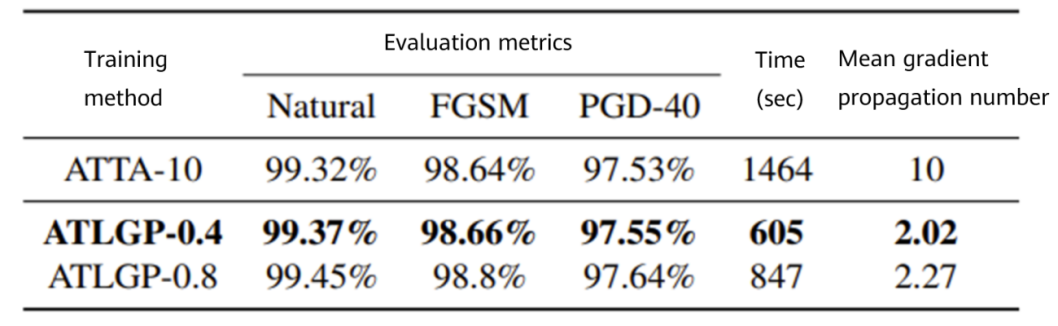
Figure 2 Performance comparison between ATTA and ATLGP on MNIST
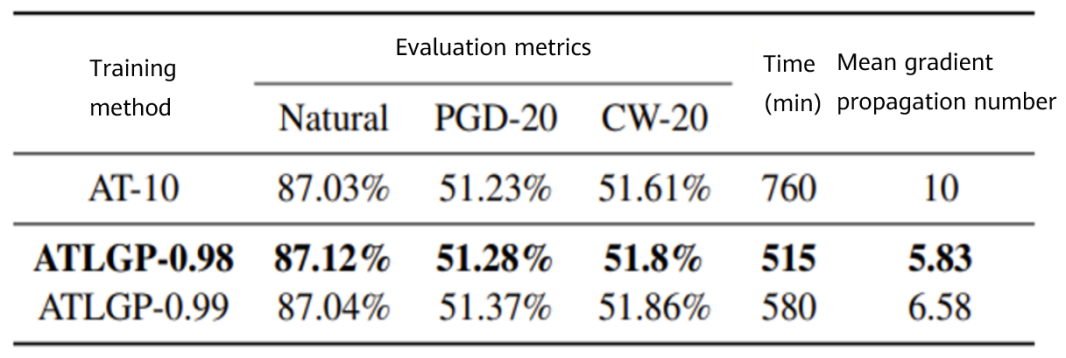
Figure 3 Performance comparison between AT and ATLGP on CIFAR10
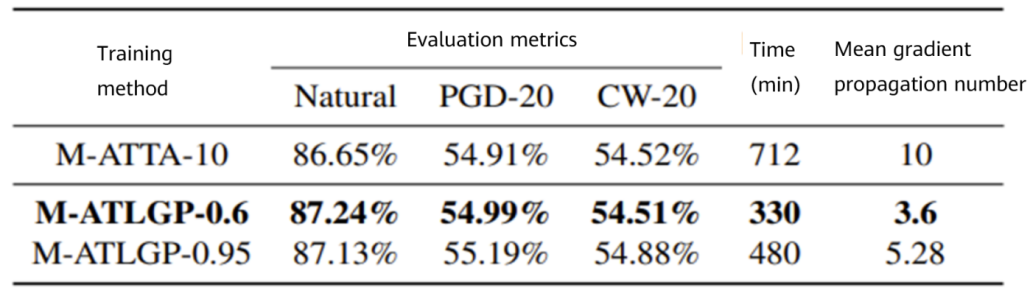
Figure 4 Performance comparison between M-ATTA and M-ATLGP on CIFAR10
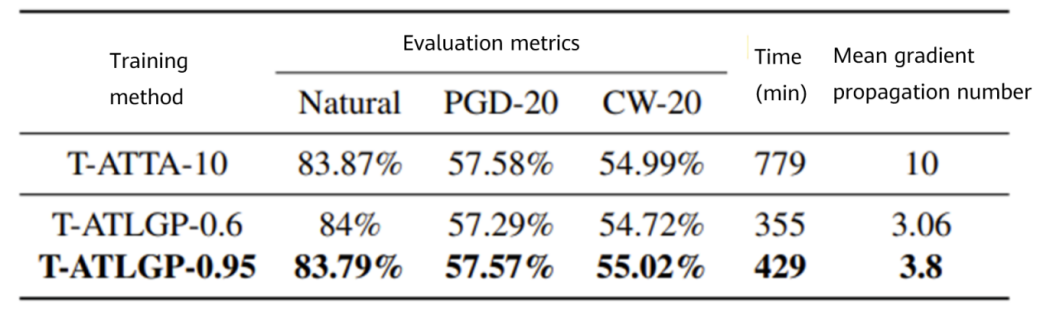
Figure 5 Performance comparison between T-ATTA and T-ATLGP on CIFAR10
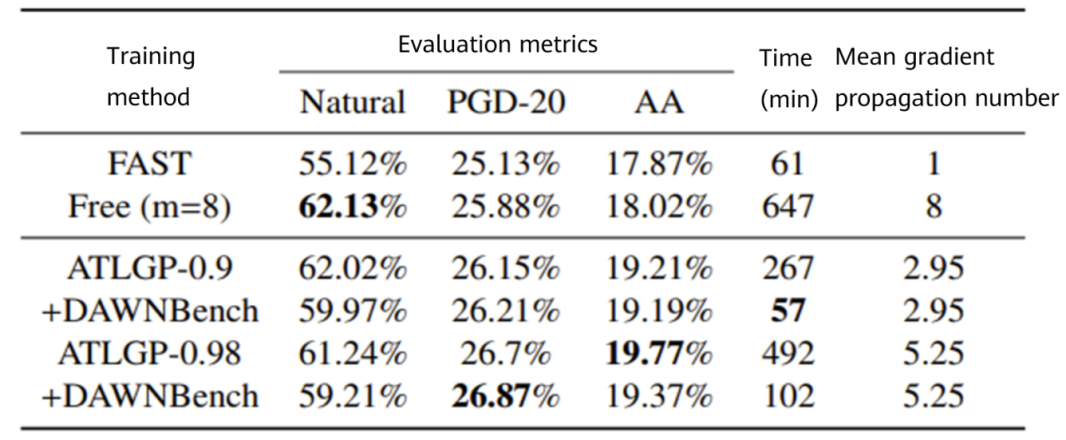
Figure 6 Performance comparison between ATLGP and other benchmark algorithms on CIFAR100
5. Summary
In this paper, ATLGP is proposed and verified its high adversarial accuracy and good acceleration effect through the experiments on three public datasets. The acceleration effect of ATLGP further proves the rationality of loss function guidance. In addition, ATLGP has good generalization ability and can be easily combined with ATTA to provide advanced acceleration performance with high adversarial accuracy. ATLGP fully considers the difference of adversarial attributes among training instance, and introduces a threshold β to quantitatively describe the local optimal solution of the inner maximization problem. Difference of adversarial attributes may exist widely in different datasets. The more complex the data distribution is, the more obvious the adversarial differences are, for example, from MNIST to ImageNet. Based on this, we can speculate that ATLGP will also have good acceleration performance on more complex datasets.