OFA-KD, A Knowledge Distillation Method for Heterogeneous Models, Distills Any Model and Is Now Open Source on MindSpore
OFA-KD, A Knowledge Distillation Method for Heterogeneous Models, Distills Any Model and Is Now Open Source on MindSpore
Author: Wang Yunhe Source: Zhihu

Since knowledge distillation (KD) was first proposed in 2014, it has been widely used in the model compression field. With auxiliary supervisions by the more powerful teacher models, student models are often able to achieve higher precision than being directly trained. However, the existing research on KD only focuses on the homogeneous architecture model scenario, and ignores the heterogeneous architectures of teacher and student models. For example, the most advanced MLP model can only reach the precision at 83% on ImageNet dataset, and a teacher model of the same architecture with a higher precision cannot be obtained to further improve MLP's precision through KD. Therefore, there is practical application significance in the research on the knowledge distillation of heterogeneous models.
The researchers analyzed the differences in the features of heterogeneous models (such as CNN, ViT, and MLP) and concluded that the architecture-related information in the features hinders the process of KD. Based on the analysis, the researchers proposed a KD method for heterogeneous models called one-for-all KD (OFA-KD). This method maps features to a unified space that is architecture-independent for conducting heterogeneous model knowledge distillation, and uses a loss formulation that can adaptively enhance the target information. On CIFAR-100 and ImageNet datasets, this method surpasses the existing homogeneous-architecture KD methods.
For the paper, see https://arxiv.org/abs/2310.19444
MindSpore code: https://gitee.com/mindspore/models/tree/master/research/cv/
Feature Differences Between Heterogeneous Models
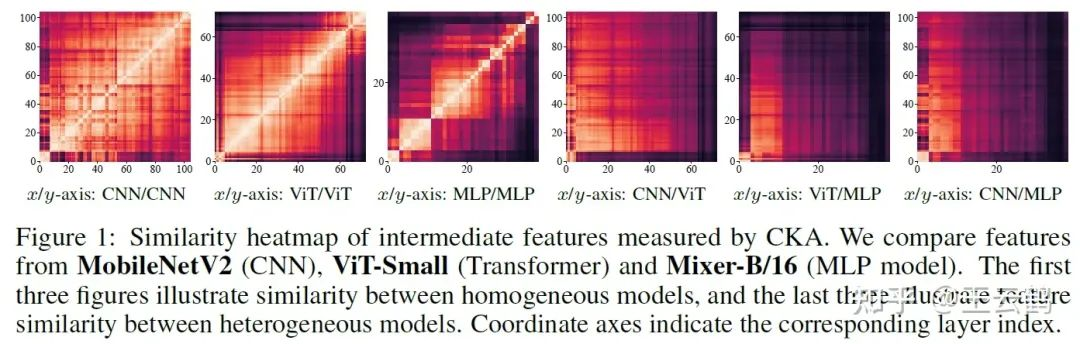
Fig. 1 Comparison of features learned by heterogeneous models
Compared with the method that only uses logits, the method that uses both the intermediate features and logits can achieve better performance. However, in heterogeneous model scenario, heterogeneous-architecture models have different preferences in learning features, their intermediate features usually differ greatly. Directly migrating a method for homogeneous-architecture models to heterogeneous models causes performance deterioration.
Common KD Method for Heterogeneous Models
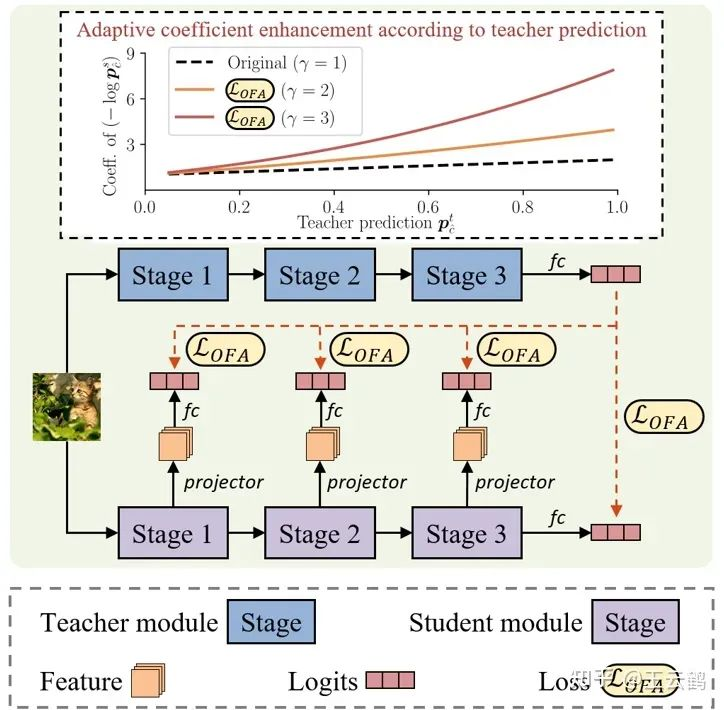
Fig. 2 KD method for heterogeneous models
In order to utilize intermediate features during the distillation of heterogeneous models, it is necessary to eliminate the interference caused by the architecture-related information in the features and retain only task-related information. Therefore, the researchers proposed to filter the architecture-related information by mapping the intermediate features of the student model to the logits space. In addition, an additional adjustment coefficient is added into the KL divergence-based loss formulation, so that the modified loss formulation can adaptively enhance the target information, thereby further filtering interference caused by irrelevant information during distillation of heterogeneous models.
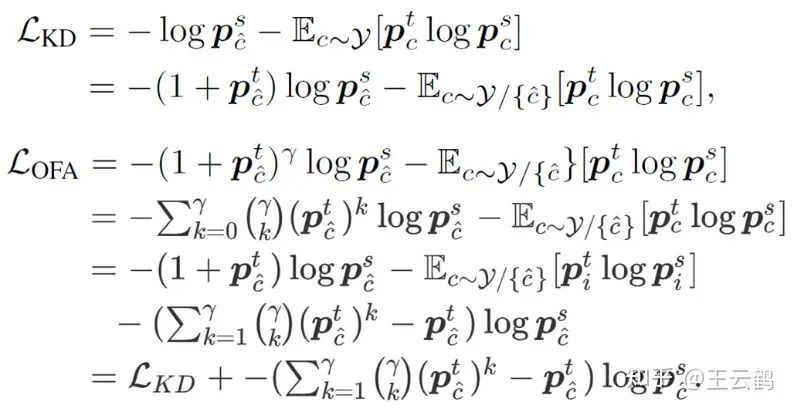
Fig. 3 Comparison between original KD loss and improved KD loss
Experimental Result
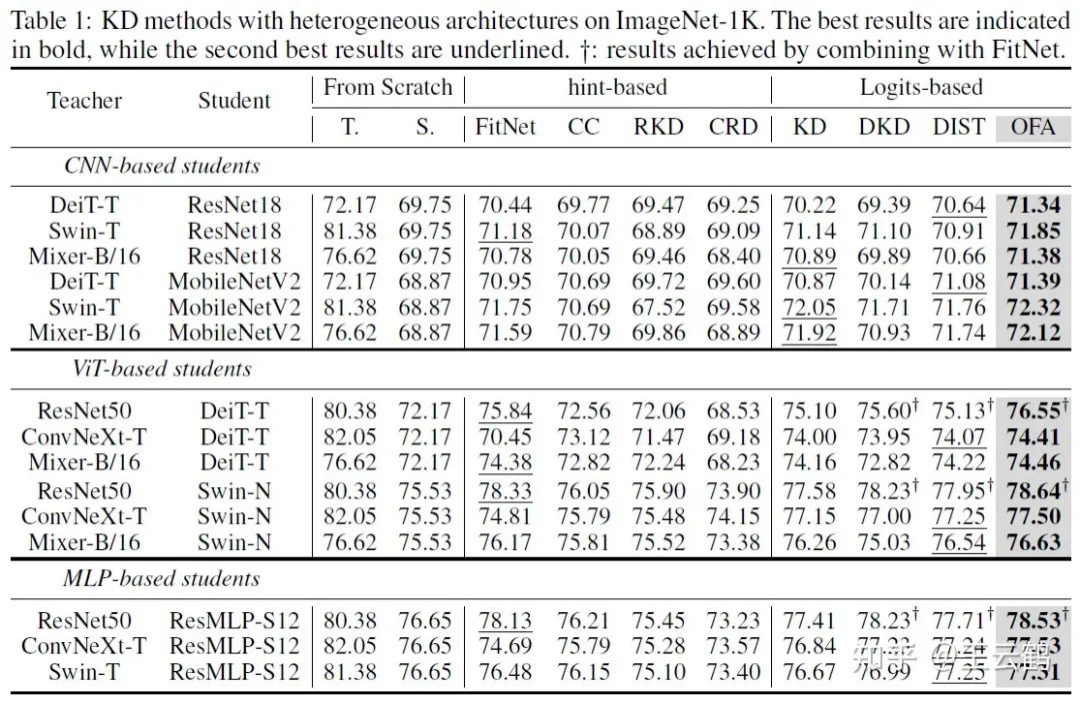
Fig. 4 KD results of heterogeneous models on ImageNet
The above figure shows the KD results of heterogeneous models on ImageNet. In the six possible heterogeneous model combinations out of all architectures, OFA-KD proposed in this paper has obtained better results than existing methods.
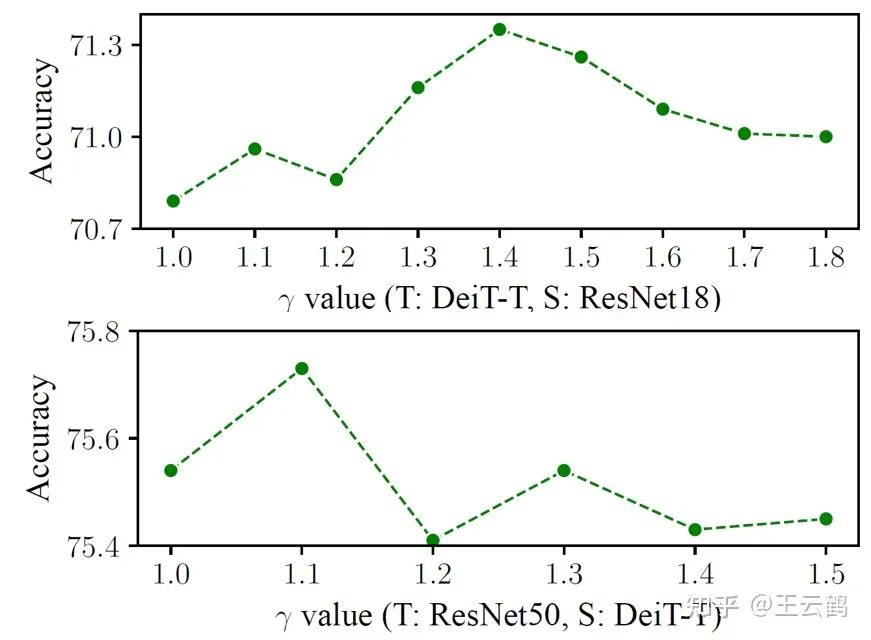
Fig. 5 Impact of different values on the result
The above figure compares the impact of different value settings on the result on ImageNet. It can be seen that by selecting a proper value setting, the improved KD loss formulation can obtain a better result than that of the original KD loss formulation.

Fig. 6 KD results of homogeneous models on ImageNet
In this paper, OFA-KD is compared with traditional KD of homogeneous models on ImageNet. In terms of the distillation for the homogeneous combination of ResNet34 and ResNet18 teacher and student models, OFA-KD also has the similar performance as SOTA.
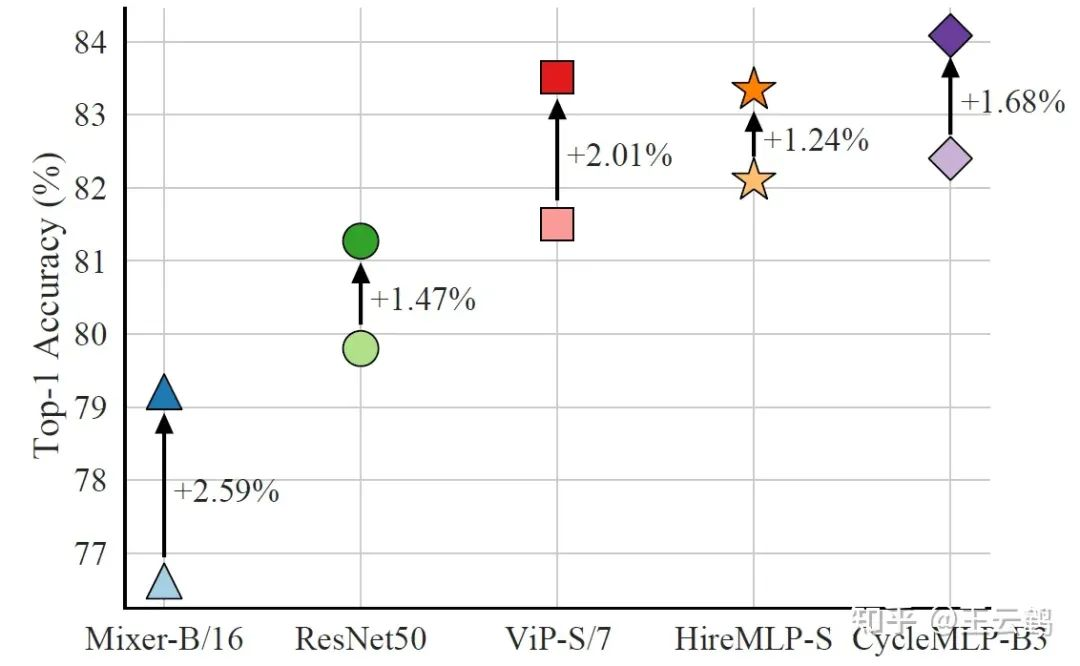
Fig. 7 KD results of the MLP student model
This blog also compares the KD result of the MLP student model. BEiT v2-base of the ViT architecture is selected as the teacher model. The medium-sized CycleMLP-B3 model refreshes the best result of the MLP model on ImageNet.
Conclusion
In this blog, we have studied the KD methods of heterogeneous models. We can map the intermediate features of student models to the logits space to fit teacher models for a final output, and use a loss formulation that can adaptively enhance the target information which is an improvement based on the original KD loss formulation. The proposed OFA-KD surpasses the existing methods on multiple datasets and among multiple teacher-student model combinations, expanding the application scope of knowledge distillation.