MindSpore-based PLACO for Retail Automatic Check-Out, Improving Accuracy by 2.89%
MindSpore-based PLACO for Retail Automatic Check-Out, Improving Accuracy by 2.89%
Author: Li Ruifeng | Source: Zhihu
Paper Title
Prototype Learning for Automatic Check-Out
Source of the Paper
IEEE TMM
Paper URL
https://ieeexplore.ieee.org/document/10049664/
Code URL
https://github.com/msfuxian/PLACO
As an open-source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumer, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers account for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share the paper of the team led by Prof. Wei Xiushen, School of Compute Science and Engineering, Nanjing University of Science and Technology.
MindSpore aims to achieve three goals: easy development, efficient execution, and all-scenario coverage. The development of MindSpore has been characterized by rapid improvements with successive iterations, with its API design being more complete, reasonable, and powerful. To augment its convenience and power, several kits based on MindSpore have been developed. One such example is MindSpore Insight, which can present model architectures in graphs and dynamically monitor the changes of indicators and parameters during model execution, thereby simplifying the development process.
This blog mainly introduces object detection, which can be used to accurately detect retail commodities of different categories and quantities in an image, and finally generate a shopping list corresponding to "commodity category: commodity quantity". The code of object detection can refer to the cases in MindSpore official documents or the code and models related to object detection provided by the community.
01 Research Background
As a sub-field of the smart retail industry, the automatic check-out (ACO) of retail commodities is commonly used in areas where no cashier is available, such as supermarkets, stores, and convenience stores. In such an area, customers place their commodities on a counter. Then, a fixed-view camera acquires images of the commodities, and a vision system recognizes the commodity categories, counts the quantities of each category, and finally outputs a shopping list with prices.
The core task of ACO is to accurately identify and count commodities in the check-out images. However, the task faces three challenges, including large-scale data of commodity images, the domain gap between a single-commodity example and the check-out image, and the fine-grained characteristics of commodity categories. To address these challenges, Wei and his team proposed a baseline method based on object detection frameworks, which narrows the domain gap by synthesizing and rendering check-out images from the segmented single-category examples. Similarly, IncreACO, DPNet, and DPSNet have adopted and optimized this synthesized-and-rendered strategy to achieve better domain adaptability and improved ACO precision. In addition, S2MC2 uses a gradient reversal layer as a feature layer domain adaptation method to replace the synthesized-and-rendered strategy.
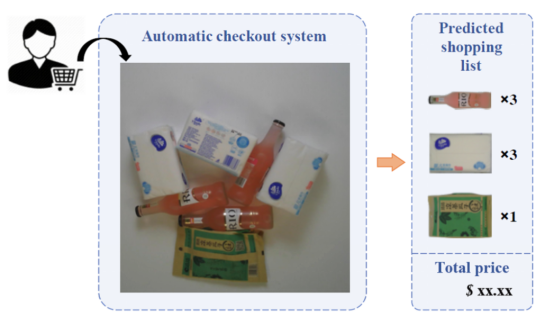
Figure 1. Basic idea of ACO
02 Team Introduction
The Visual Intelligence & Perception (VIP) Group, in charge of Professor Wei Xiushen, has published more than 50 papers at internationally known conferences and journals, such as several IEEE journals, Machine Learning Journal, NeurIPS, CVPR, ICCV, ECCV, IJCAI, and AAAI. The team has also won seven world championships in computer vision-related competitions, including IGIX 2023, SnakeCLEF 2022, iWildCam 2020, iNaturalist 2019, and Apparent Personality Analysis 2016.
03 Introduction to the Paper
In the paper, a novel method "Prototype Learning for Automatic Check-Out (PLACO)" is proposed to address the domain gap between single-commodity examples (as training data) and check-out images (as test data) through prototype learning consisting of prototype-based classifier learning and prototype alignment. For details about its architecture, see the following figure. Specifically, a prototype is a vector representation, or a category representation, which accurately represents category semantics in visual space, and is usually implemented by the feature center of a specific category. In addition to the potential to address the domain gap, another benefit of using commodity prototypes for ACO is that it can avoid the issue of multiple views of an individual commodity. Compared with single-view or mul-views sample images, the category prototype can more accurately represent the category semantics of a commodity, which also proves its generalization and robustness. Furthermore, a prototype alignment module is designed as the domain adaptation solution. After obtaining the commodity prototypes for the single-commodity and check-out domains, the authors reduced the distance between homogeneous prototypes and increased the distance between heterogeneous prototypes to enhance the intra-category compactness and inter-category sparsity, thereby achieving domain adaptation.
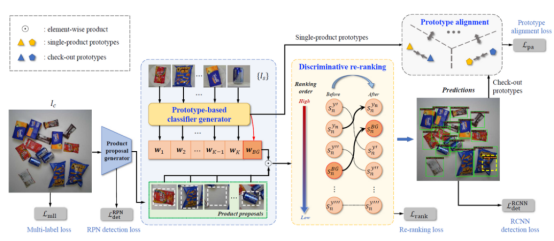
Figure 2. PLACO framework
To further improve the discriminative ability of learned classifiers, the authors have developed a re-ranking method that can adjust the predicted scores of commodities, as shown in Figure 3. Specifically, the authors have ranked the ground truth category as the highest to improve the prediction confidence while re-ranking the background score as the second highest due to the characteristics of the background classifier. This is how the hard re-ranking strategy works. In addition, considering the fine-grained characteristics of commodities, a slack variable is introduced as a soft re-ranking strategy to provide reasonable sorting possibilities for the predicted scores of those fine-grained commodities. Moreover, to further improve the ACO accuracy, a multi-label recognition loss is also added to PLACO for modeling co-occurrence of commodities in check-out images.
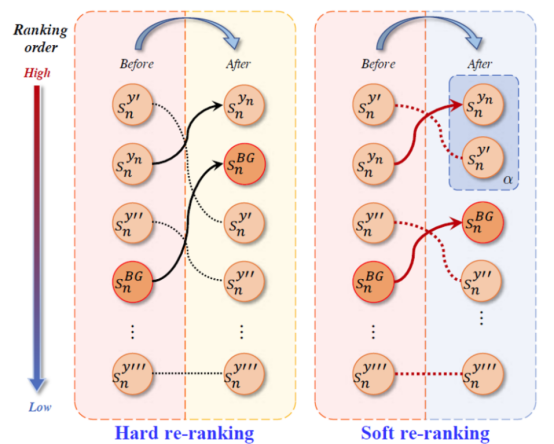
Figure 3. Diagrams of two discriminative re-ranking methods
04 Experiment Results
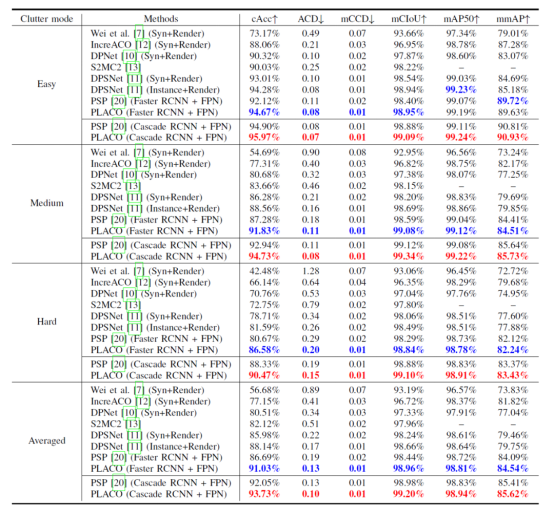
We have conducted seven ACO methods on the RPC dataset to compare their performance. Wei's method, IncreACO, DPNet, and DPSNet all use synthesized and rendered data for training on the backbone frameworks Faster R-CNN and Mask R-CNN. S2MC2 uses weaker point-level annotations for supervised training, which is a method of counting point-level objects based on density maps. PSP, demonstrated at conferences, is a simplified version of PLACO, while PLACO has an enhanced prototype alignment module. Both methods are conducted in the R-CNN and Cascade R-CNN frameworks. Since RPC data is divided into easy, medium, and hard levels according to the commodity category and quantity in the check-out images, the results of these three levels and the overall average results are displayed accordingly. According to the results, PLACO has achieved the most optimal results in both Faster R-CNN and Cascade R-CNN object detection frameworks, especially in the check-out accuracy (cAcc). In the results, ↑ indicates that the larger the value, the better the performance. ↓ indicates that the smaller the value, the better the performance. The best results based on the Faster R-CNN framework are marked in blue, and those based on the Cascade R-CNN are marked in red.
Table 1 Comparison results of seven ACO methods on the RPC dataset
05 Summary and Prospects
In the paper, a prototype learning method PLACO for automatic check-out is proposed, which includes a prototype-based classifier learning module, a discriminative re-ranking module, and a prototype alignment module. The prototype-based classifier learning module is developed to implicitly mitigate the domain gap between examples (as training data) and checkout images (as test data). In addition, the prototype alignment module is used as an explicit domain adaptation solution. Furthermore, a discriminative re-ranking method is designed to improve PLACO performance by bringing the discriminative ability into classifier learning and fine-grained categories. This paper also uses the multi-label loss to model the co-occurrence of commodities in check-out images. On the large-scale benchmark RPC dataset, PLACO achieved 91.03% ACO accuracy, 2.89% higher than the previous competing method. You are welcome to use cases provided in the official MindSpore documents and object detection code in the MindSpore community to experience the aforementioned method.