MindSpore-powered Epoch-Evolving GPGL Method: Making Image Classification More Accurate
MindSpore-powered Epoch-Evolving GPGL Method: Making Image Classification More Accurate
Author: Li Ruifeng | Source: Zhihu
Paper Title
Epoch-Evolving Gaussian Process Guided Learning for Classification
Paper Source
IEEE Transactions on Neural Networks and Learning Systems
Paper URL
https://ieeexplore.ieee.org/document/9779793
Code URL
https://paperswithcode.com/paper/epoch-evolving-gaussian-process-guided
As an open-source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumers, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers account for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share the paper of the team led by Prof. Li Xi, Zhejiang University.
MindSpore aims to achieve three goals: easy development, efficient execution, and all-scenario coverage. The development of MindSpore has been characterized by rapid improvements with successive iterations, with its API design being more complete, reasonable, and powerful. To augment its convenience and power, several kits based on MindSpore have been developed. One such example is MindSpore Insight, which can present model architectures in graphs and dynamically monitor the changes of indicators and parameters during model execution, thereby simplifying the development process.
The paper introduces a novel approach called epoch-evolving Gaussian process guided learning (GPGL), which is designed for classification tasks and aims to mitigate the 'zig-zag' effect commonly observed in the learning process of mini-batch gradient descent algorithms. It can be universally applied to current deep learning models to accelerate their convergence processes. The experiment in this paper mainly involves applying a newly designed triangle consistency loss function to ResNet for image classification in the CIFAR-10 and CIFAR-100 datasets, with an epoch-evolving method. With the cases in MindSpore official documents or related code and models provided by the community, you can easily implement the required code for this experiment.
01 Research Background
In recent years, deep learning has made significant progress and has been widely applied. Due to the limitation of computing resources, deep learning models have to rely on mini-batch stochastic gradient descent algorithms, such as SGD and SGD-M, to perform iterative model learning over a series of epochs. In the learning process, deep learning methods asynchronously update model parameters based on the time-varying batches of samples to capture the local batch-level distribution information, which results in the 'zig-zag' effect during optimization. Therefore, a deep learning model typically requires a large number of epochs of iterations to achieve sufficient model learning, which essentially takes a bottom-up learning pipeline from local batches to global data distribution. However, for sample batches continuously added in different epochs, such a pipeline cannot effectively establish the correlation between the batch-level distribution and global data distribution.
Recently, to speed up the convergence of deep learning networks and improve the performance, researchers have added constraints or additional guidance to mini-batch learning. For example, the regularization method constrains the learning process by modifying the loss function to achieve better performance. The label smoothing method generates a soft goal to facilitate the standard learning process, thereby improving the generalization capability. The knowledge distillation method enhances the performance of convolutional neural networks by compressing the network scales. The class information encoding method typically focuses on better feature extraction, which is more effective in maintaining class separability and avoiding overfitting.
02 Team Introduction
This paper was written by the team led by Prof. Li Xi, Zhejiang University. Prof. Li Xi is a distinguished professor at Zhejiang University, and a fellow of the National Science Fund for Distinguished Young Scholars. He is also the chief scientist of the 2030 next-generation key AI projects of the Ministry of Science and Technology. His main research interests lie in the fields of computer vision, pattern recognition, and machine learning. With over 180 papers published in top academic conferences and international authoritative journals, he also has multiple ESI highly-cited papers. Prof. Li Xi is the domain-specific chairperson for several leading conferences such as CVPR, ICCV, and ECCV, and serves as a reviewer and procedure committee member for multiple international journals and conferences. He has won the highest "Outstanding AI Leader Award" at the 2021 World Artificial Intelligence Conference, as well as two best paper awards from international conferences, and a paper award (top 10%) from ICIP 2015.
03 Introduction to the Paper
To represent the correlation between the batch-level distribution and global data distribution, a novel learning scheme called epoch-evolving GPGL is proposed in this paper. Its overall framework is shown in figure 1, which consists of GP model construction (at the top) and GP model guided learning (at the bottom). (GP is short for Gaussian process. It is a global distribution-aware learning, nonparametric modeling, and top-down strategy.)
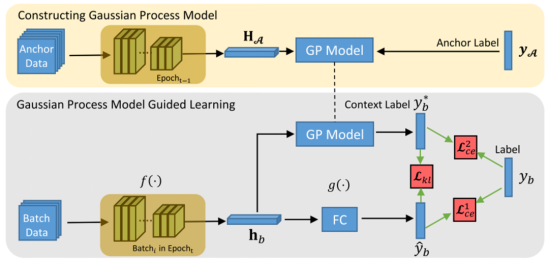
Figure 1 GPGL framework
GPGL leverages a nonparametric learning model to approximately encode global data distribution information into a class distribution. The global distribution is represented by a class-aware sampling anchor set, which randomly selects a certain number of samples for each class in the dataset. At the beginning of each epoch, the GP model constructs a target representation space based on the deep features of the anchor set to capture the global topology of class information. Then, in subsequent iterations, the nonparametric GP model is fixed to guide the batch-level representation learning, which is a hybrid strategy combining top-down and bottom-up approaches. At the end of each epoch, the target representation space is updated to improve the behavior of the GP model, and this is referred to as 'epoch evolving'.
For each epoch, GPGL builds a class distribution regression model called the GP model in the corresponding feature space. By modeling the joint distribution of the anchor set related to a mini batch, the GP model can predict the class distribution probability of every sample in the mini batch. Therefore, for each sample in the batch data, the GP model can estimate its class distribution based on the global data distribution. The correlation between the batch data distribution and global data distribution will be reflected in the class distribution predicted by the GP model. This class distribution is called the context label in the paper and is utilized to regularize the learning process. Essentially, this context label estimation is equivalent to the context label propagation process, where the class distribution information is dynamically propagated from anchor samples to batch samples through the GP method.
Subsequently, under the guidance of the propagated context label, a deep learning model can learn the class distribution information in the conventional learning pipeline. Additionally, a triangle consistency loss function consisting of three learning parts has been proposed:
(1) Deep learning model prediction with the ground-truth label;
(2) Deep learning model prediction with the context label;
(3) Context label and ground-truth label.
The triangle consistency loss function is jointly optimized in each epoch. After one epoch, the feature space associated with the epoch is updated according to the latest deep learning model. Based on the updated feature space, the triangle consistency loss is optimized again in the next epoch. This learning process is repeated until convergence or a fixed number of epochs is reached.
04 Experimental Result
The authors conducted a comparison between the GPGL method and several state-of-the-art optimization strategies, including PID, FTC, COT, Adabound, LS, SD, and CIE, on seven datasets. The result is shown in table 1, where the numbers represent error rates (%). The GPGL method outperforms the state-of-the-art optimization methods by an average of 2.07% on six datasets, with the exception of MNIST. For CIFAR-100, Tiny-ImageNet, and Caltech-256 datasets, the GPGL performance is on average 3.15%, 3.05%, and 3.33% higher than the other four optimization methods. Compared with the second-best performing COT method, the GPGL method improves the accuracy by an average of 0.92%. For the CIFAR-100 dataset, the GPGL performance is 7.33% higher than Adabound.

Table 1 Comparison between GPGL and other optimization methods
05 Summary and Prospects
In this paper, the authors proposed an epoch-evolving GPGL method to estimate context-aware class distribution information and effectively guide the conventional bottom-up learning pipeline. The paper demonstrated the effectiveness of the triangle consistency loss function in balancing batch learning and global distribution-aware nonparametric modeling through context labels. In addition, the GPGL method has been demonstrated to outperform state-of-the-art optimization methods based on experiments conducted on various datasets including CIFAR-10, CIFAR-100, Tiny-ImageNet, Caltech-256, Corel-5k, and Corel-10k using the MindSpore framework.