Temporal Action Proposal Generation with Action Frequency Adaptive Network Based on MindSpore
Temporal Action Proposal Generation with Action Frequency Adaptive Network Based on MindSpore
Paper Title: Temporal Action Proposal Generation With Action Frequency Adaptive Network
Published in: TMM 2023
Paper URL: https://ieeexplore.ieee.org/abstract/document/10183357
Code URL: https://gitee.com/chunjie-zhang/afan-tmm2023
As an open-source AI framework, MindSpore supports ultra-large-scale AI pre-training and brings excellent experience of device-edge-cloud synergy, simplified development, ultimate performance, and security and reliability for researchers and developers. Since it was open sourced on March 28th, 2020, MindSpore has been downloaded for more than 6 million times. It has also been the subject of hundreds of papers presented at premier AI conferences. Furthermore, it has a large community of developers and has been introduced in over 100 top universities and 5000 commercial applications. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumers, and smart automobiles, MindSpore has emerged as the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers account for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share the paper of the team led by Prof. Zhang Chunjie, School of Computer and Information Technology at Beijing Jiaotong University.
01 Research Background
As the cornerstone in video understanding, temporal action proposal generation aims to predict the start and end time of human action instances in untrimmed videos, and plays an important role in understanding human behavior in videos. Although the performance of temporal action proposal generation has been significantly improved in recent years, most previous studies ignored the variability of action frequencies in raw videos. As a result, these methods do not perform well when processing high-action-frequency videos. Through detailed data analysis, we have identified two main issues: data imbalance between high- and low-action-frequency videos, and inferior detection of short actions in high-action-frequency videos. To address these issues, we propose an effective framework that flexibly adapts to different action frequencies. It can be seamlessly integrated into existing temporal action proposal generation methods to significantly improve their performance. The algorithm can be implemented using the cases in the MindSpore official documentation and the code we provided.
WITH the fast development of video surveillance, mobile phones and other camera devices, the amount of video data is increasing rapidly, which is impossible for human beings to process. How to use intelligent video understanding algorithms to effectively collect, manage, and utilize the video data has become a research hotspot. In recent years, significant progress has been made in human action recognition. However, human action recognition mainly focuses on short trimmed video clips and is difficult to apply to long untrimmed real-life videos. Therefore, temporal action detection focusing on untrimmed videos has gained wide attention recently.
Temporal action detection first locates the start and end time of human action instances in long untrimmed videos and then classifies these actions. Existing methods usually divide this task into two sub-tasks: Temporal Action Proposal Generation (TAPG) and action classification. The goal of TAPG is to predict the start and end time of human action instances in untrimmed videos, while the classification task is to classify these action instances. Although significant progress has been made in action classification, the performance of temporal action detection still needs to be improved due to the insufficient recall rate of TAPG. Therefore, how to accurately locate actions in untrimmed videos has become a top concern. Both the durations of untrimmed videos and action instances vary, which brings a great challenge to temporal action proposal generation.
TAPG models generally focus on predicting the boundaries of temporal action instances or the confidence scores of action anchor boxes, or both. However, most of the methods ignore the variability of action frequencies in untrimmed videos, which is common in the real world. Therefore, it is critical to study how to adapt to action frequency variability in videos and improve performance on high-action-frequency videos.
02 Team Introduction
Tang Yepeng, the first author of this paper, is a PhD from the School of Computer and Information Technology, Beijing Jiaotong University. His research focuses on computer vision, video understanding, and temporal action localization.
The Center of Digital Media Information Processing (MePro) at Beijing Jiaotong University started in 1998 and was recognized under the Innovation Team Development Plan of the Ministry of Education in 2012. MePro consists of 14 teachers and more than 100 master's and PhD students. Its research primarily revolves around digital media information processing, including image/video coding and transmission, digital watermark and forensics, and media content analysis and understanding. In 2022, the lab made significant contributions to the field by publishing 61 high-impact papers, including 38 papers in the esteemed international journal IEEE Trans and 23 papers presented at top-tier international conferences like NeurIPS, CVPR, ECCV, and ACM MM.
03 Introduction to the Paper
The paper introduces a study on a technology of TAPG in videos. This technology plays a critical role in video analysis and intelligent surveillance, with an aim to locate human behavior in long untrimmed videos. Both the durations of untrimmed videos and action instances vary, which brings a great challenge to temporal action proposal generation.
TAPG models generally focus on predicting the boundaries of temporal action instances or the confidence scores of action anchor boxes, or both. However, most of the methods ignore the variability of action frequencies in untrimmed videos. Through data analysis, we summarize two main issues:
1. Data imbalance results in poor performance with high-action-frequency videos. TAPG models often perform well on low-action-frequency videos, but cannot process high-action-frequency videos well.
2. A large number of short actions limit the performance with high-action-frequency videos. There are more short action instances in high-action-frequency videos than in low-action-frequency videos. It is difficult to locate these short action instances, similar to small objects in object detection.
To address the above problems, we propose Action Frequency Adaptive Network (AFAN) for temporal action proposal generation framework. On the one hand, we use Learning From Experts (LFE) to mitigate data imbalance. Specifically, we divide the entire video dataset into several subsets, each with less imbalanced data distribution. In this way, we can ensure that expert models trained on these subsets are less affected by data imbalance. To integrate knowledge from expert models, we then train a unified student model through knowledge distillation, which adapts to videos with different action frequencies.
We also design an action frequency classifier to identify high-action-frequency videos, and then perform fine-grained detection on them to improve the prediction performance with short actions. Our proposed AFAN can be easily applied to existing temporal action proposal generation models. We validated AFAN on two classical models, BMN and DBG, on four benchmark datasets. Extensive experimental results prove the effectiveness and generalizability of AFAN.
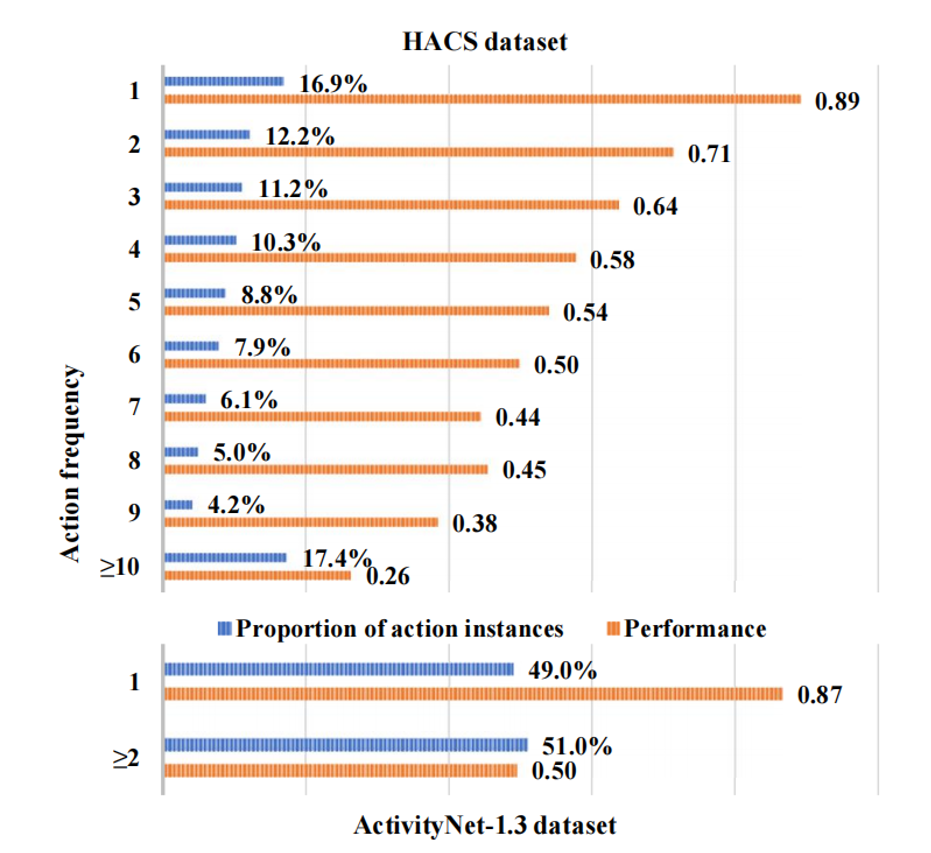
Performance comparison of existing models on videos with different action frequencies
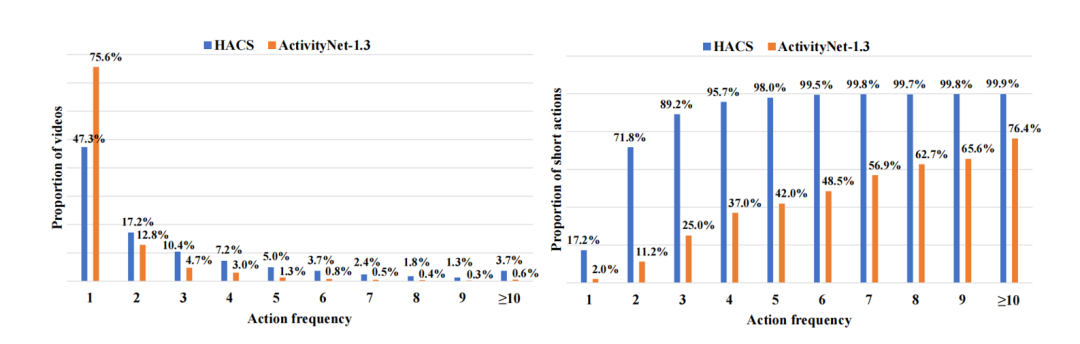
Distribution of videos with different action frequencies in existing datasets
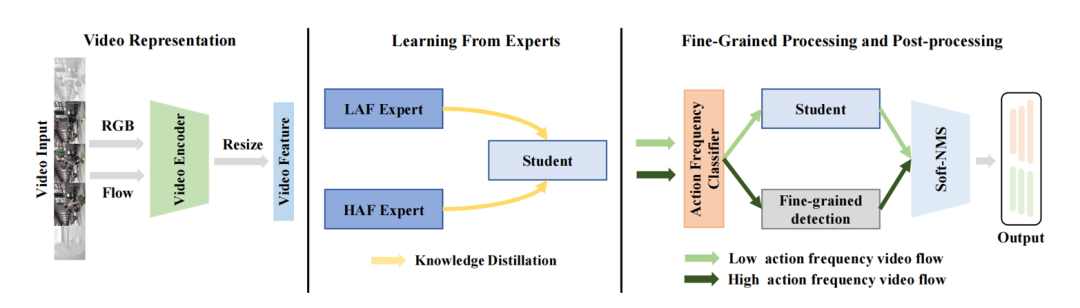
Framework architecture
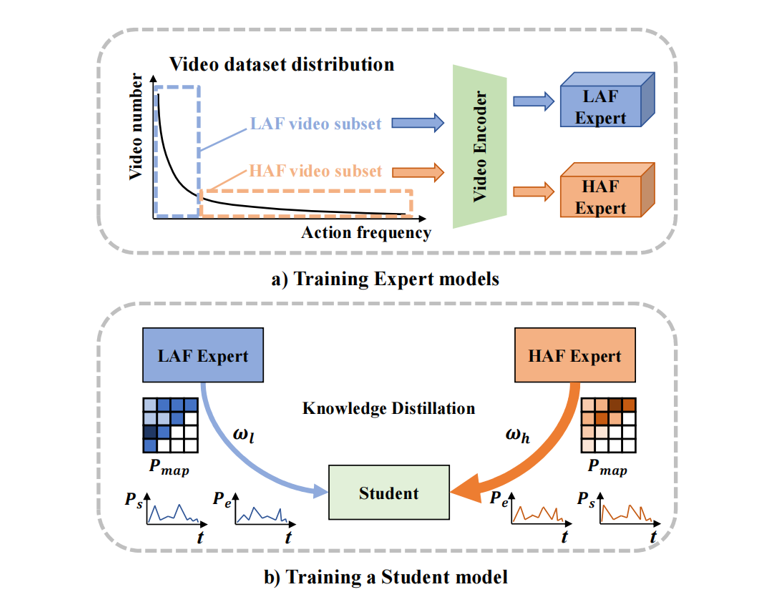
LFE module
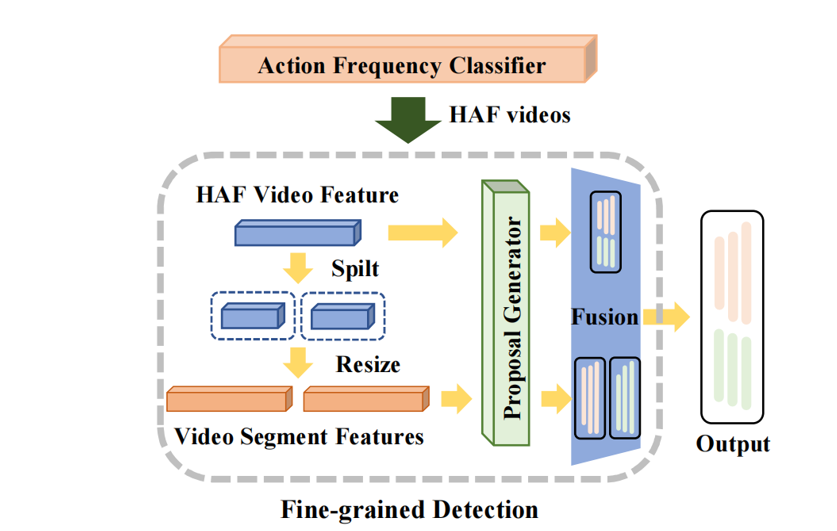
Fine-Grained Processing (FGP) module
04 Experiment Results
Experiments are conducted on publicly recognized TAPG datasets, including THUMOS14, ActivityNet-1.3, FineAction, and HACS. The comparison results and analysis of AFAN and other algorithms are as follows.
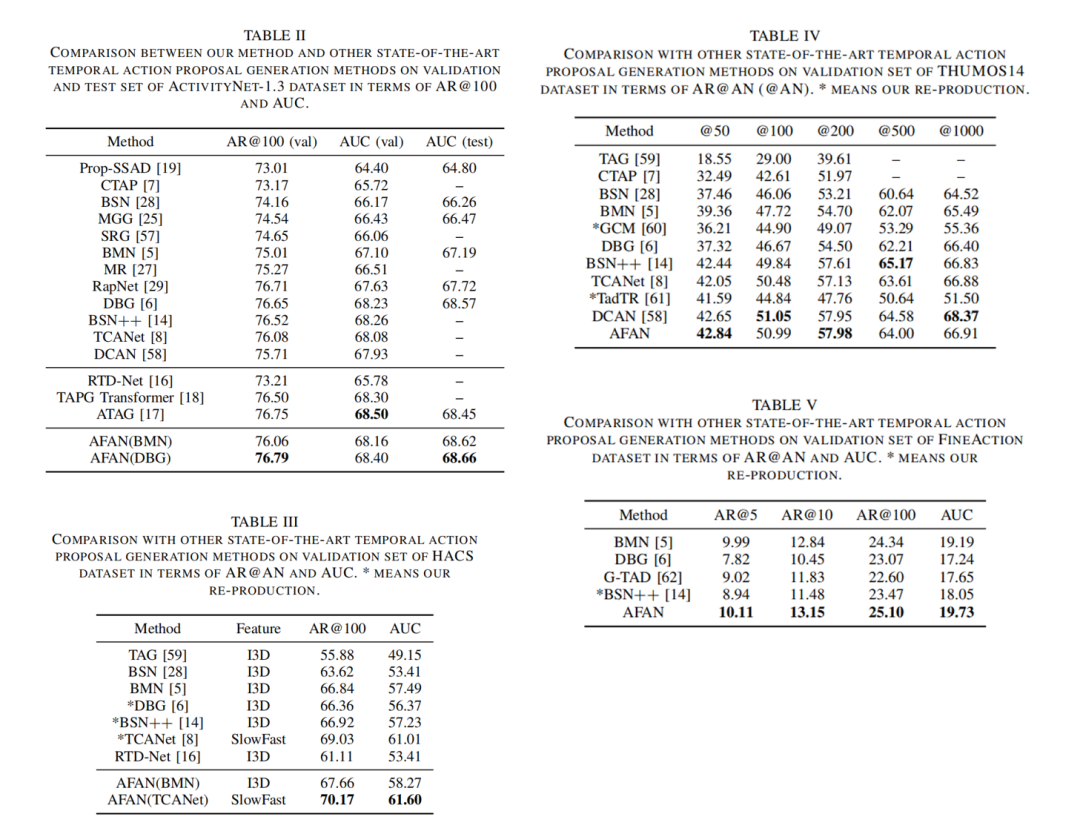
Performance comparison of TAPG on different datasets
Experimental results show that AFAN can effectively improve the performance of existing TAPG methods. AFAN(BMN) outperforms the benchmark method BMN by 1.06% and 1.43% in terms of the Area Under the average recall versus average number of proposals per video Curve (AUC) on the validation and test sets of ActivityNet-1.3, respectively. To further validate the effectiveness of our method, we also perform verification based on the advanced TAPG method DBG. DBG produces start, end, and action confidence maps at the same time to evaluate all action proposals, and can generate more flexible action proposals compared with BMN. With DBG, a better action proposal generator, AFAN(DBG) achieves higher performance on the ActivityNet-1.3 dataset.
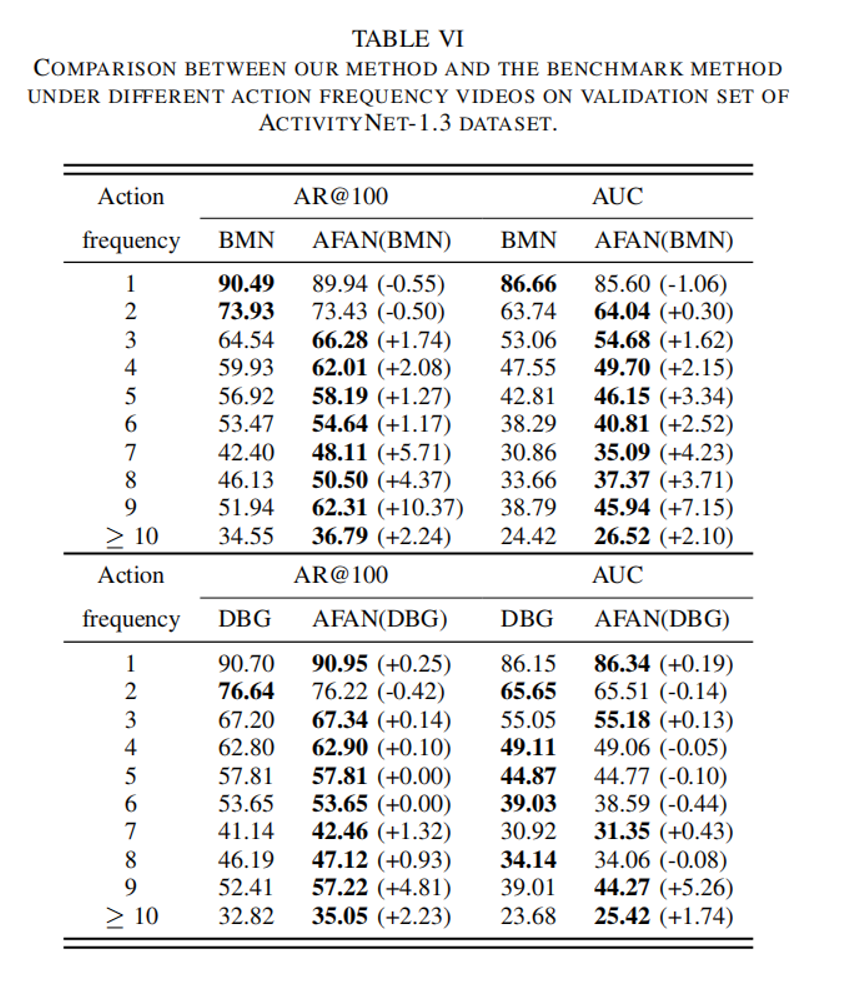
Comparison of performance on videos with different action frequencies
In addition, we analyze the performance on videos with different action frequencies and compare it with that of the corresponding benchmark method. Experimental results show that AFAN can effectively improve the performance on high-action-frequency videos. When AFAN mitigates data imbalance by weighted knowledge distillation, the performance of low-action-frequency videos (dominant in quantity) decreases but still maintains a high recall. As a result, AFAN maintains the high performance of the benchmark method on low-action-frequency videos while outperforming the benchmark method on high-action-frequency videos. Therefore, AFAN achieves better overall performance.
05 Summary and Prospects
This paper introduces AFAN for TAPG, which aims to locate human actions in untrimmed videos with high quality, and studies the variability of the action frequencies in untrimmed videos. Through data analysis, it is found that the existing methods are limited by data imbalance and short actions in high-frequency videos. Therefore, the LFE and FGP modules are designed to reduce the impact of data imbalance and short actions, respectively. Extensive experiments on four benchmark datasets demonstrate the effectiveness and generalizability of AFAN. Extensive experiments on four benchmark datasets demonstrate the effectiveness and generalizability of AFAN, which brings a new approach to the research of TAPG in videos and facilitates the application of TAPG in real-world scenarios.