Training Deep Boltzmann Networks with Sparse Ising Machines
Training Deep Boltzmann Networks with Sparse Ising Machines
Introduction
The slowdown of Moore's law drives the development of non-traditional computing paradigms, such as specialized Ising machines customized to solving combinatorial optimization problems. This blog introduces new applications of probabilistic bit (p-bit)–based Ising machines in training deep generative neural networks. Using sparse, asynchronous, and highly parallel Ising machines, deep Boltzmann networks are trained in a hybrid probabilistic-classical computing setup.
Reference
Title: Training Deep Boltzmann Networks with Sparse Ising Machines Authors: Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
arXiv: 2303.10728 (2023)
Section 1
Key Ideas
Objective: Describe how to use a dedicated hardware system (such as p-bit) to effectively train sparse deep Boltzmann networks. In computationally hard probabilistic sampling tasks, these hardware systems provide orders of magnitude improvement over commonly used software implementations.
Long-term objective: Promote the development of physics-inspired probabilistic hardware to reduce the rapidly growing costs of traditional deep learning based on graphics and tensor processing units (GPUs/TPUs). Difficulties in hardware implementation: 1. Connected p-bits must be updated serially. Updates cannot be performed in dense systems. 2. The p-bit should receive all the latest information from its neighboring nodes before it is updated. Otherwise, the network does not sample from the true Boltzmann distribution.
Section 2
Topics
The training of deep Boltzmann networks using sparse Ising machines is divided into four parts: 1. Network structure 2. Target function 3. Parameter optimization 4. Inference (classification and image generation)
1. Network structure The Pegasus and Zepyhr topologies developed by D-Wave are used to train hardware-aware sparse deep networks. This operation is inspired by scaled but connectivity-limited networks (such as the human brain and advanced microprocessors). Although full connectivity is widely used in machine learning models, both advanced microprocessors with networks of billion transistors and the human brain show a large degree of sparsity. In fact, most hardware implementations of RBMs face scaling problems due to the large fan-out required at each node, while sparse connectivity in hardware neural networks usually display advantages. In addition, the sparse network structure solves the difficulties in hardware implementation mentioned before.
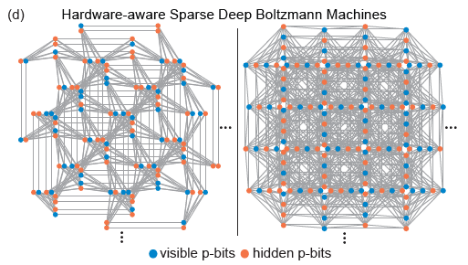
(Image source: arXiv:2303.10728)
2. Target functionMaximum likelihood function is equivalent to minimum KL divergence between the data and the model distributions:

3. Parameter optimization

Train network parameters based on algorithm 1, including:
Initialize the initialization parameters (J and h).
Assign values to the input layer p-bits using the training data, and perform MC sampling to obtain samples of data distribution.
Perform MC sampling to obtain samples of model distribution.
Estimate the gradients (called persistent contrastive divergence, PCD) using the samples obtained in two phases, and update the parameters using the gradient descent method.
In this process, MC sampling evolves iteratively using p-bits:
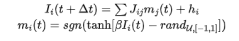
During the training of the sparse Boltzmann network, pay attention to the following two points:
(1) Randomized p-bits index
When a Boltzmann network model is trained on a given sparse network, the graph distance between visible, hidden, and label nodes becomes very important. Generally, if layers are fully connected, the graph distance between any given two nodes is a constant. However, this is not the case for sparse graphs. That's why the positions of visible, hidden, and label p-bits matter. If visible, hidden, and label p-bits are clustered and too close, the classification precision is greatly affected. This is likely because long graphic distance between the label bit and the visible bit weakens the correlation between the bits. This problem can be alleviated through p-bits index randomization.
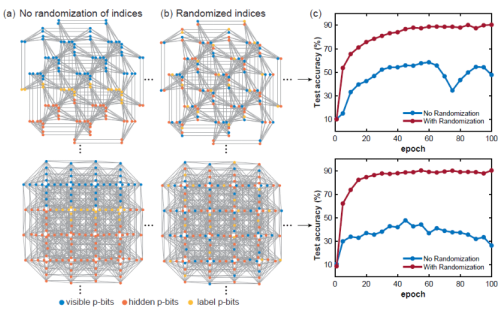
(Image source: arXiv:2303.10728)
(2) Massive parallelismOn the sparse deep Boltzmann networks, we use the heuristic graph-coloring algorithm DSatur to color the graph and update the unconnected p-bits in parallel.
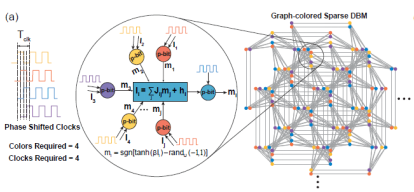
(Image source: arXiv:2303.10728)
4. Inference
Classification: Use the test data to fix visible p-bits, perform MC sampling, obtain the expected label p-bits, and use the label with the maximum expected value as the predicted label.
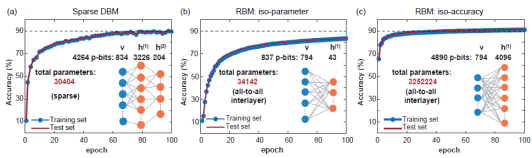
(Image source: arXiv:2303.10728)
Image generation: Fix the label p-bits is into the code corresponding to the label to be generated, and then perform MC sampling. During the sampling, the network is annealed (from 0 to 5 with a step of 0.125). Visible p-bits corresponding to the obtained sample are the generated image.

(Image source: arXiv:2303.10728)
Section 3Summary****
The presented paper uses a sparse Ising machine with a large-scale parallel architecture, which achieves a sampling speed of orders of magnitude faster than that of a traditional CPU. This paper systematically studies the mixing time of hardware-aware network topology, and demonstrates that the classification accuracy of models is not limited by the computational operability of the algorithm, but by the usable moderately sized Field Programmable Gate Arrays (FPGA). Further improvements may involve the use of deeper, broader, and possibly "harder to mix" network architectures, making full use of ultrafast probabilistic sampler. In addition, combining the traditional layer-by-layer training technique of DBMs with the method of the paper can bring further possible improvements. Nanodevices that can implement sparse Ising machines, such as stochastic magnetic tunnel junctions, may change the actual application status of deep Boltzmann networks.