Generalized Federated Prototype Learning in Multi-Domain Prototype Contrastive Learning: A MindSpore Implementation
Generalized Federated Prototype Learning in Multi-Domain Prototype Contrastive Learning: A MindSpore Implementation
Author: Li Ruifeng | Source: Zhihu
Paper Title
Rethinking Federated Learning with Domain Shift: A Prototype View
Paper Source
CVPR 2023
Paper URL
Code URL
https://github.com/yuhangchen0/FPL_MS
As an open-source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumers, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers accounted for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share the paper of the team led by Prof. Ye Mang, School of Computer at Wuhan University.
MindSpore aims to achieve three goals: easy development, efficient execution, and all-scenario coverage. The development of MindSpore has been characterized by rapid improvements with successive iterations, with its API design being more complete, reasonable, and powerful. To augment its convenience and power, several kits based on MindSpore have been developed. One such example is MindSpore Insight, which can present model architectures in graphs and dynamically monitor the changes of indicators and parameters during model execution, thereby simplifying the development process.
01 Research Background
In the digital world, data privacy and security have become increasingly important issues. In this context, federated learning has emerged as a distributed machine learning method that protects data privacy. The core idea of federated learning is to train a model collaboratively across multiple devices or servers without sharing the raw data. This method can cope with machine learning tasks on multiple mobile devices, especially in situations where data privacy and security are highly demanded.
One important unresolved issue in federated learning is data heterogeneity, which typically refers to the potential for significant differences in data held by nodes (such as devices, servers, or organizations) participating in learning. These differences may involve multiple aspects of data, including the distribution, quality, quantity, and feature type. The issue of data heterogeneity is particularly important in federated learning because it may directly affect the learning performance and generalizability of a model.
This paper argues that existing solutions for data heterogeneity mainly focus on all private data from the same domain. When distributed data comes from different domains, private models can easily exhibit degraded performance in other domains (with domain shift), and the global signal cannot capture rich and fair domain information. Therefore, the authors hope that the global model optimized in the federated learning process can stably provide generalizability performance in multiple domains.
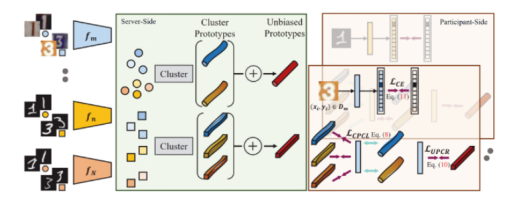
In this paper, the authors propose the federated prototype learning (FPL) under domain shift. The core idea is to construct cluster prototypes and unbiased prototypes, and provide rich domain knowledge and fair convergence goals. On the one hand, the authors bring the sample embedding closer to cluster prototypes that belong to the same semantics than cluster prototypes from different classes. On the other hand, they introduce consistency regularization to align local instances with corresponding unbiased prototypes.
The paper uses the MindSpore framework for development and experiment. Experimental results of tasks using Digits and Office Caltech can demonstrate the effectiveness of the proposed solution and the efficiency of key modules.
02 Team Introduction
Huang Wenke, the first author of this paper, is currently pursuing a joint master's and doctoral degree at Wuhan University (2021-present), and his mentors are Prof. Du Bo and Prof. Ye Mang. He also graduated from Wuhan University with a bachelor's degree. His main research directions include federated learning, graph learning, and financial technology. He has published four first-author papers at top international conferences such as CVPR, IJCAI, and ACM MM. He has worked as a research intern at Alibaba Group and Microsoft Research Asia.
Ye Mang, correspondent author of this paper, is a professor and doctoral tutor in the School of Computer at Wuhan University. His research focuses on computer vision, multimedia retrieval, and federated learning. He has published more than 80 papers in international journals and conferences, with 10 highly-cited papers in the ESI index and over 5600 citations on Google Scholar. He is also the domain-specific chairperson for several academic conferences such as CVPR24 and ACM MM23. Prof. Ye Mang has won the Google Excellent Scholarship and the championship of the unmanned aerial vehicle re-identification track at the International Conference on Computer Vision (ICCV) 2021, and was included in the World's top 2% Scientist 2011-2022 released by Stanford University.
His research team MARS focuses on studying pedestrian/behavior analysis in surveillance videos, unsupervised/semi-supervised learning, cross-modal understanding and inference, and federated learning.
03 Introduction to the Paper
3.1 Introduction
Based on the research background mentioned above, this paper introduces federated prototype learning (FPL) as a solution to the issue of federated multi-domain generalization. That is, private data is sourced from diverse domains, and clients exhibit varying feature distributions. Local models tend to overfit to these local distributions, which results in poor performance of private models in other domains. For example, if a local model A is trained on a grayscale image dataset like MNIST, it may not exhibit satisfactory performance on a client's colored image dataset such as SVHN after being aggregated on the corresponding server. This is because the local model is not able to capture the domain information of SVHN, leading to a decline in its performance.
Because global signals cannot represent knowledge information from multiple domains and may be biased towards information in dominant domains, the generalizability decreases. To enable a model to learn rich multi-domain knowledge and improve its generalizability by providing multi-domain information through common signals, this paper proposes the use of cluster prototypes to represent different domain information to enhance both the commonalities of same classes in different domains and the differences between classes. This is called cluster prototypes contrastive learning. To avoid optimization towards potential dominant domains and improve capabilities in minority domains, this paper uses unbiased prototypes to provide fair and stable information. This is called unbiased prototypes consistent regularization.
3.2 Methods
3.2.1 Preparation
Federated Learning
In a typical federated learning setting, there are M participants and their corresponding private data, which are expressed as follows:
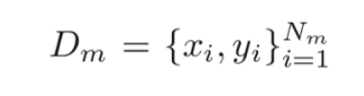
Nm indicates the scale of local data. In a heterogeneous federated learning environment, the conditional feature distribution P(x|y) varies across participants, even if P(y) is consistent, which leads to domain shift. The domain shift is defined as follows:
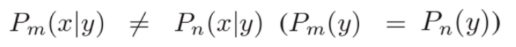
This means that there is domain shift in private data. Specifically, for the same label space, there are unique feature distributions among different participants.
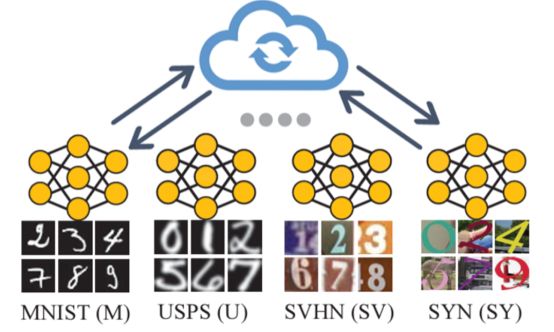
Figure 1 Differences of local client data from different source domains
In addition, all participants reach a consensus to share a model with the same architecture. This model consists of two main parts: feature extractor and classifier. The feature extractor, denoted as f: X->Z, encodes sample X as a one-dimensional feature vector in feature space Z, and is represented as:
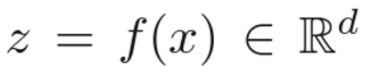
The classifier maps the features to logits output l=g(z). In subsequent formulas, I represents the class. The optimization goal is to learn a generalizable global model with good performance in multiple domains through federated learning.
Feature Prototypes
To implement subsequent prototype-related methods, this paper first constructs the prototype definition.
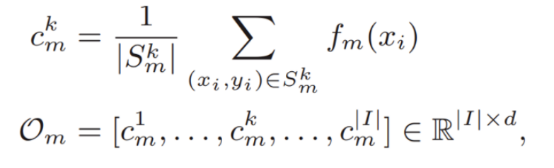
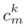
indicates a prototype whose label is k on the _m_th client. It is obtained by calculating the average value of feature vectors of all samples whose label is k on the _m_th client, and it intuitively represents the domain information of label k for this client.
If text methods are not considered, the most general method is to directly average the domain information 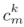 of all clients' labels, and let all clients learn this information to constrain their updates.
of all clients' labels, and let all clients learn this information to constrain their updates.
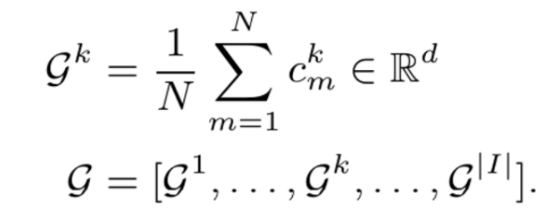
Gk indicates the average domain information of all samples with the label k from different domains in the entire federated system. However, the global domain shift exists, which cannot accurately represent the information of various domains and may also be biased towards the dominant domains, ignoring the minority domains, as shown in figure 2a.
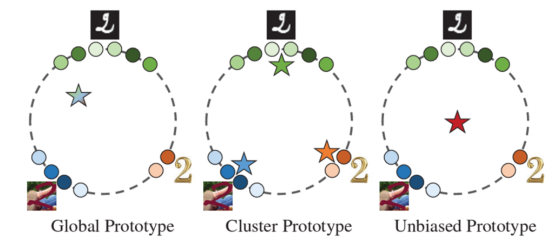
Figure 2 Prototype representations of different classes
3.2.2 Cluster Prototypes Contrastive Learning
To address the issue of global prototype existence, this paper first uses the FINCH method for unsupervised clustering to separate diverse domain knowledge (feature vectors of each sample) unsupervisedly. As a result, samples from different domains are clustered into different clusters due to differences in their respective feature vectors. Then, the prototype of each cluster can be calculated, as shown in Figure 2b. This prevents useful domain knowledge from being diluted by averaging across multiple domains.
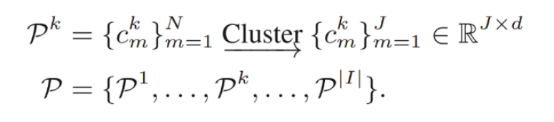

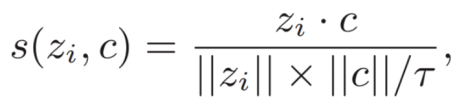
Then, build the loss items that implement cluster prototype contrastive learning.
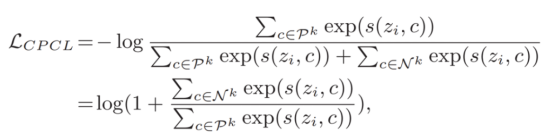
Why is this method effective? The authors provide the following analysis.

Minimizing this loss function is equivalent to tightly pulling the sample feature vectors towards their assigned positive cluster prototypes Pk, while moving them away from other negative prototypes Nk. This not only maintains invariance to distortion in multiple domains, but also enhances the semantic diffusivity property, ensuring that the feature space has both generalization and discrimination, thereby achieving satisfactory generalization performance in federated learning.
3.2.3 Unbiased Prototypes Consistent Regularization
The cluster prototypes incorporate diverse domain knowledge for the plasticity under domain shift. However, as the clustering method is unsupervised, cluster prototypes are dynamically generated during each communication, and the scale of each cluster prototype is changing. Therefore, cluster prototypes cannot provide a stable convergence direction in different communication epochs. The paper proposes a second method, which involves constructing a fair and stable unbiased prototype to constrain the distance between multiple cluster prototypes and the unbiased prototype to maintain multi-domain fairness.
Specifically, the multiple cluster prototypes with the same label that have been clustered are averaged to represent the unbiased convergence target k for that label, as shown in Figure 2c.
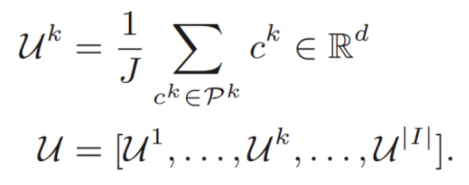
This paper introduces a second loss item and uses consistent regularization to bring feature vectors of samples closer to their respective unbiased prototypes Uk, thus providing relatively fair and stable optimization points to solve the problem of unstable convergence.
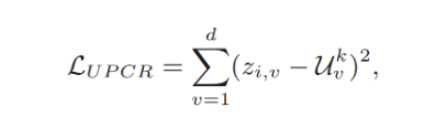
3.2.4 Overall Algorithms
In addition to the preceding two loss items, the cross entropy loss function used in conventional model training is also used as the loss function of federated prototype learning proposed in this paper.
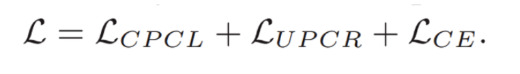
Learning process:
Algorithms in this paper:


04 Experimental Result
4.1 Comparison with State-of-the-art Test Results
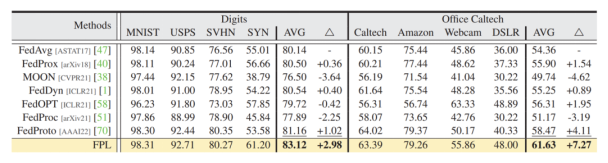
This paper conducts experiments based on the Digits and Office Caltech datasets. The former is a dataset with four same labels but different data sources, and the latter also features four identical labels, each associated with distinct real-world data sources. The experiments show that the proposed FPL outperforms the current SOTA in both single-domain performance and average performance across multiple domains.
4.2 Ablation Experiment
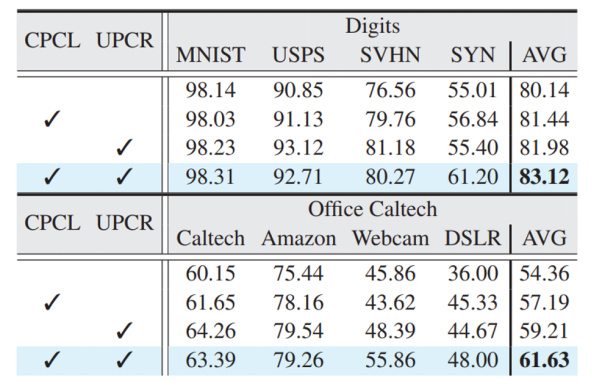
It can be observed that, in most cases, the combined effect of CPCL and UPCR produces better performance.
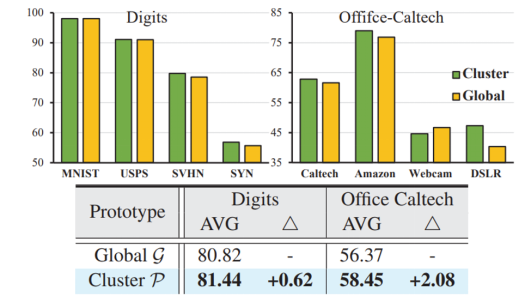
The effectiveness of the cluster and unbiased prototypes can be demonstrated by comparing the experimental results of using the conventional global prototype with those obtained using the proposed prototype.
4.3 MindSpore Code Display
This framework is developed based on MindSpore.
4.3.1 Cluster Prototypes Contrastive Learning Implemented by MindSpore
def calculate_infonce(self, f_now, label, all_f, all_global_protos_keys):
pos_indices = 0
neg_indices = []
for i, k in enumerate(all_global_protos_keys):
if k == label.item():
pos_indices = i
else:
neg_indices.append(i)
f_pos = Tensor(all_f[pos_indices][0]).reshape(1,512)
f_neg = ops.cat([Tensor(all_f[i]).reshape(-1, 512) for i in neg_indices], axis=0)
#aaa
f_proto = ops.cat((f_pos, f_neg), axis=0)
f_now = f_now.reshape(1,512)
f_now_np = f_now.asnumpy()
f_proto_np = f_proto.asnumpy()
def cosine_similarity_numpy(vec_a, vec_b):
dot_product = np.dot(vec_a, vec_b.T)
norm_a = np.linalg.norm(vec_a, axis=1, keepdims=True)
norm_b = np.linalg.norm(vec_b, axis=1)
return dot_product / (norm_a * norm_b)
l_np = cosine_similarity_numpy(f_now_np, f_proto_np)
l = Tensor(l_np)
#l = ops.cosine_similarity(f_now, f_proto, dim=1)
l = ops.div(l, self.infoNCET)
exp_l = ops.exp(l).reshape(1, -1)
pos_num = f_pos.shape[0]
neg_num = f_neg.shape[0]
pos_mask = Tensor([1] * pos_num + [0] * neg_num).reshape(1, -1)
pos_l = exp_l * pos_mask
sum_pos_l = ops.sum(pos_l, dim=1)
sum_exp_l = ops.sum(exp_l, dim=1)
infonce_loss = -ops.log(sum_pos_l / sum_exp_l)
return Tensor(infonce_loss)
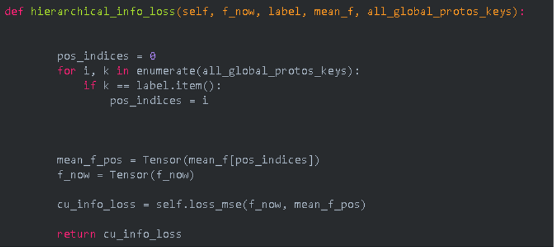
4.3.2 Unbiased Prototypes Consistent Regularization Implemented by MindSpore
4.3.3 Local Model Training on the Client
def _train_net(self, index, net, train_loader):
if len(self.global_protos) != 0:
all_global_protos_keys = np.array(list(self.global_protos.keys()))
all_f = []
mean_f = []
for protos_key in all_global_protos_keys:
temp_f = self.global_protos[protos_key]
all_f.append(copy.deepcopy(temp_f))
mean_f.append(copy.deepcopy(np.mean(temp_f, axis=0)))
all_f = [item.copy() for item in all_f]
mean_f = [item.copy() for item in mean_f]
else:
all_f = []
mean_f = []
all_global_protos_keys = []
optimizer = nn.SGD(net.trainable_params(), learning_rate=self.local_lr, momentum=0.9, weight_decay=1e-5)
criterion1 = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
criterion = CustomLoss(criterion1, self.loss2)
self.loss_mse = mindspore.nn.MSELoss()
train_net= nn.TrainOneStepCell(nn.WithLossCell(net,criterion), optimizer=optimizer)
train_net.set_train(True)
iterator = tqdm(range(self.local_epoch))
for iter in iterator:
agg_protos_label = {}
for di in train_loader.create_dict_iterator():
images = di["image"]
labels = di["label"]
# train_net.set_train(False)
f = net.features(images)
#train_net.set_train(True)
if len(self.global_protos) == 0:
loss_InfoNCE = 0
else:
i = 0
loss_InfoNCE = None
for label in labels:
if label in all_global_protos_keys:
f_now = f[i]
cu_info_loss = self.hierarchical_info_loss(f_now, label, mean_f, all_global_protos_keys)
xi_info_loss = self.calculate_infonce(f
05 Summary and Prospects
In this paper, the authors explored the issues of generalizability and stability in heterogeneous federated learning under domain shift. Their research introduced a simple yet effective federated learning algorithm, FPL, which uses prototypes (typical representations of classes) to solve these two issues, benefiting from the complementary advantages of cluster and unbiased prototypes, that is, diverse domain knowledge and stable convergence signals. They implemented the FPL framework using the MindSpore architecture and demonstrated its advantages in efficiency and accuracy.
When developing the FPL framework using MindSpore, the authors noticed that the MindSpore community was highly active, and that many Huawei developers and users provided significant help in addressing the challenges encountered in building the framework. The authors were able to avoid potential pitfalls more efficiently thanks to the extensive documentation and tutorials offered by MindSpore, as well as the practical and best practices shared within the community.