Idea Sharing: Equivariant Neural Network and e3nn Math Library
Idea Sharing: Equivariant Neural Network and e3nn Math Library
Background
Over the past few years, artificial intelligence (AI) has played an increasingly important role in resolving traditional natural science problems, and has made remarkable achievements in answering some important scientific questions.
In physics, chemistry, biology and other disciplines, we often see objects with geometric features, like position vectors and force vectors. Equations that consist of these geometric objects do not depend on the choice of coordinate systems, which is defined by the principle of relativity in physics. What's behind these geometric features is the symmetry information of the system.
Therefore, how to keep these geometric features and symmetry in neural networks is key for AI applications in solving natural science problems. By model designing, the equivariant neural networks keep the geometric features and data equivariance throughout the process from input to output, and require less data and show better performance than traditional neural networks.
First, we briefly introduce the geometric tensor and equivariance.
1. Geometric Tensor and Equivariance
Let's start with the vector. The vector v→ is an abstract geometric object that has magnitude and direction, and can be graphically represented by an arrow. When we choose a coordinate system, the three-dimensional vector can be described by a coordinate (a set of numbers), as shown in Figure 1.
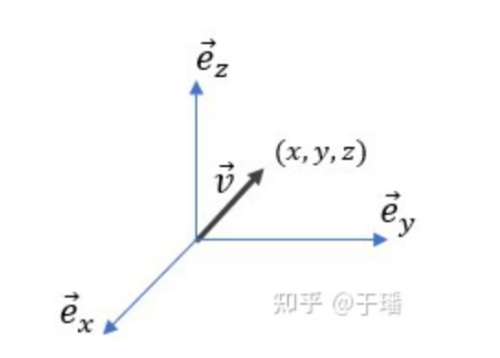
Figure 1: Vector in 3D space and coordinate
The rotation transformation g can be applied to the vector. After a coordinate system is chosen, a rotation matrix can be used to describe it. For example, rotating 30 degrees around the x-axis can be expressed as follows:
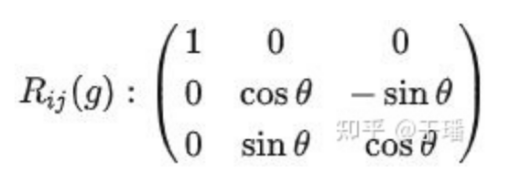
We can use matrix multiplication R_ij(g)v_j, for which Einstein notation is used here, to express the rotation transformation of vector v→.
Another spatial transformation is inversion transformation, in which a vector is called even when it remains unchanged and is called odd when the direction is reversed. For example, a position vector is reversed (odd) in inversion transformation, while a magnetic field intensity vector remains unchanged (even).
Geometric tensor can be regarded as an extension of the vector concept, which can satisfy a specific coordinate transformation relationship under spatial transformation (rotation and inversion). For example, a zero-order geometric tensor is a scalar and remains unchanged in spatial transformation; a first-order geometric tensor is a vector and is transformed in spatial transformation as described above; and a transformation relationship of a higher-order geometric tensor is more complex.
To supplement, preceding steps using a group of coordinates or matrices to represent abstract geometric tensors and transformations is the concept of representation in Mathematics. We will talk about it in detail.
Equivariance (Covariance in physics): The mapping f:X→Y is G equivariant, if for all g∈G, f(D_g^X(x))=D_g^Y(f(x)).
To put it simple, the equivariance of mapping means that the transformation of the input can be mapped to the output. If the input is a geometric tensor, the output will also be a geometric tensor.
2. Equivariant Neural Network
The equivariance as a constraint is added to traditional neural networks to form equivariant neural networks. Every operation taken by equivariant neural networks must be equivariant. Therefore, the entire network is an equivariant mapping.
In practical scientific computing problems, we often encounter various three-dimensional geometries. Specifically in chemistry, a structure of a molecule can be described by using atomic numbers [Z0, Z1, ...] and corresponding atomic coordinates [[x0,y0,z0],[x1,y1,z1], ...]. The desired information can be the potential energy of each atom [E0, E1, ...] or the atomic forces [[Fx0,Fy0,Fz0],[Fx1,Fy1,Fz1], ...], in which the atomic number and potential energy are scalars, and the atomic coordinates and forces are vectors.
If a molecule is rotated, the molecule and its properties should remain unchanged. In terms of data, the atomic numbers and potential energy remain unchanged, but the atomic coordinates and forces need to be changed (multiplied by the rotation matrix), which raises requirements on neural networks. There are three possible solutions:
(1) Mechanism-driven: Uses traditional computing methods, such as density function theory, to directly compute for the results through the underlying mechanism and symmetry requirements. Data is not required in this solution, results are completely fixed, and there is no generalization capability.
(2) Data-driven: Uses traditional neural networks, but needs to be augmented by lots of data. This solution inputs the data of molecules after each rotation and performs direct trainning through the network, the essence of which is for the neural network to learn the equivariance of molecules all by itself. This solution features of massive input data, huge network scale, and difficult training. The underlying mechanism is not required, results can be highly uncertain, and the generalization capability is strong.
(3) Mechanism and data integration: Uses equivariant neural networks and does not require lots of data for augmentation. This solution features small network scale, low result uncertainty, and strong generalization capability.
Equivariant neural networks show excellent effect in molecular property prediction and generation, and greatly reduce the amount of data required for predicting molecular potential energy.
For instances, Graphormer is a neural network that combines GNN and Transformer and won the championship in the Open Catalyst Challenge 2021. Equiformer is a neural network that combines equivariance, GNN, and Transformer. It reduces required data volume and the network model scale. Equiformer requires only 1/15 computing power of Graphormer while ensuring similar accuracy, significantly improving training efficiency.
It filters invalid outputs to improve accuracy and performance in molecular designing.
For another example, GeoDiff is a neural network that combines equivariance and Diffusion. It outperforms traditional diffusion neural networks in generalization and accuracy of molecular generation.
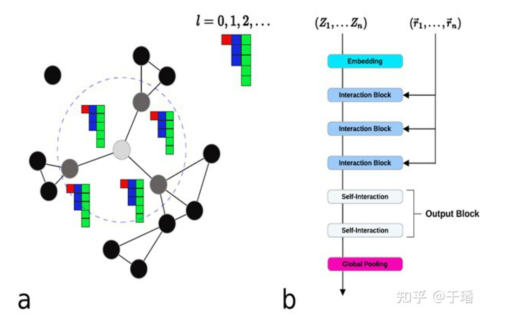
Figure 2: NeuqIP
NequIP is another predictive neural network that combines equivariance and GNN, in which higher-order geometric tensors are used. The reference article compares the geometric tensors of highest orders in terms of their impact on the result. As the order for geometric tensors in the network rises from 0 to 3, the accuracy of the predicted result is also significantly improved.
However, for such calculation that involves high-order geometric tensors, the calculation rules are much more complex than scalars and vectors, in which spherical harmonics functions and tensor products are key calculations. To put it simple, the spherical harmonics function can map a vector of spherical coordinate into a higher-order geometric tensor, while the tensor product is to multiply two geometric tensors to obtain a higher-order geometric tensor.
The e3nn math library is a math library that facilitates such high-order geometric tensor calculations. In the following, we will introduce some basic knowledge of group representation before we move on to geometric tensor calculations and building equivariant neural networks using e3nn.
3. Transformation Group and Representation
A group is an algebraic structure. A binary operation which is defined on a set meets the following requirements:
(1) The operation of two group elements is still a group element (closeness).
(2) There is a unit element.
(3) There is an inverse element, so that the operation of an element and its inverse element is a unit element.
(4) The associative property of operations is satisfied.
"nn" in e3nn refers to neural network, and "e3" refers to E(3), that is, a spatial transformation group of a three-dimensional Euclidean space, which can be divided into translation, rotation (SO(3) special orthogonal group), and inversion (Z2 second-order cyclic group).
The equivariance of translation has been satisfied in convolution. Therefore, we focus on rotation and inversion (SO(3) x Z2 = O(3)).
However, the group element, as a transformation operation, is an abstract object. To better study its properties and applications, we mathematically perform homomorphic mapping to an object that is more familiar, linear transformation, and its mathematical structure remains similar. This is group representation.
Group representation: All reversible linear transformations in linear space V form a group GL(V). Homomorphic mapping R:G→GL(V) is called a representation of group G in linear space V.
For example, when we describe a vector at the beginning of the blog, we select a coordinate system to represent the vector as a group of coordinates in a 3D linear space, and select a rotation matrix in the linear space to represent rotation transformation. Therefore, we can use matrix multiplication to obtain the result of the rotation transformation on the vector.
A representation of a matrix can be decomposed into a direct sum (block diagonal) of multiple irreducible submatrices, and we abstract this concept into the concept of representation: a reducible representation can be decomposed into a direct sum of multiple irreducible representations. When we know the properties of all the irreducible representations, we can obtain the information of the entire representation.
It is relatively simple to decompose the irreducible representation of the O(3) group. Each of the irreducible representations can be marked with (l, p), while l=0,1,2, ... is order, and p=e, o is the parity, and the dimension of the l order irreducible representation is 2l+1. Take a vector for example, if order is 1, and parity is odd, the vector can be denoted as 1o.
In neural networks, the status of irreducible representations of different orders is similar to that of different channels in convolutional neural networks (CNN).
For example, if the data whose length is 13 is represented as '1x2e+2x1o+2x0e', it means that the data can be decomposed into one (symmetric-traceless) second-order tensor, two vectors, and two scalars. The corresponding 13 x 13 spatial transformation matrix can be decomposed into a direct sum of one 5 x 5, two 3 x 3, and two 1 x 1 transformation submatrices.
4. Tensor Product
The tensor product of representation can be understood as a tensor product of a corresponding representation space.
In general, the tensor product of two representations is reducible, and the dimension can be obtained by multiplication.
Take the tensor product of two vectors as an example. If the dimension of the vector is 3, the dimension of the tensor product result is 9, which can be decomposed into a scalar (the dimension is 1), a pseudo vector (the dimension is 3), and a symmetric-traceless second-order tensor (the dimensions is 5).
1o⊗1o=0e⊕1e⊕2e
Each of the irreducible fraction of the tensor product of two irreducible representations can be calculated by the following formula:
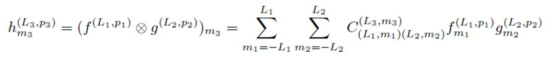
where C_{(L1,m1),(L2,m2)}^(L3,m3) is the Clebsch-Gordan coefficient.
In the preceding example, when only the scalar fraction of the tensor product is taken, it is the dot product of the vector. When only the vector fraction of the tensor product is taken, it is the cross product of the vector.
For the tensor product of reducible representation, we need to decompose it into irreducible representation first, and then multiply two irreducible representations in each group to obtain the irreducible representation of the tensor product.
To demonstrate it in graphics, on the upper left and right corners are the inputs of the two tensor products, and on the lower part of the graphic is the output. In the preceding example, the tensor product of the two vectors can be demonstrated by Figure 3 (left), and a more complex tensor product for a more general reducible representation can be demonstrated in Figure 3 (right).
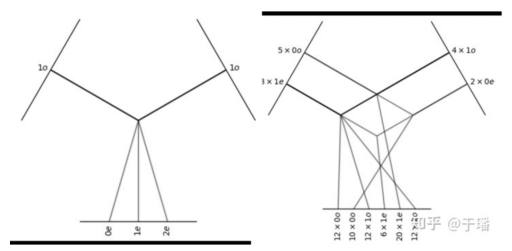
Figure 3: Tensor product
The e3nn math library provides a core calculation module for O(3) group representation, including irreducible representation, rotation transformation, spherical harmonics function, Wigner function (CG coefficient), and tensor product. In addition, it also provides equivariant network layers, such as equivariant activation layer, equivariant linear layer, and equivariant convolutional layer. By using an equivariant math library like e3nn, an equivariant neural network can be constructed more conveniently.
References
[1] Ying, Chengxuan, et al. "Do transformers really perform badly for graph representation?."Advances in Neural Information Processing Systems34 (2021): 28877-28888.
[2] Liao, Yi-Lun and Tess Smidt. "Equiformer: Equivariant graph attention transformer for 3d atomistic graphs."arXiv preprint arXiv:2206.11990(2022).
[3] Xu, Minkai, et al. "Geodiff: A geometric diffusion model for molecular conformation generation."arXiv preprint arXiv:2203.02923(2022).
[4] Batzner, Simon, et al. "E (3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials."Nature communications13.1 (2022): 1-11.
[5] Geiger, Mario, and Tess Smidt. "e3nn: Euclidean neural networks."arXiv preprint arXiv:2207.09453(2022).