Feasibility of LLM Lifelong Learning through Mixture of Experts
Feasibility of LLM Lifelong Learning through Mixture of Experts
Three quarters after ChatGPT was released, people's sentiments regarding large language models (LLMs) have calmed down. The continuous innovation of open source communities and the releases of various Chat-LLMs by different vendors lead to concerns about the practicability of LLMs. LLM training is resource-consuming. Therefore, practices such as efficient pre-training, efficient parameter tuning, and lossless quantization have attracted wide attention, whether for cost reduction or environmental protection. But this time, we will look at a less popular but natural topic - LLM lifelong learning.
Continual Lifelong Learning
The concept of lifelong learning is simple. The goal of AI is to create human-like intelligent beings. Naturally, the AI models are expected to accept and learn new concepts instead of being trained and used only for one or several specific tasks. Like other learning paradigms, lifelong learning, or continual learning (CL), is actually a sub-domain of its own. However, it overlaps with many domains to a large extent. Here, I'd like to use a survey published in 2020 [1] to briefly introduce the concept of lifelong learning.
The objective of lifelong learning is to prevent a model from forgetting old knowledge while it continuously accepts and learns new data. The following table lists some properties and definitions of lifelong learning.
Property
Definition
Knowledge retention
The model is not prone to catastrophic forgetting.
Forward transfer
The model learns a new task while reusing knowledge acquired from previous tasks.
Backward transfer
The model achieves improved performance on previous tasks after learning a new task.
Online learning
The model learns from a continuous data stream.
No task boundaries
The model learns without requiring neither clear task nor data boundaries.
Fixed model capacity
Memory size is constant regardless of the number of tasks and the length of a data stream.
The survey also lists the properties of each learning paradigm and some common lifelong learning methods. Similarly, let's look at the properties of LLMs.
Property
Description
Knowledge retention
√
The LLM has world knowledge after pre-training. Small-scale fine-tuning is not likely to cause catastrophic forgetting, but resumable training based on large-scale data will.
Forward transfer
√
Zero-shot learning, few-shot learning, and fine-tuning are performed based on world knowledge.
Backward transfer
-
Fine-tuning may impact the performance of some tasks. The first performance of the fine-tuning will be lost after the second fine-tuning.
Online learning
×
The model is pre-trained and fine-tuned offline.
No task boundaries
√
Pre-training and fine-tuning are unsupervised, regardless of tasks.
Fixed model capacity
√
The size of the LLM remains unchanged after pre-training.
As shown in the preceding table, LLMs already have most of the lifelong learning properties. With sufficient pre-training, an LLM with tens of billions of models will have a large amount of world knowledge and emergent capabilities. This makes the LLM lifelong learning possible.
So what methods should be used for LLM lifelong learning? Common lifelong learning methods, including rehearsal, regularization, and architectural transformation, are not applicable to LLMs given the number of parameters and training mode. In this case, Mixture of Experts (MoE), which aims to increase the number of parameters and reduce inference costs, seems to be a new way for LLM lifelong learning.
Evolution of MoE
Vanilla MoE
MoE is a practical technology that was born more than 30 years ago. Early MoE was more like ensemble learning, that is, using multiple models to improve task performance. Many natural subsets in real-life data distribution, such as different domains, topics, languages, and modalities. When a single model is used for learning and the model capacity is small, different subsets are like noises that interfere with model fitting. As a result, model training is slow and generalization is difficult. The idea of MoE is to construct multiple models (each model is called an expert) and distribute data of different subsets to different models for training, preventing samples of different types from interfering with each other. The following figure shows the typical MoE network[2].
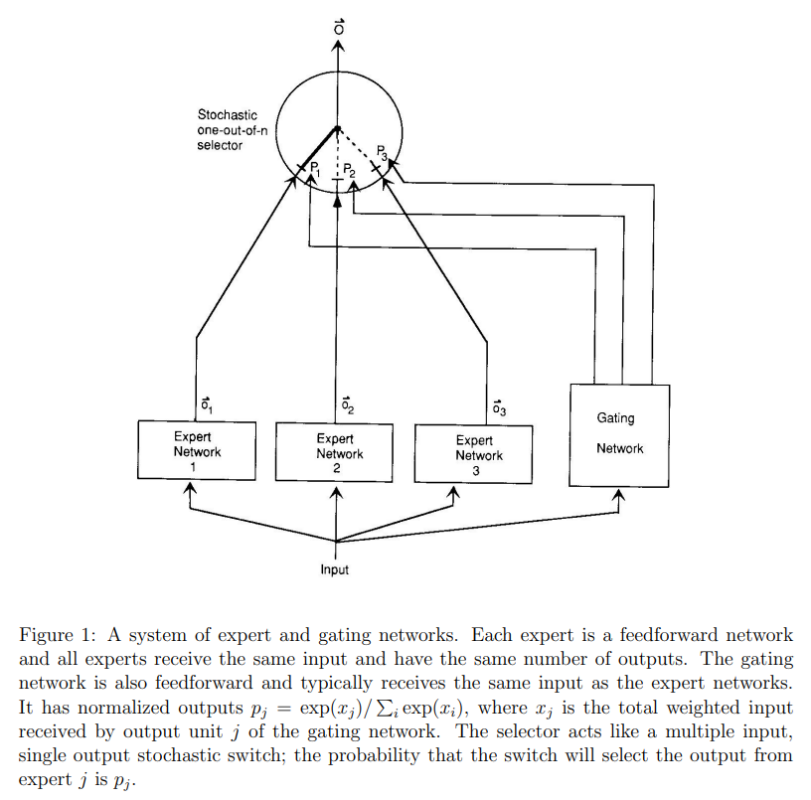


The MoE approach at that time was simple but effective, which inspired much subsequent MoE-related work. Whether experts compete or cooperate with each other and how the gating network allocates weights have become the directions of continuous iterations during the evolution of MoE. Fast forwarding to 2017, the prototype of the current MoE system emerged.
Sparse MoE
In the pre-Transformer era, it is difficult to build a large and deep recurrent neural network (RNN), and the hardware utilization is low. Shazeer, Noam, et al. of Google Brain [3] proposed a method of using the sparse MoE structure to expand the model capacity. That is, use a large number of experts for training and activate some of the experts for inference.
The vanilla MoE mentioned above wants one sample to be processed by one expert during training. Therefore, only a few experts are used during inference. In this way, a large number of computing resources can be saved. Sparse MoE is undoubtedly a very economical model training strategy. The following figure shows an example of sparse MoE.
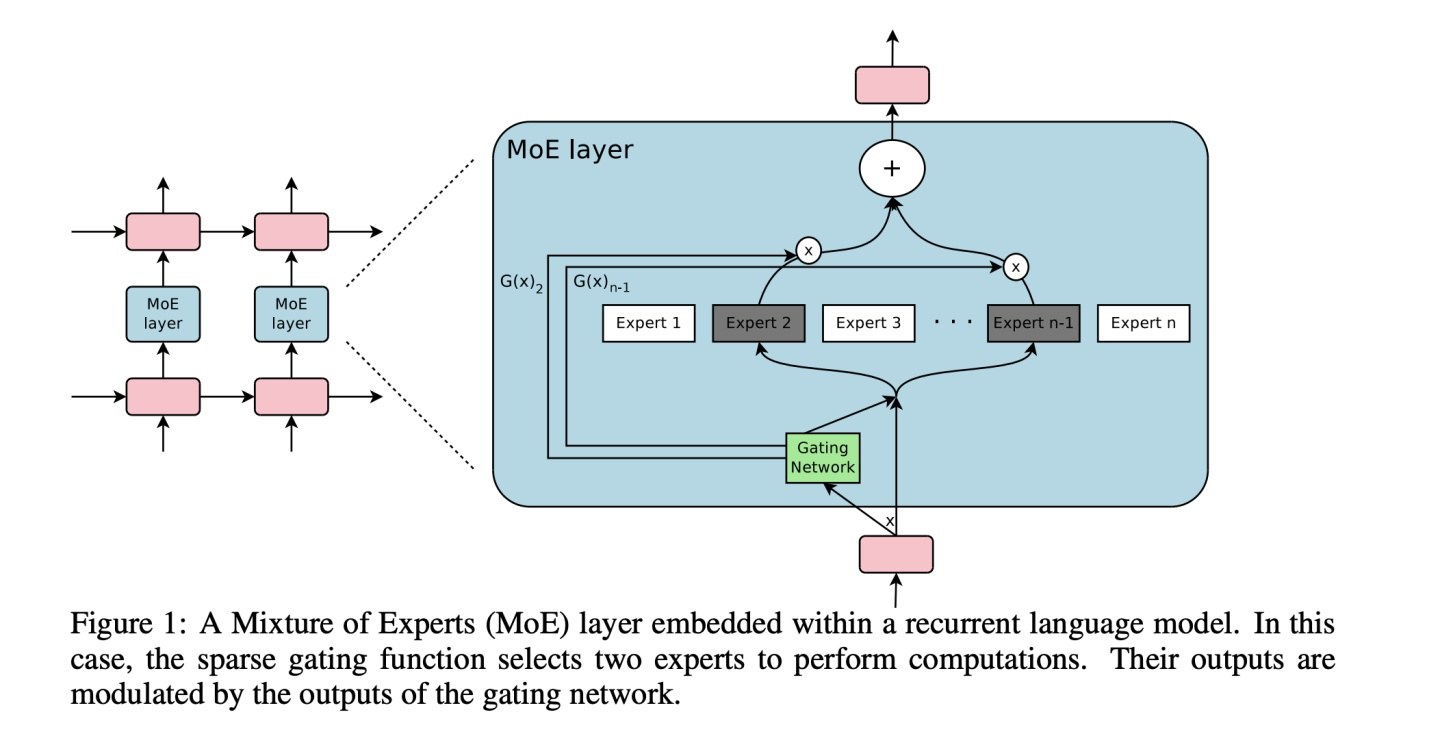
As shown in the figure, the model has n experts, and the gating network selects a few experts for calculation. In addition, this work found a major phenomenon that affected subsequent MoE research: the expert balancing problem, where the gating network tends to select experts that are numbered first during training so that only a few experts take effect. At that time, sparse MoE aimed to expand the model and perform training and inference economically and efficiently. In the same year, the emergence of Transformer that can be trained in parallel attracted everyone's attention, ushering in the era of foundation models.
Transformer MoE
Transformer is dominating in the NLP field: the Bidirectional Encoder Representations from Transformers (BERT) is winning awards, and the decoder-only GPT is shining in zero-shot learning. People are improving the structure and effect of Transformer and increasing the number of parameters of the model until it encounters the bottleneck of hardware resources.
When the number of model parameters reaches 100 billion, adding more parameters becomes more difficult. People turn to the economical and practical MoE again. Google proposed GShard [4], which is the first to extend the MoE idea to Transformer. Later, Switch Transformer [5] and GLaM [6] continue to improve the structure of Transformer MoE, pushing the number of LLM parameters from hundreds of billions to trillions.
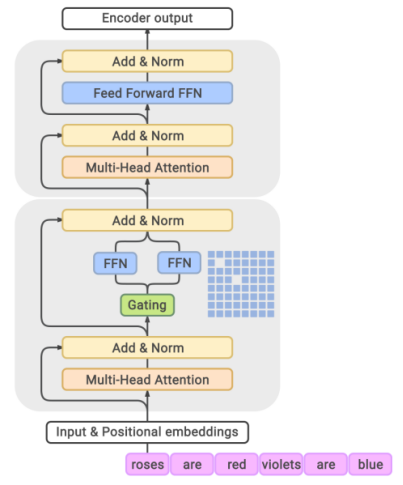
In the GLaM diagram above, every other feed-forward network layer in the encoder and decoder of Transformer is replaced with a position-wise Moe layer. The gating network uses a top-2 route to select the two experts with the highest probability.
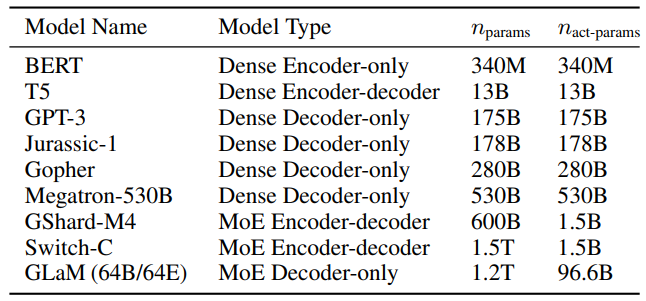
With the sparse activation capability of MoE, GLaM uses 1.2 trillion parameters during training but only 96 billion during inference, saving about half the resources compared with GPT3 and greatly improving the inference speed. A large number of subsequent LLMs with trillions of parameters choose the MoE approach. Rumor has it that GPT4 also uses a MoE structure. MoE has gradually become an important development direction of LLM.
MoE and Lifelong Learning
Now we've talked about the MoE, what's the relationship between MoE and lifelong learning? Let's go back to the goal of lifelong learning: the model keeps learning continuous information flows to obtain capabilities for various tasks. How do current LLMs achieve this goal? The answer is fine-tuning or resumable training. Although an LLM will not have the catastrophic forgetting problem caused by fine-tuning after it learns a large amount of world knowledge, both resumable training and secondary fine-tuning will reduce or even damage the backward transfer capability of the model.
Let's look back at the nature of lifelong learning. The only thing that LLM does not have is the backward transfer capability. Then we have a look at the characteristics of MoE:
1. Multiple experts process data of different distributions (domains or topics).
2. Only some experts are required for inference.
During continuous training of LLMs can experts be regularly added and removed to learn new knowledge and retain the model learned from old knowledge to achieve lifelong learning of LLMs? The answer is yes.
To achieve LLM lifelong learning, the following features must be implemented:
1. Continuous learning based on world knowledge. Actually, the MoE structure of current Transformer models is an intrusive reconstruction of the vanilla Transformer. Both FFN replacement and Dense+Sparse connection structure are to retain some original transformer structures to ensure that the underlying semantics can be maintained.
2. Pluggable experts. This is easy to understand. Old experts need to be removed when they are not required, and new experts need to be added.
3. Modifiable gating networks. Gating networks affects the routing of inputs. Therefore, when experts are removed, gating networks needs to be modified accordingly. Otherwise, random routing may completely mess up the results.
With these goals, we can analyze two works that have achieved LLM lifelong learning with completely different approaches.
Lifelong-MoE
The continuous evolution and integration of MoE and Transformer originate from Google. Naturally, Google leads the research on lifelong learning. Lifelong-MoE [7] was proposed in May this year. The idea is to freeze old experts and train new experts. The following figure shows the main structure of the model.
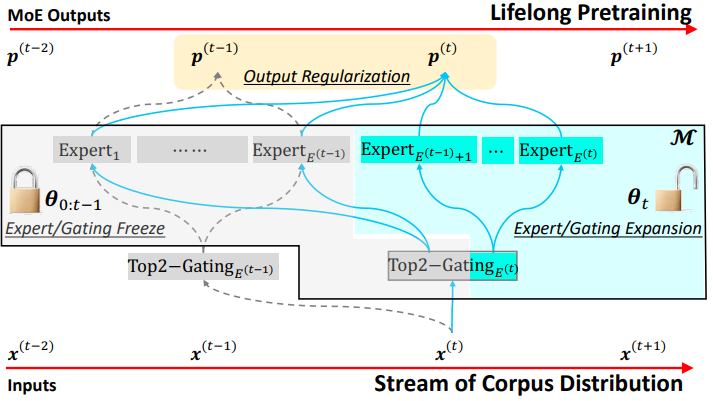
The lifelong learning policy of the model includes the following steps:
1. Increase the number of experts and the dimensions of the corresponding gating network.
2. Freeze the old experts and the corresponding dimensions of the gating network, and train only the new experts.
3. Perform output regularization to ensure that the new experts inherit the knowledge learned in the past.
This method can achieve several goals of LLM lifelong learning. However, because the gating network is also a neural network layer that can learn, regularization has to be performed to avoid catastrophic forgetting. However, this work lays a good foundation for LLM lifelong learning.
Another work is simpler: since a gating network that can learn is not suitable for modifiable experts, why not implement gating manually?
PanGu-Σ
PanGu-Σ [8], released in March this year, is a lifelong learning MoE model developed by Huawei Noah's Ark Laboratory based on the PanGu-alpha model. It proposes a random routing expert (RRE) method, so that the gating network can also be tailored with the experts. The following figure shows the PanGu-Σ structure.
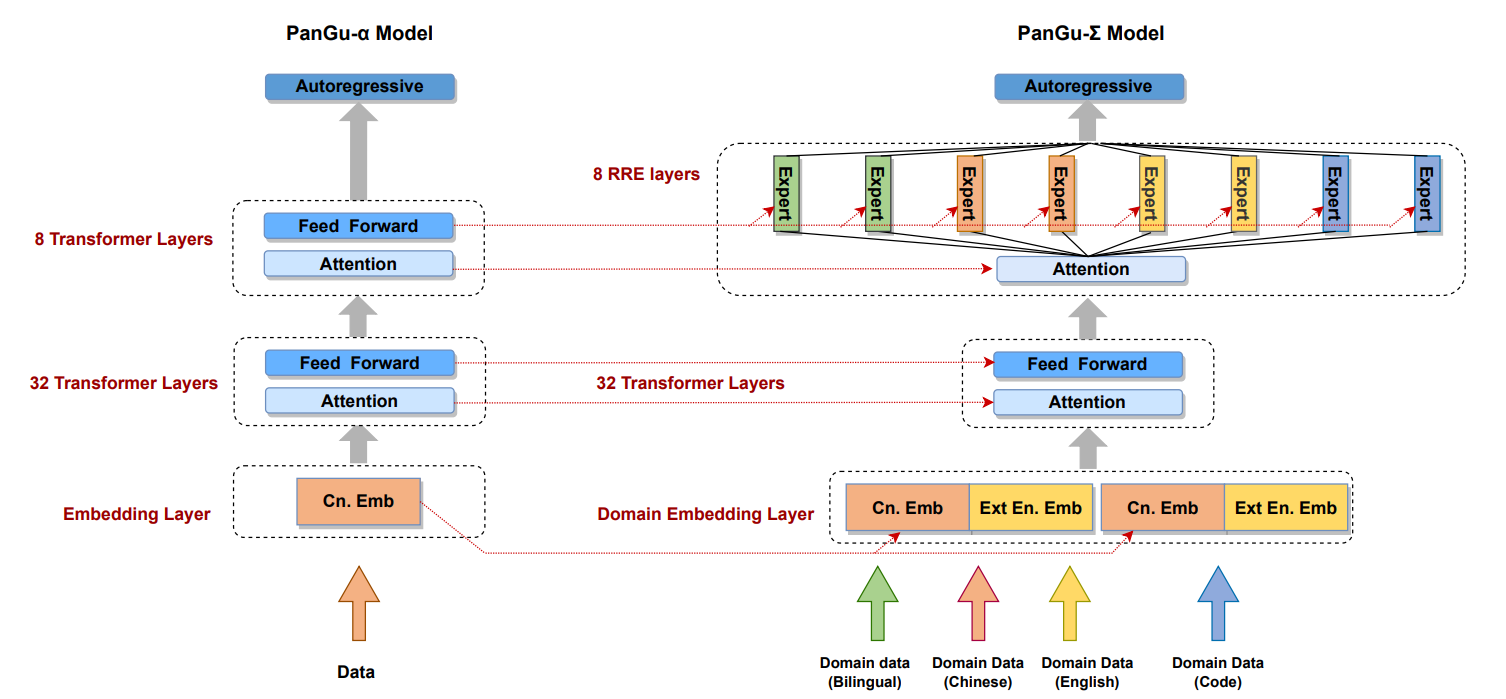
The RRE design is worth discussing. As mentioned above, since the gating network that can learn is difficult to tailor, we implement gating manually. This is exactly how REE does it, with a two-layer design for eliminating the domain boundaries (one of the properties of lifelong learning is no task boundaries, and manual gating violates this to some extent):
1. The first layer assigns tasks to different expert groups, each consists of multiple experts focusing on one task or domain.
2. The second layer performs group-wide random gating to balance the load of experts in an expert group.
The benefits are obvious. By splitting an expert group, we can obtain a submodel of a specific domain for inference and deployment. In addition, new expert groups can be continuously updated to implement lifelong learning. The following figure shows how to submodels are extracted from a pre-trained MoE model.
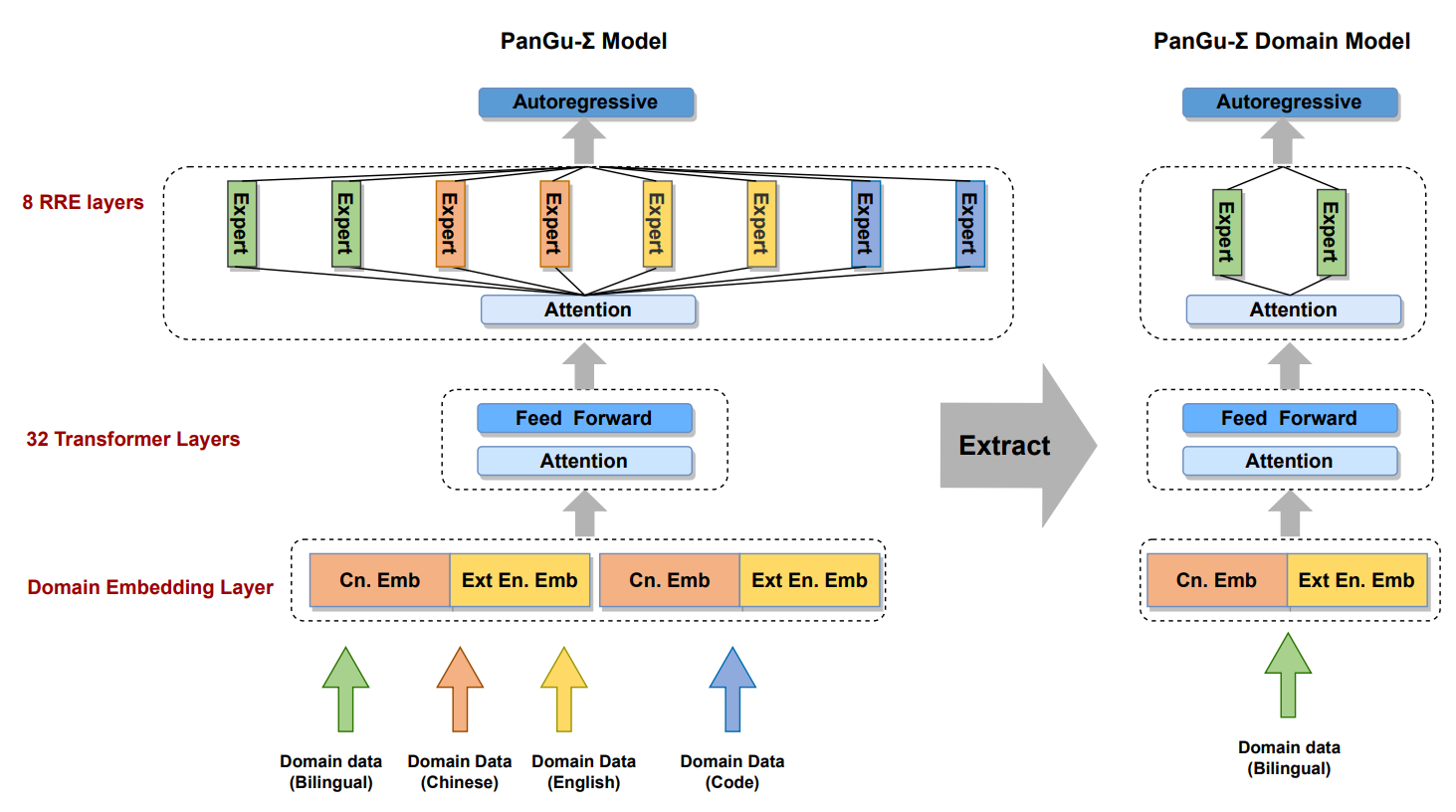
With this design, PanGu-Sigma can extract and deploy submodels as required. The number of submodel parameters is around tens of billions, achieving a balance between performance, efficiency, availability, and deployability.
Lifelong-MoE and PanGu-Sigma extend the LLM capabilities of Google and Huawei. Also, it is worth mentioning that MoE LLMs can be divided into two groups based on where the training starts: from scratch and from a pre-trained model. GPT4 is said to be a set of eight experts trained from scratch, which is like ensemble learning. It is more for business than the continuous evolution of LLMs.
Challenges of MoE
Lifelong-MoE looks promising but not perfect. The MoE method itself still has some problems. We can have a little discussion on the future direction of LLMs by looking at the problems faced by MoE. Many think that MoE is difficult to train, which is also related to these problems.
Structural Complexity of MoE
As mentioned above, the MoE of Transformer performs MoE extension on the FFN layer. However, the Transformer structure has the multi-head attention structure. As a result, the MoE extension becomes an intrusive modification of the Transformer structure. Both parallel intrusive modification before training and submodel extraction after training require a large amount of manpower due to the complex structure. It is foreseeable that few teams in academia can invest in the continuous research on LLM lifelong learning.
Expert balancing
Then, let's look at the defect of MoE, that is, the expert balancing problem. This problem can be attributed to two levels:
1. Imbalance caused by the laws of the physical world. Because of the Pareto principle, some tasks or domains will occupy most of data. Long-tail data is inevitable. Manual balancing through equal numbers of parameters and forcible balancing through random gating damage the model fitting of the real world.
2. The characteristics of neural networks determine that the winner takes all. The gating network, which can learn, tends to allocate data to experts with good fitting. This problem still requires a lot of and research.
Distributed Communication
The last is a practical system problem. Currently, LLM pre-training must be slitted using distributed parallelism. The difference between the MoE structure and the common dense models is that the MoE structure requires additional all-to-all communication to implement data gating and result retrieval. All-to-all communication sends data across nodes (servers) and pods (routers), causing a large number of communication congestions. How to efficiently implement all-to-all communication has become the focus of the evolution of many frameworks. For example, Tutel, DeepSpeed-MoE, Fast-MoE, and HetuMoE have implemented acceleration for all-to-all communication. MindSpore also adds hardware-coupled all-to-all communication optimization. However, the communication acceleration required by the MoE structure still needs to be continuously evolved and developed.
Prospects
LLMs has been a hot topic since the emergence of ChatGPT. Some even call them the fourth industrial revolution. I believe that both the industry and academia will continue to innovate and make breakthroughs in LLMs. LLM lifelong learning will definitely become a driving force of LLM development.
References
1. Biesialska M, Biesialska K, Costa-Jussa M R. Continual lifelong learning in natural language processing: A survey[J]. arXiv preprint arXiv:2012.09823, 2020.
2. JACOBS R, JORDAN M, NOWLAN S, et al. Adaptive Mixture of Local Expert[J/OL]. Neural Computation, 1991, 3: 78-88. https://doi.org/10.1162/neco.1991.3.1.79
3. SHAZEER N, MIRHOSEINI A, MAZIARZ K, et al. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer[M/OL]. arXiv, 2017[2023-08-15]. http://arxiv.org/abs/1701.06538
4. LEPIKHIN D, LEE H, XU Y, et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding[M/OL]. arXiv, 2020[2023-08-15]. http://arxiv.org/abs/2006.16668
5. FEDUS W, ZOPH B, SHAZEER N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity[J]. The Journal of Machine Learning Research, 2022, 23(1): 120:5232-120:5270.
6. DU N, HUANG Y, DAI A M, et al. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts[C/OL]//Proceedings of the 39th International Conference on Machine Learning. PMLR, 2022: 5547-5569[2023-08-15]. https://proceedings.mlr.press/v162/du22c.html
7. CHEN W, ZHOU Y, DU N, et al. Lifelong Language Pretraining with Distribution-Specialized Experts[M/OL]. arXiv, 2023[2023-08-15]. http://arxiv.org/abs/2305.12281
8. REN X, ZHOU P, MENG X, et al. PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing[M/OL]. arXiv, 2023[2023-08-15]. http://arxiv.org/abs/2303.10845