MindSpore Case Study | AnimeGAN2 for Animation Style Transfer
MindSpore Case Study | AnimeGAN2 for Animation Style Transfer
Author: Zhang Tengfei | School: Tianjin University
Animation is a common art form in our daily life, widely used in advertising, movies, and kids education, among other fields. At present, animation production primarily depends on manual implementation, which is labor-intensive and requires highly specialized artistic skills. For animation artists, creating high-quality animation works requires careful consideration of lines, textures, colors, and shadows, making the whole process both challenging and time-consuming. Therefore, the automation technology capable of transforming real-life photos into high-quality animation-style images holds significant value. It not only enables artists to concentrate more on their creative work, but also simplifies the process for regular individuals to create their own animation works. This case provides a comprehensive explanation of the AnimeGAN model, including a detailed walkthrough of its algorithms and an analysis of its strengths and weaknesses in animation style transfer.
Model Overview
AnimeGAN is a study from Wuhan University and Hubei University of Technology. It combines neural style transfer with a generative adversarial network (GAN) to animate real-life images. This model was proposed in paper AnimeGAN: A Novel Lightweight GAN for Photo Animation. The generator is a symmetric encoding and decoding structure that comprises standard convolutions, depthwise separable convolutions, inverted residual blocks (IRBs), and upsampling and downsampling modules. The discriminator consists of standard convolutions.
Network Features
AnimeGAN has the following improvements:
1. The problem of high-frequency artifacts in generated images is solved.
2. The model is easy to train and can achieve the effect described in the paper.
3. The number of parameters of the generator network is further reduced (generator size now: 8.07 MB).
4. It uses high-quality style data from BD movies as much as possible.
Data Preparation
The dataset contains 6656 real landscape images and three animation styles: Hayao, Shinkai, Paprika. Each animation style is generated by randomly cropping video frames from the corresponding movie. In addition, the dataset also includes various sizes of images for testing purposes. The following figure shows the dataset information.

The following shows some images in the dataset.

After the dataset is downloaded and decompressed, its directory structure is as follows:

This model uses the VGG 19 network for image feature extraction and loss function calculation, so we need to load parameters of the pre-trained network.
After downloading the pre-trained VGG 19 network, place the vgg.ckpt file in the same directory as this file.
Data Preprocessing
Animation images with smooth edges are required for loss function calculation. The dataset mentioned above already contains such images. To create an animation dataset by yourself, you can use the following code to generate the required animation images with smooth edges:
from src.animeganv2_utils.edge_smooth import make_edge_smooth
# Animation image directory
style_dir = './dataset/Sakura/style'
# Output image directory
output_dir = './dataset/Sakura/smooth'
# Size of each output image
size = 256
# Smooth image. The output result is stored in the smooth folder.
make_edge_smooth(style_dir, output_dir, size)

Training Dataset Visualization
import argparse
import matplotlib.pyplot as plt
from src.process_datasets.animeganv2_dataset import AnimeGANDataset
import numpy as np
# Load parameters.
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='Hayao', choices=['Hayao', 'Shinkai', 'Paprika'], type=str)
parser.add_argument('--data_dir', default='./dataset', type=str)
parser.add_argument('--batch_size', default=4, type=int)
parser.add_argument('--debug_samples', default=0, type=int)
parser.add_argument('--num_parallel_workers', default=1, type=int)
args = parser.parse_args(args=[])
plt.figure()
# Load the dataset.
data = AnimeGANDataset(args)
data = data.run()
iter = next(data.create_tuple_iterator())
# Perform cyclic processing.
for i in range(1, 5):
plt.subplot(1, 4, i)
temp = np.clip(iter[i - 1][0].asnumpy().transpose(2, 1, 0), 0, 1)
plt.imshow(temp)
plt.axis("off")
Mean(B, G, R) of Hayao are [-4.4346958 -8.66591597 13.10061177]
Dataset: real 6656 style 1792, smooth 1792

Network Building
After data processing, let's build the network. According to the AnimeGAN paper, all model weights should be randomly initialized according to a normal distribution with mean of 0 and sigma of 0.02.
Generator
The function of generator G is to transform real-life photos into animation-style images. In practice, this is implemented by the convolution, depthwise separable convolution, IRBs, and upsampling and downsampling modules. The network architecture is as follows.
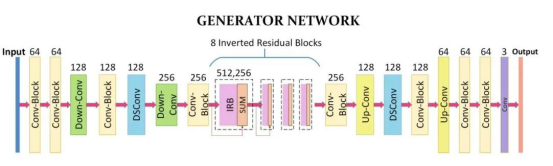
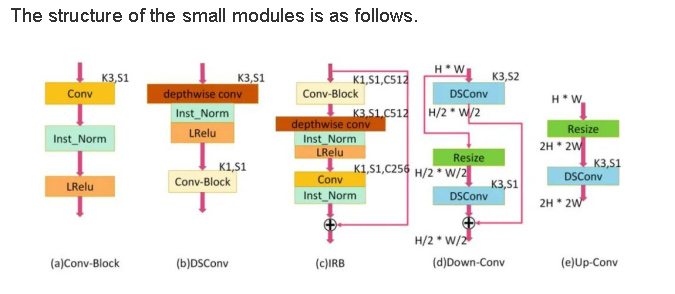
import os
import mindspore.nn as nn
from src.models.upsample import UpSample
from src.models.conv2d_block import ConvBlock
from src.models.inverted_residual_block import InvertedResBlock
class Generator(nn.Cell):
"""AnimeGAN network generator"""
def __init__(self):
super(Generator, self).__init__()
has_bias = False
self.generator = nn.SequentialCell()
self.generator.append(ConvBlock(3, 32, kernel_size=7))
self.generator.append(ConvBlock(32, 64, stride=2))
self.generator.append(ConvBlock(64, 128, stride=2))
self.generator.append(ConvBlock(128, 128))
self.generator.append(ConvBlock(128, 128))
self.generator.append(InvertedResBlock(128, 256))
self.generator.append(InvertedResBlock(256, 256))
self.generator.append(InvertedResBlock(256, 256))
self.generator.append(InvertedResBlock(256, 256))
self.generator.append(ConvBlock(256, 128))
self.generator.append(UpSample(128, 128))
self.generator.append(ConvBlock(128, 128))
self.generator.append(UpSample(128, 64))
self.generator.append(ConvBlock(64, 64))
self.generator.append(ConvBlock(64, 32, kernel_size=7))
self.generator.append(
nn.Conv2d(32, 3, kernel_size=1, stride=1, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=has_bias))
self.generator.append(nn.Tanh())
def construct(self, x):
out1 = self.generator(x)
return out1
Discriminator
Discriminator D is actually a binary network model that outputs the probability of determining that an image is a real-life image. It processes the image through a series of Conv2d, LeakyReLU, and InstanceNorm layers, and finally outputs the probability through a Conv2d layer.
import mindspore.nn as nn
from mindspore.common.initializer import Normal
class Discriminator(nn.Cell):
"""AnimeGAN network discriminator"""
def __init__(self, args):
super(Discriminator, self).__init__()
self.name = f'discriminator_{args.dataset}'
self.has_bias = False
channels = args.ch // 2
layers = [
nn.Conv2d(3, channels, kernel_size=3, stride=1, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=self.has_bias),
nn.LeakyReLU(alpha=0.2)
]
for _ in range(1, args.n_dis):
layers += [
nn.Conv2d(channels, channels * 2, kernel_size=3, stride=2, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=self.has_bias),
nn.LeakyReLU(alpha=0.2),
nn.Conv2d(channels * 2, channels * 4, kernel_size=3, stride=1, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=self.has_bias),
nn.InstanceNorm2d(channels * 4, affine=False),
nn.LeakyReLU(alpha=0.2),
]
channels *= 4
layers += [
nn.Conv2d(channels, channels, kernel_size=3, stride=1, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=self.has_bias),
nn.InstanceNorm2d(channels, affine=False),
nn.LeakyReLU(alpha=0.2),
nn.Conv2d(channels, 1, kernel_size=3, stride=1, pad_mode='same', padding=0,
weight_init=Normal(mean=0, sigma=0.02), has_bias=self.has_bias),
]
self.discriminate = nn.SequentialCell(layers)
def construct(self, x):
return self.discriminate(x)
Loss Function
The loss function includes the adversarial loss, content loss, grayscale style loss, and color reconstruction loss. Different losses have different weight coefficients. The overall loss function is expressed as follows:



import mindspore
from src.losses.gram_loss import GramLoss
from src.losses.color_loss import ColorLoss
from src.losses.vgg19 import Vgg
def vgg19(args, num_classes=1000):
"""Load the parameters of the pre-trained VGG19 model."""
# Build the network.
net = Vgg([64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512], num_classes=num_classes,
batch_norm=True)
# Load the model.
param_dict = load_checkpoint(args.vgg19_path)
load_param_into_net(net, param_dict)
net.requires_grad = False
return net
class GeneratorLoss(nn.Cell):
"""Connect the generator and loss function."""
def __init__(self, discriminator, generator, args):
super(GeneratorLoss, self).__init__(auto_prefix=True)
self.discriminator = discriminator
self.generator = generator
self.content_loss = nn.L1Loss()
self.gram_loss = GramLoss()
self.color_loss = ColorLoss()
self.wadvg = args.wadvg
self.wadvd = args.wadvd
self.wcon = args.wcon
self.wgra = args.wgra
self.wcol = args.wcol
self.vgg19 = vgg19(args)
self.adv_type = args.gan_loss
self.bce_loss = nn.BCELoss()
self.relu = nn.ReLU()
self.adv_type = args.gan_loss
def construct(self, img, anime_gray):
"""Construct the loss calculation structure of the generator."""
fake_img = self.generator(img)
fake_d = self.discriminator(fake_img)
fake_feat = self.vgg19(fake_img)
anime_feat = self.vgg19(anime_gray)
img_feat = self.vgg19(img)
result = self.wadvg * self.adv_loss_g(fake_d) + \
self.wcon * self.content_loss(img_feat, fake_feat) + \
self.wgra * self.gram_loss(anime_feat, fake_feat) + \
self.wcol * self.color_loss(img, fake_img)
return result
def adv_loss_g(self, pred):
"""Select a loss function type."""
if self.adv_type == 'hinge':
return -mindspore.numpy.mean(pred)
if self.adv_type == 'lsgan':
return mindspore.numpy.mean(mindspore.numpy.square(pred - 1.0))
if self.adv_type == 'normal':
return self.bce_loss(pred, mindspore.numpy.zeros_like(pred))
return mindspore.numpy.mean(mindspore.numpy.square(pred - 1.0))
Discriminator Loss
class DiscriminatorLoss(nn.Cell):
"""Connect the discriminator and loss function."""
def __init__(self, discriminator, generator, args):
nn.Cell.__init__(self, auto_prefix=True)
self.discriminator = discriminator
self.generator = generator
self.content_loss = nn.L1Loss()
self.gram_loss = nn.L1Loss()
self.color_loss = ColorLoss()
self.wadvg = args.wadvg
self.wadvd = args.wadvd
self.wcon = args.wcon
self.wgra = args.wgra
self.wcol = args.wcol
self.vgg19 = vgg19(args)
self.adv_type = args.gan_loss
self.bce_loss = nn.BCELoss()
self.relu = nn.ReLU()
def construct(self, img, anime, anime_gray, anime_smt_gray):
"""Construct the loss calculation structure of the discriminator."""
fake_img = self.generator(img)
fake_d = self.discriminator(fake_img)
real_anime_d = self.discriminator(anime)
real_anime_gray_d = self.discriminator(anime_gray)
real_anime_smt_gray_d = self.discriminator(anime_smt_gray)
return self.wadvd * (
1.7 * self.adv_loss_d_real(real_anime_d) +
1.7 * self.adv_loss_d_fake(fake_d) +
1.7 * self.adv_loss_d_fake(real_anime_gray_d) +
1.0 * self.adv_loss_d_fake(real_anime_smt_gray_d)
)
def adv_loss_d_real(self, pred):
"""Loss type of a real animation image"""
if self.adv_type == 'hinge':
return mindspore.numpy.mean(self.relu(1.0 - pred))
if self.adv_type == 'lsgan':
return mindspore.numpy.mean(mindspore.numpy.square(pred - 1.0))
if self.adv_type == 'normal':
return self.bce_loss(pred, mindspore.numpy.ones_like(pred))
return mindspore.numpy.mean(mindspore.numpy.square(pred - 1.0))
def adv_loss_d_fake(self, pred):
"""Loss type of the generated animation image"""
if self.adv_type == 'hinge':
return mindspore.numpy.mean(self.relu(1.0 + pred))
if self.adv_type == 'lsgan':
return mindspore.numpy.mean(mindspore.numpy.square(pred))
if self.adv_type == 'normal':
return self.bce_loss(pred, mindspore.numpy.zeros_like(pred))
return mindspore.numpy.mean(mindspore.numpy.square(pred))
Model Implementation
Due to the particularity of the GAN structure, its loss is the multi-output form of the discriminator and generator, which makes the GAN different from a common classification network. MindSpore requires that operations related to the loss function and optimizer be considered as subclasses of nn.Cell, so that you can customize the AnimeGAN class to connect the network and the loss function.
class AnimeGAN(nn.Cell):
"""Define the AnimeGAN network."""
def __init__(self, my_train_one_step_cell_for_d, my_train_one_step_cell_for_g):
super(AnimeGAN, self).__init__(auto_prefix=True)
self.my_train_one_step_cell_for_g = my_train_one_step_cell_for_g
self.my_train_one_step_cell_for_d = my_train_one_step_cell_for_d
def construct(self, img, anime, anime_gray, anime_smt_gray):
output_d_loss = self.my_train_one_step_cell_for_d(img, anime, anime_gray, anime_smt_gray)
output_g_loss = self.my_train_one_step_cell_for_g(img, anime_gray)
return output_d_loss, output_g_loss
Model Training
Training is divided into two parts: discriminator training and generator training. The discriminator is trained to improve the probability of discriminating real images to the greatest extent. The generator is trained to generate better fake animation images. Both can achieve the optimal results by minimizing the loss function.
import argparse
import os
import cv2
import numpy as np
import mindspore
from mindspore import Tensor
from mindspore import float32 as dtype
from mindspore import nn
from tqdm import tqdm
from src.models.generator import Generator
from src.models.discriminator import Discriminator
from src.models.animegan import AnimeGAN
from src.animeganv2_utils.pre_process import denormalize_input
from src.losses.loss import GeneratorLoss, DiscriminatorLoss
from src.process_datasets.animeganv2_dataset import AnimeGANDataset
# Load parameters.
parser = argparse.ArgumentParser(description='train')
parser.add_argument('--device_target', default='Ascend', choices=['CPU', 'GPU', 'Ascend'], type=str)
parser.add_argument('--device_id', default=0, type=int)
parser.add_argument('--dataset', default='Paprika', choices=['Hayao', 'Shinkai', 'Paprika'], type=str)
parser.add_argument('--data_dir', default='./dataset', type=str)
parser.add_argument('--checkpoint_dir', default='./checkpoints', type=str)
parser.add_argument('--vgg19_path', default='./vgg.ckpt', type=str)
parser.add_argument('--save_image_dir', default='./images', type=str)
parser.add_argument('--resume', default=False, type=bool)
parser.add_argument('--phase', default='train', type=str)
parser.add_argument('--epochs', default=2, type=int)
parser.add_argument('--init_epochs', default=5, type=int)
parser.add_argument('--batch_size', default=4, type=int)
parser.add_argument('--num_parallel_workers', default=1, type=int)
parser.add_argument('--save_interval', default=1, type=int)
parser.add_argument('--debug_samples', default=0, type=int)
parser.add_argument('--lr_g', default=2.0e-4, type=float)
parser.add_argument('--lr_d', default=4.0e-4, type=float)
parser.add_argument('--init_lr', default=1.0e-3, type=float)
parser.add_argument('--gan_loss', default='lsgan', choices=['lsgan', 'hinge', 'bce'], type=str)
parser.add_argument('--wadvg', default=1.7, type=float, help='Adversarial loss weight for G')
parser.add_argument('--wadvd', default=300, type=float, help='Adversarial loss weight for D')
parser.add_argument('--wcon', default=1.8, type=float, help='Content loss weight')
parser.add_argument('--wgra', default=3.0, type=float, help='Gram loss weight')
parser.add_argument('--wcol', default=10.0, type=float, help='Color loss weight')
parser.add_argument('--img_ch', default=3, type=int, help='The size of image channel')
parser.add_argument('--ch', default=64, type=int, help='Base channel number per layer')
parser.add_argument('--n_dis', default=3, type=int, help='The number of discriminator layer')
args = parser.parse_args(args=[])
# Instantiate the generator and discriminator.
generator = Generator()
discriminator = Discriminator(args.ch, args.n_dis)
# Set up two separate optimizers, one for D and the other for G.
optimizer_g = nn.Adam(generator.trainable_params(), learning_rate=args.lr_g, beta1=0.5, beta2=0.999)
optimizer_d = nn.Adam(discriminator.trainable_params(), learning_rate=args.lr_d, beta1=0.5, beta2=0.999)
# Instantiate WithLossCell.
net_d_with_criterion = DiscriminatorLoss(discriminator, generator, args)
net_g_with_criterion = GeneratorLoss(discriminator, generator, args)
# Instantiate TrainOneStepCell.
my_train_one_step_cell_for_d = nn.TrainOneStepCell(net_d_with_criterion, optimizer_d)
my_train_one_step_cell_for_g = nn.TrainOneStepCell(net_g_with_criterion, optimizer_g)
animegan = AnimeGAN(my_train_one_step_cell_for_d, my_train_one_step_cell_for_g)
animegan.set_train()
# Load the dataset.
data = AnimeGANDataset(args)
data = data.run()
size = data.get_dataset_size()
for epoch in range(args.epochs):
iters = 0
# Read data for each round of training.
for img, anime, anime_gray, anime_smt_gray in tqdm(data.create_tuple_iterator()):
img = Tensor(img, dtype=dtype)
anime = Tensor(anime, dtype=dtype)
anime_gray = Tensor(anime_gray, dtype=dtype)
anime_smt_gray = Tensor(anime_smt_gray, dtype=dtype)
net_d_loss, net_g_loss = animegan(img, anime, anime_gray, anime_smt_gray)
if iters % 50 == 0:
# Output training records.
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f' % (
epoch + 1, args.epochs, iters, size, net_d_loss.asnumpy().min(), net_g_loss.asnumpy().min()))
# After each epoch ends, use the generator to generate a group of images.
if (epoch % args.save_interval) == 0 and (iters == size - 1):
stylized = denormalize_input(generator(img)).asnumpy()
no_stylized = denormalize_input(img).asnumpy()
imgs = cv2.cvtColor(stylized[0, :, :, :].transpose(1, 2, 0), cv2.COLOR_RGB2BGR)
imgs1 = cv2.cvtColor(no_stylized[0, :, :, :].transpose(1, 2, 0), cv2.COLOR_RGB2BGR)
for i in range(1, args.batch_size):
imgs = np.concatenate(
(imgs, cv2.cvtColor(stylized[i, :, :, :].transpose(1, 2, 0), cv2.COLOR_RGB2BGR)), axis=1)
imgs1 = np.concatenate(
(imgs1, cv2.cvtColor(no_stylized[i, :, :, :].transpose(1, 2, 0), cv2.COLOR_RGB2BGR)), axis=1)
cv2.imwrite(
os.path.join(args.save_image_dir, args.dataset, 'epoch_' + str(epoch) + '.jpg'),
np.concatenate((imgs1, imgs), axis=0))
# Save the network model parameters as a CKPT file.
mindspore.save_checkpoint(generator, os.path.join(args.checkpoint_dir, args.dataset,
'netG_' + str(epoch) + '.ckpt'))
iters += 1
Mean(B, G, R) of Paprika are [-22.43617309 -0.19372649 22.62989958]
Dataset: real 6656 style 1553, smooth 1553

Model Inference
Run the following code and input a real-life landscape image into the network to generate an animation image:
import argparse
import os
import cv2
from mindspore import Tensor
from mindspore import float32 as dtype
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train.model import Model
from tqdm import tqdm
from src.models.generator import Generator
from src.animeganv2_utils.pre_process import transform, inverse_transform_infer
# Load parameters.
parser = argparse.ArgumentParser(description='infer')
parser.add_argument('--device_target', default='Ascend', choices=['CPU', 'GPU', 'Ascend'], type=str)
parser.add_argument('--device_id', default=0, type=int)
parser.add_argument('--infer_dir', default='./dataset/test/real', type=str)
parser.add_argument('--infer_output', default='./dataset/output', type=str)
parser.add_argument('--ckpt_file_name', default='./checkpoints/Hayao/netG_30.ckpt', type=str)
args = parser.parse_args(args=[])
# Instantiate the generator.
net = Generator()
# Obtain model parameters from the file and load them to the network.
param_dict = load_checkpoint(args.ckpt_file_name)
load_param_into_net(net, param_dict)
data = os.listdir(args.infer_dir)
bar = tqdm(data)
model = Model(net)
if not os.path.exists(args.infer_output):
os.mkdir(args.infer_output)
# Read and process images cyclically.
for img_path in bar:
img = transform(os.path.join(args.infer_dir, img_path))
img = Tensor(img, dtype=dtype)
output = model.predict(img)
img = inverse_transform_infer(img)
output = inverse_transform_infer(output)
output = cv2.resize(output, (img.shape[1], img.shape[0]))
# Save the generated image.
cv2.imwrite(os.path.join(args.infer_output, img_path), output)
print('Successfully output images in ' + args.infer_output)

Model inference results of each style:

Video Processing
In the following method, the format of the input video file is MP4. After the video is processed, the sound is not retained.
import argparse
import cv2
from mindspore import Tensor
from mindspore import float32 as dtype
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train.model import Model
from tqdm import tqdm
from src.models.generator import Generator
from src.animeganv2_utils.adjust_brightness import adjust_brightness_from_src_to_dst
from src.animeganv2_utils.pre_process import preprocessing, convert_image, inverse_image
# Load parameters. Set video_input and video_output to the actual input and output video paths, and select an inference model for video_ckpt_file_name.
parser = argparse.ArgumentParser(description='video2anime')
parser.add_argument('--device_target', default='GPU', choices=['CPU', 'GPU', 'Ascend'], type=str)
parser.add_argument('--device_id', default=0, type=int)
parser.add_argument('--video_ckpt_file_name', default='./checkpoints/Hayao/netG_30.ckpt', type=str)
parser.add_argument('--video_input', default='./video/test.mp4', type=str)
parser.add_argument('--video_output', default='./video/output.mp4', type=str)
parser.add_argument('--output_format', default='mp4v', type=str)
parser.add_argument('--img_size', default=[256, 256], type=list, help='The size of image: H and W')
args = parser.parse_args(args=[])
# Instantiate the generator.
net = Generator()
param_dict = load_checkpoint(args.video_ckpt_file_name)
# Read the video file.
vid = cv2.VideoCapture(args.video_input)
total = int(vid.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(vid.get(cv2.CAP_PROP_FPS))
codec = cv2.VideoWriter_fourcc(*args.output_format)
# Obtain model parameters from the file and load them to the network.
load_param_into_net(net, param_dict)
model = Model(net)
ret, img = vid.read()
img = preprocessing(img, args.img_size)
height, width = img.shape[:2]
# Set the resolution of the output video.
out = cv2.VideoWriter(args.video_output, codec, fps, (width, height))
pbar = tqdm(total=total)
vid.set(cv2.CAP_PROP_POS_FRAMES, 0)
# Process video frames.
while ret:
ret, frame = vid.read()
if frame is None:
print('Warning: got empty frame.')
continue
img = convert_image(frame, args.img_size)
img = Tensor(img, dtype=dtype)
fake_img = model.predict(img).asnumpy()
fake_img = inverse_image(fake_img)
fake_img = adjust_brightness_from_src_to_dst(fake_img, cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# Save the video file.
out.write(cv2.cvtColor(fake_img, cv2.COLOR_BGR2RGB))
pbar.update(1)
pbar.close()
vid.release()
Algorithm Process
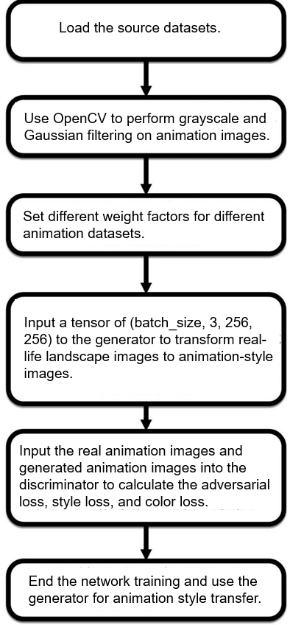
References
[1] Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2414-2423). [2] Johnson, J., Alahi, A., & Fei-Fei, L. (2016, October). Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision (pp. 694-711). Springer, Cham. [3] Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., & Yang, M. H. (2017). Diversified texture synthesis with feed-forward networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3920-3928). [4] Chen, Y., Lai, Y. K., & Liu, Y. J. (2018). Cartoongan: Generative adversarial networks for photo cartoonization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9465-9474). [5] Li, Y., Liu, M. Y., Li, X., Yang, M. H., & Kautz, J. (2018). A closed-form solution to photorealistic image stylization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 453-468).
For more MindSpore application cases, visit https://www.mindspore.cn/en.