Information Recovery-Driven Deep Incomplete Multi-view Clustering Network Based on MindSpore
Information Recovery-Driven Deep Incomplete Multi-view Clustering Network Based on MindSpore
Information Recovery-Driven Deep Incomplete Multi-view Clustering Network Based on MindSpore
August 9, 2023
Author: Li Ruifeng | Source: Zhihu
Paper title: Information Recovery-Driven Deep Incomplete Multiview Clustering Network
Source of the paper: IEEE Transactions on Neural Networks and Learning Systems
Paper URL: https://ieeexplore.ieee.org/document/10167670
Code URL: https://github.com/justsmart/Recformer-mindspore
As an open source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumer, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers account for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share a paper published by a team from Harbin University of Technology.
01 Research Background
Multi-view data depicts observation objects from different perspectives. Compared with conventional single-view data, this heterogeneous data retains multi-level and multi-dimensional semantic information. In recent years, as a novel representation learning method, multi-view clustering has aroused extensive research enthusiasm and has been widely used in related fields such as data analysis. Conventional multi-view clustering methods usually assume that complete multi-view data can be obtained, which however goes against practical experience. Therefore, a bunch of incomplete multi-view clustering approaches have been proposed to adapt to increasingly common incomplete multi-view data, which is also the focus of this paper. Incomplete multi-view data means that not all views in a sample are available, and there are random views missing. For example, in multi-view data including voice, text, and images, it is likely that any part of modals of some or all samples are unavailable.
For incomplete or missing views, a common idea is to avoid the negative effect of missing information on the premise of multi-view alignment. For example, introduce prior missing information to the deep network to help the model ignore the missing data during training. Another approach attempts to restore missing data based on the correlation of information between different views, which is more intuitive and challenging.
Based on MindSpore, the authors propose an information recovery-driven deep incomplete multi-view clustering network to address the above problems. This model achieves good multi-view clustering results while implementing missing view recovery.
02 Team Introduction
Liu Chengliang, PhD student at Harbin Institute of Technology (Shenzhen), first author
Wen Jie, assistant professor at Harbin Institute of Technology (Shenzhen), correspondent author, senior member of IEEE/CCF, winner of the China Boxin Program, author of over 60 CCF A/B papers (which have been cited more than 3100 times), with one paper won the AAAI Excellent Paper Award at the CCF A Conference.
Wu Zhihao, PhD student at Harbin Institute of Technology (Shenzhen)
Luo Xiaoling, PhD student at Harbin Institute of Technology (Shenzhen)
Huang Chao, assistant professor at Sun Yat-sen University (Shenzhen campus)
Xu Yong, professor at Harbin Institute of Technology (Shenzhen)
03 Introduction to the Paper
3.1 Method Motivation
Recovering missing data must be based on existing data. First, this needs to be considered from the key attributes of multi-view data. As we know, different views have the same high-level semantic information in the clustering task, that is, they are different descriptions of the same abstract target. If we can capture shared high-level semantic information, it is possible to infer missing information backwards based on the learned patterns. From another perspective, missing data inference can be regarded as a generation task, which is usually implemented through autoencoder networks. Inspired by the above analysis, the authors designed a cross-view autoencoder as the main framework, whose encoder learns advanced semantic representations and decoder attempts to recover missing views from fusion representations.
In addition, a large number of studies have proved that the internal structure of data is critical to unsupervised learning. The classical nearest neighbor graph constraint is widely used in various traditional machine learning methods. It enables the extracted semantic representation to maintain the original topology of data, which not only facilitates the learning of clustering structure to a large extent, but also drives the model to guess the missing data in a more reasonable direction. However, it should be noted that it is difficult to directly obtain a complete graph from the incomplete data unless we can provide approximately intact data. After re-examining the above motivations, it can be concluded that the idea to missing data restoration is fusing approximate graph construction and missing view recovery in a unified autoencoder framework.
The restored view needs to be evaluated in a downstream task. Therefore, the model training is divided into two stages:
Stage 1: restoring missing views
Stage 2: learning multi-view clustering representation based on recovered data
In stage 1, the autoencoder structure and inter-sample neighbor constraints are used to restore missing data. In stage 2, clustering fine-tuning is performed based on the restored data.
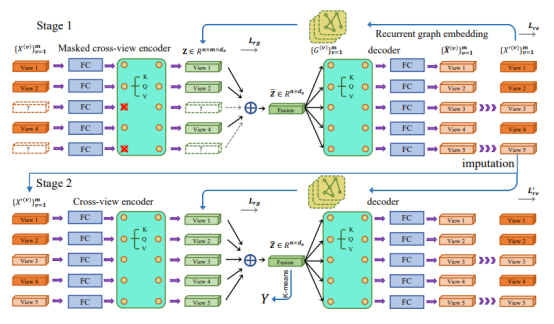
Figure 1 Main framework the model
3.2 Cross-view Encoder
The sources of multi-view features are diverse, and the original feature dimensions of each view are different. To facilitate tensor calculation of the deep network and map multiple views to the feature space of the same dimension, a multi-layer perceptron is allocated to each view to preliminarily extract the in-depth features of the original features. However, it is not enough to extract only the specific depth features of each view, because the complementary information between views is difficult to be fully mined. Therefore, the authors refer to the transformer module commonly used in processing sequence data, combine the in-depth features of multiple views into an unordered sequence data, input the data to the transformer, and use the self-attention mechanism to complete cross-view information interaction.
It should be noted that the input of the transformer encoder in stage 1 is oriented to incomplete data. Therefore, a mask mechanism is introduced to mask the impact of the missing view in the process of calculating the attention score, so that the attention score between views focuses only on the available views. Then, the output of the transformer encoder is fused into a feature by using a multi-view weighted fusion strategy, so that a fusion representation of multiple views of the sample is obtained. At this point, the encoding process ends, and accordingly, the authors design a set of symmetric decoders for restoring the fused representation to the original feature space. During decoding, features in missing views are no longer masked, so that the decoder preliminarily restores missing data according to a mapping from a fusion feature.
3.3 Recurrent Graph Constraints
In multi-view clustering fields, researchers have been accustomed to adding graph constraints to conventional multi-view learning methods, which helps preserve the original intrinsic structure of data by constructing a prior adjacency matrix. This is based on the basic manifold assumption that if two samples are close to each other in original feature space, then they are also close in the embedding space. However, when the data is incomplete, many existing methods directly skip the missing views to construct the adjacency graph, which inevitably causes deviation, especially on datasets with large loss rates. Therefore, it is expected to obtain an approximately complete adjacency graph to guide the encoder to extract advanced semantic features. On the other hand, more discriminative semantic features can also promote the recovery of missing views, thus helping to construct more complete adjacency graphs.
Based on the above, the authors innovatively propose the recurrent graph constraint, that is, the restored data is generated by the autoencoder, and then the adjacency graph generated based on the restored data is used to constrain the encoding and decoding process of the autoencoder. In this way, the generation of restored data and the adjacency graph constraint complement each other and promote each other.
04 Experiments
4.1 Incomplete Multi-View Dataset Settings
To evaluate the model performance, five popular multi-view datasets are adopted:
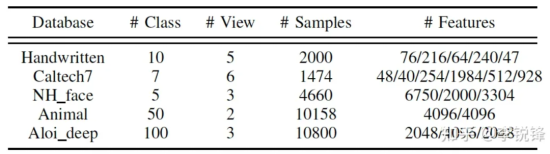
Table 1 Five popular multi-view clustering datasets
Preprocessing of incomplete datasets: To generate the incomplete datasets to simulate the missing-view case, in the paper, the authors randomly disable [10%, 30%, 50%, 70%] of the instances of each view but keep at least one view available for each sample. As for the Animal dataset with only two views, they randomly select [10%, 30%, 50%] of all samples as the paired samples with two views. The first view is removed for half of the remaining samples, and the second view is removed for the other half. In the experiments, all removed data is populated with 0 to hold its full shape.
4.2 Experimental Results Under Different Missing Rates
The following tables are experimental results on datasets with different missing rates.
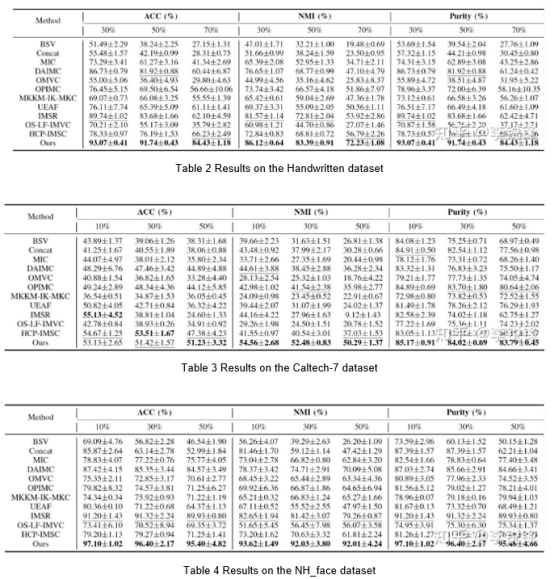
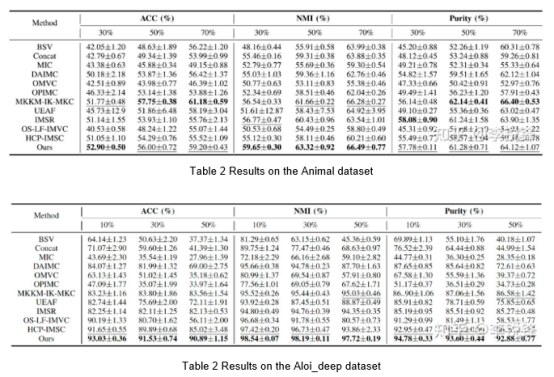
The results in Table 2 to Table 6 show that the approach proposed in the paper delivers relatively good clustering performance under different missing rates. In addition, it can be observed that higher missing rates lead to worse outcomes of incomplete multi-view clustering.
4.3 Visualization Results
Given that the Handwritten and NH_face datasets happen to have a view that is the grayscale value of the sample, the authors visualize the missing views and their recovery results, as shown in Figure 2.

Figure 2 Missing views and their recovery results on Handwritten and NH_face datasets
In this figure, the upper is the missing views (no model optimization involved), and the lower is the recovered views. After comparison, it can be seen that the restored view is very close to the original view, which means the model has a powerful view recovery capability.
After the feature space of final clustering representations is visualized via t-distributed stochastic neighbor embedding (t-SNE), it is proved that RecFormer boasts higher clustering performance than other state-of-the-art methods.
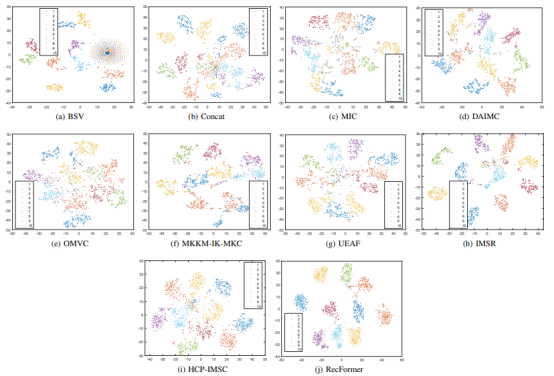
Figure 3 Feature space visualization of final clustering representations of different methods via t-SNE
05 Summary and Prospects
The approach of restoring missing views using adjacency graph constraints and autocoders can be easily extended to many incomplete learning frameworks and provide powerful view restoration capabilities. It can also be used for data augmentation to enrich incomplete multi-view data and improve incomplete multi-view clustering performance. This approach is implemented using MindSpore, whose diverse operator operations well satisfy algorithm requirements and detailed use descriptions further facilitate quick implementation of the algorithms.