Ultimate Compression: Smartphone-adapted TinySAM Is Open-Source in MindSpore
Ultimate Compression: Smartphone-adapted TinySAM Is Open-Source in MindSpore
Author: Wang Yunhe
Source: Zhihu
The segment anything model (SAM) exhibits a powerful segmentation capability. However, SAM cannot be directly used in device-side due to limited resources, complex network structure and high computational cost. More over, we find that in the everything mode inference of SAM, the traditional grid prompt point mode causes huge computational costs. To solve this problem, we developed the TinySAM model, which uses knowledge distillation and quantization to compress the SAM model. In TinySAM, we also propose a hierarchical everything inference strategy which helps TinySAM still maintain the powerful zero-shot segmentation capability of SAM while computational cost is reduced significantly. For details about the paper, refer to this link. In addition, the MindSpore code and model of TinySAM are open source now, and you are welcome to download and try it out through this link. The following is the application demonstration. TinySAM can automatically segment point prompt and box prompt on smartphones.
TinySAM: a SAM That Is Ultimately Efficient
SAM is compressed through knowledge distillation and post-quantization. An acceleration method for everything inference is also proposed to explore the performance and efficiency limits of SAM.
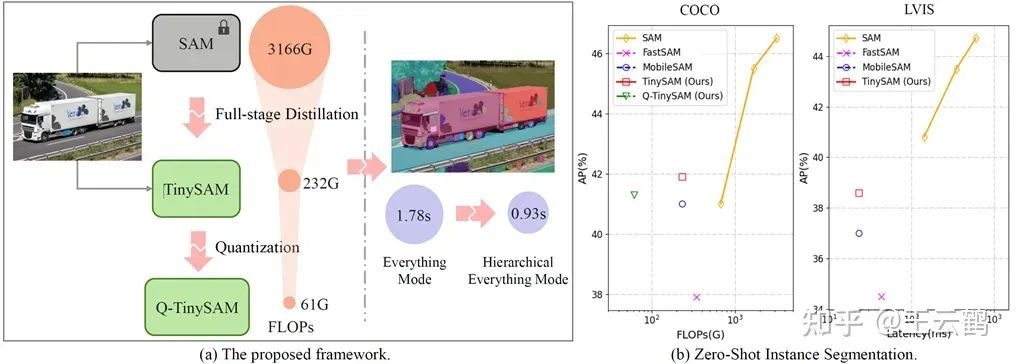
Figure 1: (a) shows the framework of TinySAM. Through a full-stage knowledge distillation, post-quantization, and hierarchical everything inference, the computation cost is down-scaled to 1/50 of the original scale. (b) shows that TinySAM still maintains good performance on zero-shot instance segmentation tasks.
1. Full-Stage Knowledge Distillation
SAM's multi-module structure leads to difficulties in optimization. To solve this problem, we propose a full-stage knowledge distillation method to guide the learning from multiple knowledge level, and design the distillation losses from the following aspects: embedding (image feature), mask (final supervision feature), and token (intermediate transition feature), which aims at minimizing the learning difficulty of lightweight student networks.
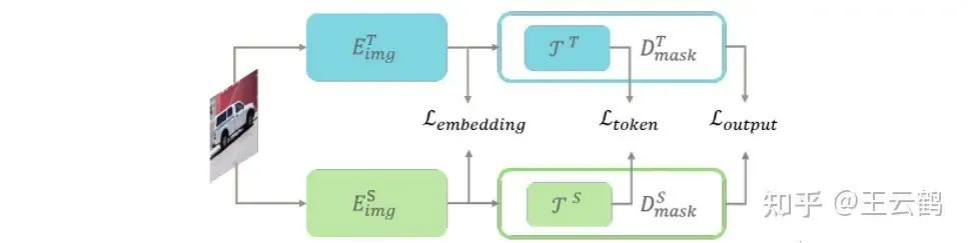
Figure 2: The framework of the full-stage knowledge distillation
2. Post-Quantization Model
To further reduce the model calculation workload and improve the inference efficiency, TinySAM is quantized to 8 bits. The convolutional layer and inverse convolutional layer use channel-wise uniform asymmetric quantization, and the matmul and linear layers use headwise and layerwise uniform symmetric quantization, respectively. For the quantization strategy, the network is quantized layer by layer, and the hessian guided metric that is more consistent with the task loss is used as the distance metric before and after the quantization. The calculation workload of the quantized model can be further reduced to about 1/4 of the original scale.
3. Hierarchical Everything Inference
In everything inference mode, SAM uses dense grid point prompt for inference. We find that such dense prompt input and inference consume a large amount of computing workload. Therefore, we design a hierarchical everything inference strategy. First, we obtain an initial result from a smaller number of sampling points, then we remove dense sampling points in the high confidence regions to obtain a second inference result. Then we post-process and merge the initial and second results to obtain a final inference result. This strategy greatly reduces the number of sampling points and inference time, while maintaining the segmentation effect.
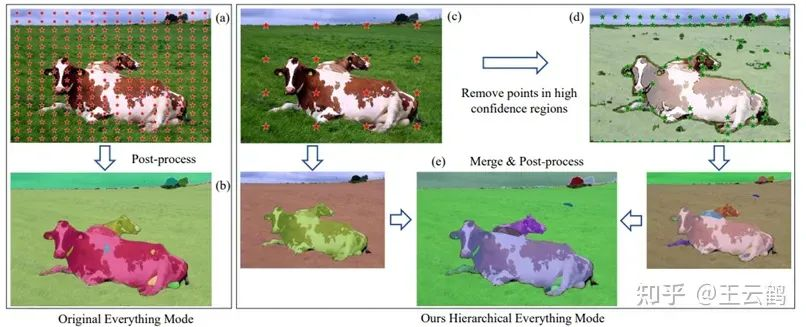
Figure 3: Comparison between our hierarchical strategy and the original strategy: (1) obtaining an initial result from a small number of sampling points; (2) removing dense sampling points in the high confidence regions to obtain a second inference result; (3) post-processing and merging the initial and second results to obtain a final inference result.
Experimental Result
We conducted experiments on multiple zero-shot downstream tasks, including zero-shot instance segmentation experiment on COCO and LVIS datasets. We input the detection boxes obtained through ViTDet as prompt to TinySAM according to the settings in the SAM paper. Compared with MobileSAM, TinySAM improves the average precision on COCO by 0.9% and that on LVIS by 1.6%. Even after 8-bit quantization, TinySAM still maintains its performance advantage. For more experimental results and visualization results, please refer to the paper.

