MindSpore-based Knowledge Graph Representation Learning Framework in Streaming Scenarios
MindSpore-based Knowledge Graph Representation Learning Framework in Streaming Scenarios
Author: Li Ruifeng | Source: Zhihu
Paper Title
StreamE: Lightweight Updates of Representations for Temporal Knowledge Graphs in Streaming Scenarios
Source of the Paper
SIGIR 2023
Paper URL
https://dl.acm.org/doi/10.1145/3539618.3591772
Code URL
https://github.com/zjs123/StreamE\_MindSpore
As an open-source AI framework, MindSpore offers a simplified, secure, reliable, and high-performance development process for device-edge-cloud collaboration and ultra-large-scale AI pre-training for the industry-university-research ecosystem. Since it was open sourced on March 28, 2020, it has garnered over 5 million downloads and has been the subject of hundreds of papers presented at premier AI conferences. Furthermore, MindSpore has a large community of developers and has been introduced in over 100 universities and 5000 commercial apps. Being widely used in scenarios such as AI computing centers, finance, smart manufacturing, cloud, wireless, datacom, energy, "1+8+N" consumer, and smart automobiles, MindSpore has emerged as one of the leading open-source software on Gitee. The MindSpore community extends a warm welcome to all who wish to contribute to open-source development kits, models, industrial applications, algorithm innovations, academic collaborations, AI-themed book writing, and application cases across the cloud, device, edge, and security.
Thanks to the support from scientific, industry, and academic circles, MindSpore-based papers account for 7% of all papers about AI frameworks in 2023, ranking No. 2 globally for two consecutive years. The MindSpore community is thrilled to share and interpret top-level conference papers and is looking forward to collaborating with experts from industries, academia, and research institutions, so as to yield proprietary AI outcomes and innovate AI applications. In this blog, I'd like to share the paper of the team led by Prof. Shao Jie, School of Computer Science and Engineering at the University of Electronic Science and Technology of China.
MindSpore aims to achieve three goals: easy development, efficient execution, and all-scenario coverage. The development of MindSpore has been characterized by rapid improvements with successive iterations, with its API design being more complete, reasonable, and powerful. To augment its convenience and power, several kits based on MindSpore have been developed. One such example is MindSpore Insight, which can present model architectures in graphs and dynamically monitor the changes of indicators and parameters during model execution, thereby simplifying the development process.
01 Research Background
The embedding methods of temporal knowledge graphs (TKGs) aim to learn the vector representations of elements in TKGs while preserving the temporal properties. Although existing methods are able to represent TKGs as low-dimensional vectors, they assume that no new knowledge will be added to the TKGs, which is clearly unrealistic. As knowledge in the real world is constantly updated, new knowledge will be continually added to knowledge graphs. This is referred to as a streaming scenario. There are three challenges that need to be addressed when applying existing methods to streaming scenarios.
(1) As knowledge graphs continue to evolve with new knowledge, the challenge lies in developing methods that can dynamically generate embedding representations for newly added entities, as existing methods typically rely on fixed entity embeddings.
(2) Frequent real-world events necessitate frequent updates of knowledge. But existing methods regenerate the current embedding representation from scratch at every moment, making it difficult to apply in real-world domains that require rapid response, such as crisis warning systems.
(3) Existing methods can only obtain entity embedding representations with relevant knowledge timestamps. However, in the real world, demands arise at any time, and existing methods will keep returning the same embedding representations until the next knowledge update occurs, leading to a model making the same response during a specific period, which is clearly unreasonable.
Therefore, while existing methods have achieved some successes, they are not suitable for streaming scenarios, which are prevalent in the real world, such as recommendation systems and crisis warning systems.
02 Team Introduction
Zhang Jiasheng, the lead author of this paper, is a second-year PhD student in the School of Computer Science and Engineering at the University of Electronic Science and Technology of China. His research primarily focuses on dynamic graph representation learning, TKG, and spatiotemporal data mining. Currently, he has authored five papers, comprising of two CCF A-class, one CCF B-class, and one CCF C-class conference papers, as well as one paper in a first-tier journal of the Chinese Academy of Sciences. Furthermore, he has filed three national invention patents and two software copyrights. He also led a critical research and implementation project on knowledge graph representation learning model guided by temporal knowledge and was recognized as a top talent in the talent development program of DiDi.
The paper mentor, Shao Jie, is a professor and doctoral tutor at the University of Electronic Science and Technology of China. He has published over 100 high-level academic papers in various journals (such as IEEE TKDE, IEEE TNNLS, IEEE TCYB, IEEE TMM, IEEE TGRS, IEEE THMS, IEEE TCSVT, ACM TOIS, and ACM TOMM) and conferences (such as ACM MM, IEEE ICDE, VLDB, IJCAI, and AAAI).
The Center for Future Media at the University of Electronic Science and Technology of China, to which the paper author belongs, has conducted extensive researches in the areas of multimodal knowledge graphs, TKGs, and knowledge graph construction, inference, and application.
03 Introduction to the Paper
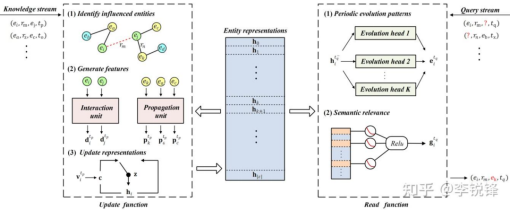
This paper proposes a lightweight embedding representation framework, StreamE, to address the challenge of previous TKG embedding methods unsuitable for streaming scenarios. The main reason why existing methods are difficult to adapt to streaming scenarios is that they highly couple the embedding generation process with the prediction process, which makes it difficult to efficiently generate embedding representations for any given time. Therefore, we decouple the above two processes to implement lightweight updates of embedding representations in streaming scenarios.
Specifically, we use entity embedding as an external storage module to preserve historical semantics, and decouple the process of generating embedding representations into update and read functions. In the update function, the framework listens to newly arrived knowledge and incrementally updates the stored embedding representations based on the new knowledge; in the read function, the framework listens to user query demands and generates embedding representations at query time based on embedding trace predictions, in order to correctly respond to the query demands.
In order to accurately update entity representations, we simultaneously consider the direct impact between the participating entities of new knowledge, as well as the spreading impact of new knowledge on entities involved in past relevant knowledge. Inspired by the message transmission mechanism, we believe that entities that generate knowledge also transmit information to each other. In addition, the semantics of relationships reflect the correlations between entities. Therefore, we use both entities and relationships for message transmission to model the direct impact. We propose that the paths formed by newly acquired knowledge and past related entities can effectively capture their correlations, thus contributing to the spreading impact. This is because paths are widely utilized to model high-order correlations between entities. Therefore, we model the spreading impact based on paths. Because the gating mechanism can adaptively choose information for updates, we utilize it to adaptively choose information from direct and spreading impacts to update the embedding representations of entities.
To accurately simulate the evolutionary trajectory of entity semantics, we focus on two aspects. First, most entities have periodic semantic characteristics, for example, the Olympic Games are held every four years and the European Cup is held every two years. Considering the periodic semantic changes of entities can help to better predict the knowledge that may occur in the future. Second, we find that an entity only generates knowledge with a subset of entities in the entire entity set, and these entities naturally have strong correlations. The future semantic trajectory of an entity should adapt to the semantic changes of its related entities to maintain the correlations.
04 Experimental Results
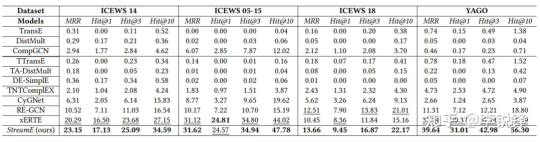
We have validated the effectiveness of the MindSpore-based StreamE framework in the inductive future link prediction tasks on four benchmark datasets. As shown in the figure below, the framework outperformed existing models on all datasets in terms of performance.
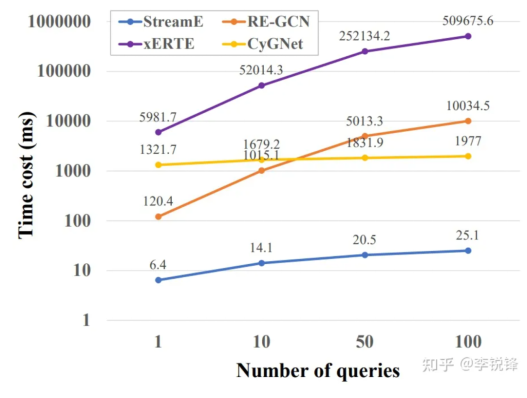
Meanwhile, we have validated the superiority of the proposed framework in terms of efficiency of generating embedding representations compared to existing models. As shown in the figure below, the framework can maintain sublinear growth in time consumption as the number of queries increases, which is significantly more efficient than existing models.
05 Summary and Prospects
We have conducted a novel study on the technical obstacles encountered by TKGs in streaming scenarios and put forward a lightweight framework called StreamE to update embedding representations in such scenarios. We implemented the StreamE framework using MindSpore and have demonstrated its advantages in efficiency and accuracy through extensive experimentation. As a China-made deep learning framework, MindSpore provides a large number of very useful operators, greatly simplifying the framework implementation process and showing great advantages in inference efficiency. The MindSpore community is highly engaged, and the valuable inputs from both users and Huawei developers have been instrumental in enhancing our framework. With such an active and skilled community, we are confident that MindSpore will continue to evolve and improve.