MindSpore-based Equiangular Basis Vectors Significantly Outperform Conventional Classifiers
MindSpore-based Equiangular Basis Vectors Significantly Outperform Conventional Classifiers
Author: Li Ruifeng | Source: Zhihu
Paper Title
Equiangular Basis Vectors
Paper Source
CVPR 2023
Paper URL
https://arxiv.org/abs/2303.11637
Code URL
https://github.com/msfuxian/EBV
As an open-source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open-sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumer, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends warm welcome to everyone who wishes to contribute to the development of the open-source community, suites, OpenMind projects, industry innovations and applications, algorithm innovations, academic cooperation, AI-themed book writing, and study cases in the cloud, device, edge, and security fields. Thanks to the support from scientific, industry and academic circles, MindSpore-based papers accounted for 7% of all papers about AI frameworks in 2023, ranking No. 2 for two consecutive years. The MindSpore community supports research on top-level published papers and keeps delivering original AI achievements. In this blog, I'd like to share the paper of the team led by Prof. Wei Xiushen, School of Compute Science and Engineering, Nanjing University of Science and Technology.
MindSpore aims to achieve three goals: easy development, efficient execution, and all-scenario coverage. The development of MindSpore has been characterized by rapid improvements with successive iterations, with its API design being more complete, reasonable, and powerful. In addition, various tools on MindSpore provide the ecosystem with more convenient and powerful development methods. For example, MindSpore Insight can present model architectures in graphs and dynamically monitor the changes of indicators and parameters during model running. This blog focuses on the classification of a large number of categories (for example, 100,000 or 1,000,000 categories). In this case, the last linear layer of networks such as ResNet-50 requires 2048 × 100000 or 2048 × 1000000 parameters. As a result, the number of parameters of FC is greater than that of the feature extraction layer.
In addition, the one-hot vector is generally selected as the label for classification. In other words, the angle between any two vectors is an orthogonal basis of 90 degrees. At the end of 2021, a paper published in Annals of Mathematics states that when dimension D tends to infinity, for a given angle, the number of equiangular straight lines is in a linear relationship with D (see Equiangular lines with a fixed angle).
So for perfectly equal angels with a large number of categories, the value of D must be large. According to the optimization proposed in the paper discussed in this blog, for an angle about 83–97 degrees (restricted symmetrically), 5000 dimensions can accommodate 100,000 categories without greatly impacting the classification performance. The corresponding datasets have been open-sourced. Meanwhile, for a zero-degree angle, countless basis vectors exist in the space. However, there is no fixed mathematical solutions for α, space dimensions, and the quantity of such vectors, except for some special cases. For details, you can refer to Sparse and Redundant Representations – From Theory to Applications in Signal and Image Processing. The classification task code is constructed based on the sample provided in the MindSpore official document with simple modifications, which is easy to use.
01
Research Background
The pattern classification field is designed to assign input signals to two or more categories. In recent years, deep learning models have made breakthrough progress in dealing with images, videos, audios, texts, and other data. Thanks to rapid improvement of hardware, deep learning methods can easily fit one million images and overcome the obstacle of poor quality of handcrafted features in previous pattern classification tasks. Deep learning–based methods keep emerging and are used to solve classification problems in various scenarios, such as remote sensing, few-shot learning, and long-tailed problems.
Figure 1 illustrates the paradigm of some typical classification tasks. Currently, a large number of deep learning methods use a trainable fully connected layer combined with softmax as the classifier. However, because the quantity of categories is fixed, such classifier delivers relatively poor scalability, and the number of trainable parameters of the classifier increases as the number of categories grows. For example, memory consumption of a fully connected layer W ∈ R_d×N_ linearly rises with a larger number of categories N, and the computation cost of matrix multiplication between the fully connected layer and d-dimensional features also increases accordingly. Some methods based on classical metric learning must consider all training samples and design positive/negative sample pairs, and then optimize a class center for each category. This process requires a large amount of extra computation for large-scale datasets, especially for pre-training tasks.
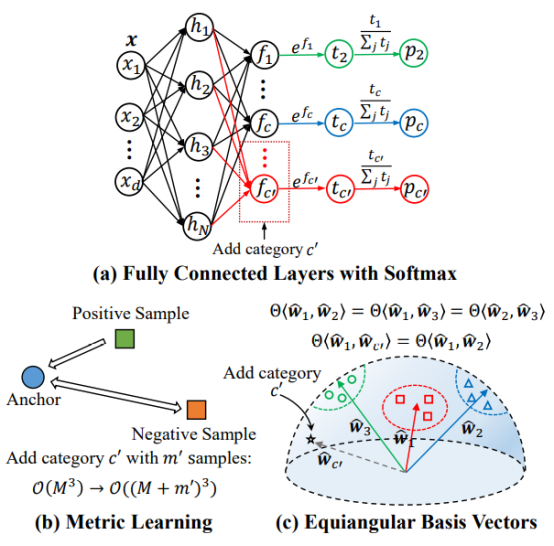
1. A general classifier ends with k-way fully connected layer and softmax. When categories are added, the trainable parameters of the classifier increase linearly.
2. Triplet embedding is one of classical metric learning methods. When M images are given, the complexity is O(_M_3). When a new category with m' samples is added, the complexity increases to O((M + m')3).
3. The proposed Equiangular Basis Vectors (EBVs) predefine fixed normalized embeddings for different categories. The trainable parameters of the network do not change with the number of categories, whereas the computational complexity increases from O(M) to O(M + m')).
02
Team Introduction
The Visual Intelligence & Perception (VIP) Group, in charge of Professor Wei Xiushen, has published more than 50 papers at internationally known conferences and journals, such as several IEEE journals, Machine Learning Journal, NeurIPS, CVPR, ICCV, ECCV, IJCAI, and AAAI. The team has also won seven world championships in computer vision-related competitions, including IGIX 2023, SnakeCLEF 2022, iWildCam 2020, iNaturalist 2019, and Apparent Personality Analysis 2016.
03
Introduction to the Paper
EBVs are proposed to replace classifiers commonly used in the classification tasks of deep neural networks. EBVs predefine fixed normalized basis vectors for all categories. The angles between every two basis vectors are equal and are constrained to be as close to orthogonal as possible to each other. Specifically, in a d-dimensional unit hypersphere, for each category in the classification task, EBVs define a d-dimensional normalized embedding on the surface of the hypersphere, which is called a basis vector. The spherical distance of each basis vector pair meets a defined rule, which makes the relationship between any two basis vectors as close as possible to orthogonal with similar angles. To keep the trainable parameters of the deep neural networks constant with the increase of the number of categories, the definition of EBVs is proposed based on Tammes Problem and Equiangular Lines.
As we know, d orthogonal basis vectors can construct a d-dimensional Euclidean space R_d_. In addition, two orthogonal vectors are not correlated in mathematics. However, such d-dimensional space accommodates a maximum of d basis vectors, that is, the number of categories to be accommodated N = d. Memory space cannot be reduced for large-scale classification. Therefore, the angle relationship between different basis vectors needs to be optimized. It is assumed that in the unit hypersphere S__d ∈ R_d_, α ∈ [0, 1), and the angle range of any two basis vectors is defined as [arccos – α, arccosα]. For the given category quantity N, find the minimum value of α that meets the requirement; or for an acceptable α, find the value range of N in the space R_d_. This is how EBVs are defined. Its mathematical expression can be summarized as finding a set of EBVs W that meets the requirement, and W satisfies:
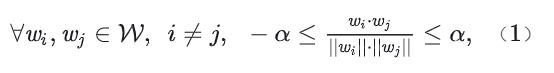
Both w__i and w__j ∈ R_d_, card(W) = N, and ||·|| represents the Euclidean norm. Φ is the spherical distance function. For any feature vector v to be queried, v ∈ R_d_, and its correlation with the basis vector w__k ∈ W can be expressed as:
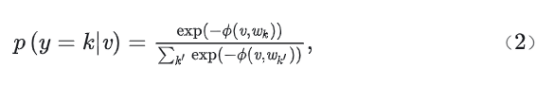
y = k ∈ {1, 2, ..., N} represents N basis vectors in the set W. k' represents associated basis vectors. Similarly, k' ∈ {1, 2, ..., N}.

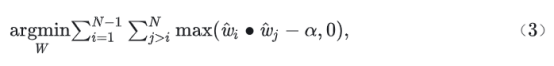


04
Experimental Result
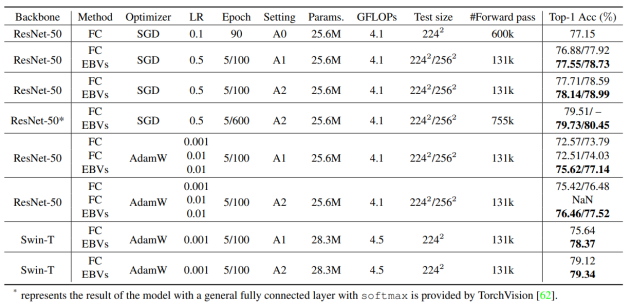
Comparison experiments are conducted in classification tasks on ImageNet-1K datasets, instance segmentation and target detection tasks in MS COCO datasets, semantic segmentation tasks in ADE20K datasets, and a large number of downstream classification tasks. Here, the classification results in the ImageNet-1K datasets are taken as an example. To prove the effectiveness of EBVs, we refer to the most advanced training method provided by TorchVision for baseline comparison. We provide three different training settings:
1. A0 indicates the training setting in the original ResNet text.
2. A1 indicates that a cosine decay learning rate scheduler and warm-up training policy are used, as well as enhancement policies such as weight decay and TrivialAugment.
3. A2 indicates that the label-smoothing, cutmix, and mixup policies are added based on A1.
As shown in Table 1, the experimental results show that EBVs greatly improve the performance compared with conventional classifiers under the same experimental settings.
Table 1 Comparisons on the ImageNet-1K validation dataset
05
Summary and Prospects
This paper proposes a new paradigm for classification tasks: EBVs. In deep neural networks, a model usually processes classification tasks using a k-path fully connected layer with softmax. The learning objective is to map the learned feature representations to the label space of samples. Whereas in the metric learning method, the learning objective can be summarized as learning a mapping function, that is, to map training data points from the original space to a new space. Sample points of the same category become closer, and those of different categories father apart. Different from the two methods, EBVs predefine a fixed normalized basis vector for all categories. During predefinition, angles between any two basis vectors are equal, and are constrained to be as orthogonal as possible to each other. In training, these basis vectors are directly used as fixed mapping objectives for different categories of samples, and the learning objective of EBVs is also changed to minimize the spherical distance of the embedding of an input between its categorical EBV. In the verification phase, because each category is fixed with a basis vector, the image label can be determined by the minimum spherical distance of the embedding of input and each basis vector. To sum up, training can be quickly completed based on the official sample code on MindSpore for classification tasks.