Project Introduction | MindSpore Serving Deploys Large Model Inference
Project Introduction | MindSpore Serving Deploys Large Model Inference
1. Why MindSpore Serving
In the large model era, developers focus on large model training, model parameter adjustments, and higher model precision, all of which form an integrated project that has real value only when it is implemented. How can large models be implemented? How can functions and contents in a large model project be presented to users in the form of apps?
Serving is the component that answers these questions, and it is mainly responsible for:
Submissions of models;
Deployment;
Output presented to users;
Applications in various complex scenarios.
MindSpore Serving is born to deploy large models to the production environment.
MindSpore Serving is a lightweight and high-performance service module that helps MindSpore developers efficiently deploy online inference services in the production environment. After a user completes model training using MindSpore and exports MindIR, MindSpore Serving can be used to create an inference service for the large model.
MindSpore Serving implements service-oriented model deployment. That is, models are deployed online on servers and clouds. Users access Serving through browsers or clients, and transfer the input to be inferred to the server. The server returns the inference result to users.
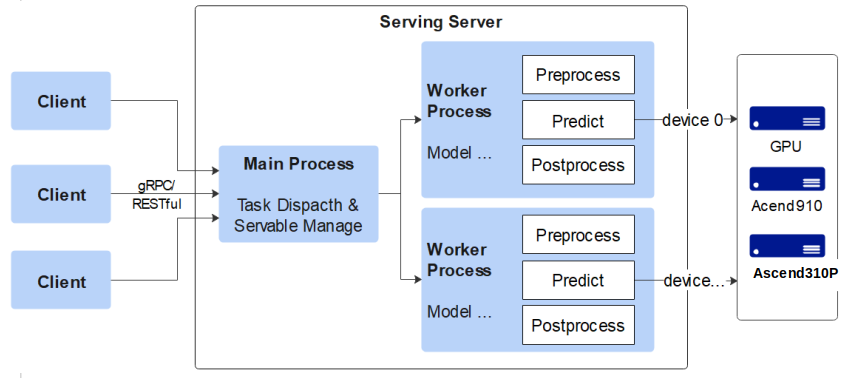
2. Component
MindSpore Serving consists of Client, Primary, and Worker.
Client is a user node that provides gRPC and RESTful access.
Primary is a management node that manages information about all workers, including models that workers have. Primary is also a distribution node. After receiving a request from a client, the primary node distributes the request to different workers based on the request detail and the managed worker node information.
Worker is an execution node that loads and updates models. After receiving a request from Primary, the worker node assembles and splits the request, pre-processes, infers, and post-processes the request, and returns the result to Primary. Primary then returns the result to Client.
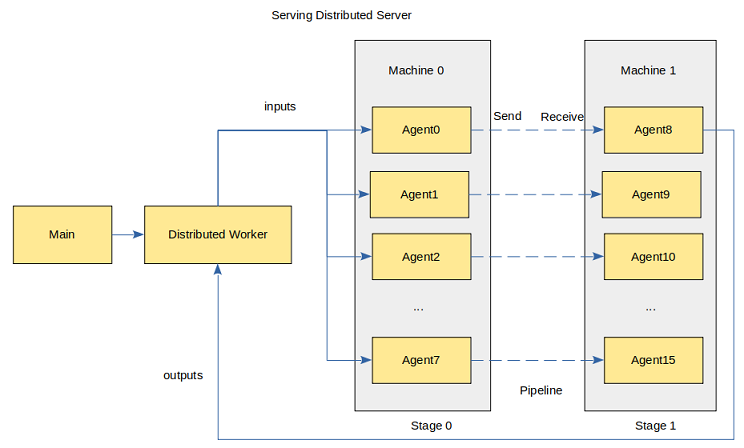
3. Features
- Easy to Use
MindSpore Serving provides gRPC and RESTful services for clients, and also provides service starting, service deployment, and client access. It provides simple Python interfaces for users to customize and access the deployment service in a simple way. Just one line of command can get things done.
- Customizable
For a model, the input and output are often fixed while the input and output may be variable for a user. Therefore, a preprocessing module is required to convert the input into one that can be identified by the model. Additionally, a post-processing module is required to provide customization for users. Users can customize the classifly_top method for specific models and write pre-processing and post-processing operations as required. The client only needs to specify the model name and method name to implement the inference result.
- Batch Processing Supported
This function mainly supports the text with the batchsize dimension. batchsize implements text concurrency. When the hardware resources are sufficient, batchsize can greatly improve the performance. The number of requests to MindSpore Serving sent by a user at a time are uncertain. Therefore, MindSpore Serving splits or combines one or multiple requests to match batchsize of the user model. For example, if batchsize is 2 while there are three requests, MindSpore Serving combines two requests and split them later. In this way, the three requests are processed concurrently, improving efficiency.
- High-Performance and Scalable
The operator engine framework used by MindSpore Serving is MindSpore Framework, which features high performance of automatic fusion and automatic concurrency. Moreover, MindSpore Serving has a high-performance underlying communication capability. With the support of all these features, multiple instances can be assembled by the client, batch processing is supported by models, concurrency supported between multiple models, and multi-thread processing supported by pre-processing and post-processing. Client and Worker can be scalable, thus achieving high scalability.
4. Demo
Based on Ascend Training Processor
start_agent.py
from agent.agent_multi_post_method import
from multiprocessing import Queue
from config.serving_config import AgentConfig, ModelName
if —name— == "—main—":
startup_queue = Queue(1024)
startup_agents(AgentConfig.ctx_setting,
AgentConfig.inc_setting,
AgentConfig.post_model_setting,
len(AgentConfig.AgentPorts),
AgentConfig.prefill_model,
AgentConfig.decode_model,
AgentConfig.argmax_model,
AgentConfig.topk_model,
startup_queue)
started_agents = 0
while True:
value = startup_queue.get()
print("agent : %f started" % value)
started_agents = started_agents + 1
if started_agents >= len(AgentConfig.AgentPorts):
print("all agents started")
break
# server_app_post.init_server_app()
# server_app_post.warmup_model(ModelName)
# server_app_post.run_server__app()