MindSpore Case Study | Revolutionizing Image Inpainting for Programmers
MindSpore Case Study | Revolutionizing Image Inpainting for Programmers
Conventional image inpainting techniques are limited to processing low-resolution input images, and merely upsampling the low-resolution image inpainting results can only yield large and blurry outcomes. As is commonly understood, incorporating high-frequency residuals into a large and blurry image can enhance its details and textures. Building upon this concept, the paper Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting introduces a novel mechanism called Contextual Residual Aggregation (CRA), which involves adding contextual aggregated residuals to the upsampled inpainting result generated by a neural network, ultimately producing a refined final result.
This mechanism employs an Attention Transfer Module (ATM) to compute the aggregated residuals within a mask region using the contextual residuals and attention scores. Additionally, a Generative Adversarial Network (GAN) is established to perform low-resolution image prediction, thereby significantly reducing the memory usage and computing time. This paper presents additional techniques to enhance the quality and speed of inpainting, including attention score sharing, multi-scale attention transfer mechanism, and Lightweight Gated Convolution (LWGC). As a result, the model is capable of accurately inpainting a large image (up to 8K) with an irregular hole size of up to 25% at a high level of precision.
Environment Configuration
In this tutorial, we run the experiment in graph mode in a GPU environment.
from mindspore import context
# Select the graph execution mode and specify the training platform to GPU. If the Ascend platform is required, replace GPU with Ascend.
context.set_context(mode=context.GRAPH_MODE, device_target='GPU')
Data Preparation
We use the Places2 dataset with high-resolution images as the training dataset, which can be downloaded from the official website. The dataset contains more than 1.8 million 1024 x 1024 images, covering 443 classes of scenes.
The mask dataset consists of 100 images of masks. To dynamically generate irregular masks, you can simulate tears, scratches, and spots, or randomly manipulate the shape templates of real objects.
The inference data includes two groups of matched images and masks.
The training data contains 16 images and is stored in the /examples directory for the CRA.ipynb test.
Save the decompressed datasets to the CRA directory, whose structure is as follows.
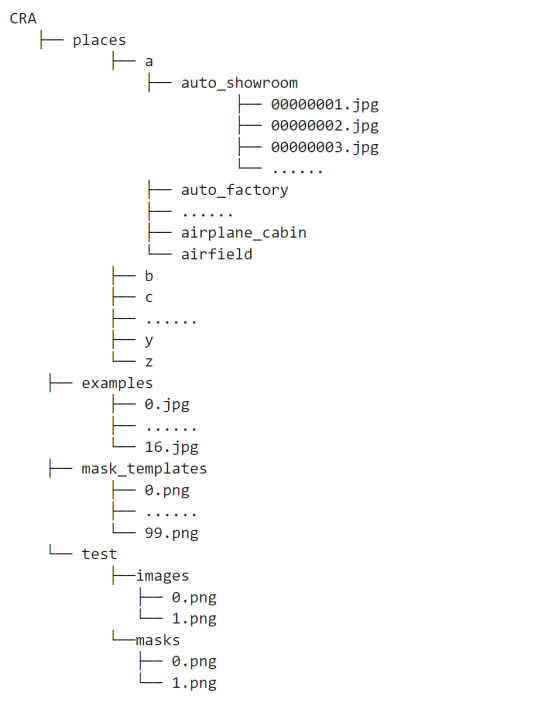
Data Processing
Places2 dataset: Define the InpaintDataset() class to read data, and randomly crop the images to 512 x 512 for normalization.
import os
import cv2
class InpaintDataset():
"""Process image dataset"""
def __init__(self, args):
self.args = args
self.imglist = self.get_files('./examples')
def get_files(self, path):
ret = []
for tuple_path in os.walk(path):
for filespath in tuple_path[2]:
ret.append(os.path.join(tuple_path[0], filespath))
return ret
def __len__(self):
return len(self.imglist)
def __getitem__(self, index):
img = cv2.imread(self.imglist[index])
h, w = self.args.IMG_SHAPE[0], self.args.IMG_SHAPE[1]
img = cv2.resize(img, (h, w))
img = img / 127.5 - 1
img = img.transpose((2, 0, 1))
return img
Mask dataset: Randomly select masks from the dataset, perform a series of data augmentation operations such as random horizontal flipping, rotation by a random angle, and random resizing by 0.8 to 1.0 times, and output a mask tensor with the size of [1, 1, 512, 512].
import random
import mindspore
import mindspore.ops as ops
import mindspore.dataset as ds
from mindspore import Tensor
from src.process_dataset.mask import get_files, read_masks, random_rotate_image, random_resize_image
def random_mask(args):
"""Process mask dataset"""
img_shape = args.IMG_SHAPE
height = img_shape[0]
width = img_shape[1]
path_list, n_masks = get_files('./mask_templates')
nd = random.randint(0, n_masks - 1)
path_mask = path_list[nd]
mask = read_masks(path_mask)
mask = ds.vision.c_transforms.RandomHorizontalFlip(prob=0.5)(mask)
scale = random.uniform(0.8, 1.0)
mask = random_rotate_image(mask)
mask = random_resize_image(mask, scale, height, width)
crop = ds.vision.c_transforms.CenterCrop((height, width))
mask1 = crop(mask)
mask_show = mask1
mask2 = Tensor.from_numpy(mask1)
mask3 = mask2.astype(mindspore.float32)
mask4 = mask3[:, :, 0:1]
mask5 = ops.ExpandDims()(mask4, 0)
mask6 = ops.Mul()(1 / 255, mask5)
mask = ops.Reshape()(mask6, (1, height, width, 1))
mask = ops.Transpose()(mask, (0, 3, 1, 2))
return mask, mask_show
Call InpaintDataset and GeneratorDataset to read the datasets, use create_dict_iterator to create a dataset iterator, and visualize the input images, masks, and images to be inpainted. Some training data is displayed as follows:
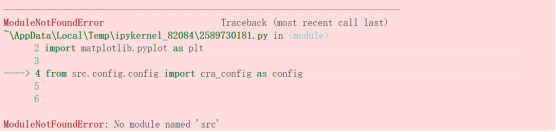
import numpy as np
import matplotlib.pyplot as plt
from src.config.config import cra_config as config
dataset_generator = InpaintDataset(config)
dataset = ds.GeneratorDataset(dataset_generator, ['image'])
dataset_size = len(dataset_generator)
total_batch = dataset_size // config.train_batchsize
dataset = dataset.batch(config.train_batchsize, drop_remainder=True)
dataset = dataset.create_dict_iterator(output_numpy=True)
dataset = next(dataset)
for i, image in enumerate(dataset['image']):
image = image[(2, 1, 0), :, :]
image = image.transpose(1, 2, 0)
mask, mask_show = random_mask(config)
mask = ops.Squeeze(0)(mask).asnumpy()
mask = mask.transpose(1, 2, 0)
real = image * (1-mask)
result = np.concatenate([image, mask_show, real], 1)
plt.subplot(8, 1, i+1)
plt.axis('off')
plt.imshow(result)
plt.show()
Model Architecture
After the data is loaded, we start to build the overall network model. Specifically, we utilize a GAN to predict the inpainting result of a low-resolution image; upsample the result to generate a blurry image of the same size as the original image; generate the high-frequency information of missing content by aggregating weighted high-frequency residuals of contextual patches; and finally add the aggregated residuals to the large, and blurry image to obtain a clear and complete inpainted image. Next, we will present a comprehensive overview of the network architecture, starting from its individual components and gradually building up to the complete system.
LWGC
After a comprehensive analysis of the limitations of common and partial convolutions in handling irregular hole regions, this paper employs Gated Convolution (GC) to construct convolutional layers for the model. This approach doubles the number of parameters and the processing time compared with common convolutions. Three modified versions of LWGC are proposed here, that is, depth-separable LWGC (LWGCds), pixelwise LWGC (LWGCpw), and single-channel LWGC (LWGCsc).
The output of the original GC can be expressed as follows:
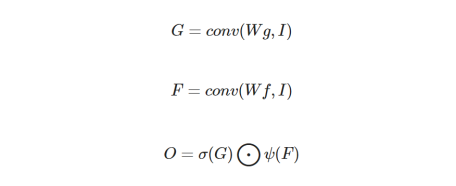
σ is the Sigmoid function. ψ is an activation function that is often set to ELU. Wg and Wf are two different sets of convolutional filters.
The three variants of LWGC differ in the computation of the gate branch G.

Here, we use LWGCsc on the generator's coarse network.
import mindspore.nn as nn
from mindspore.common.initializer import TruncatedNormal
class ScConv(nn.Cell):
"""Build LWGCsc Gate branch"""
def __init__(self, in_channel, kernel_size, stride, padding, dilation):
super(ScConv, self).__init__()
self.single_channel_conv = nn.Conv2d(in_channels=in_channel, out_channels=1, kernel_size=kernel_size,
stride=stride, pad_mode='same', padding=padding, dilation=dilation,
group=1, has_bias=True, weight_init=TruncatedNormal(0.05))
def construct(self, x):
x = self.single_channel_conv(x)
return x
Build gated convolutional layers with the nn.Conv2d common convolution.
class GatedConv2d(nn.Cell):
"""Build LWGCsc and LWGCds network layer"""
def __init__(self, in_channel, out_channel, kernel_size, stride, dilation, sc=False):
super(GatedConv2d, self).__init__()
self.activation = nn.ELU(alpha=1.0)
if sc:
self.conv2d = nn.Conv2d(in_channel, out_channel, kernel_size, stride, pad_mode='same', padding=0,
dilation=dilation, has_bias=True, weight_init=TruncatedNormal(0.05))
self.gate_factor = ScConv(in_channel, kernel_size, stride, 0, dilation)
else:
self.conv2d = nn.Conv2d(in_channel, out_channel, kernel_size, stride, pad_mode='same', padding=0,
dilation=dilation, has_bias=True, weight_init=TruncatedNormal(0.05))
self.gate_factor = DepthSeparableConv(in_channel, out_channel, stride, dilation)
self.sigmoid = nn.Sigmoid()
def construct(self, x):
gc_f = self.conv2d(x)
gc_g = self.gate_factor(x)
x = self.sigmoid(gc_g) * self.activation(gc_f)
return x
Attention Computing Module (ACM)
The attention score is computed based on the region affinity of a high-level feature map (denoted as P). P is divided into patches of a specific size and the ACM computes the cosine similarity between the patches inside and outside missing regions. The formula is as follows:
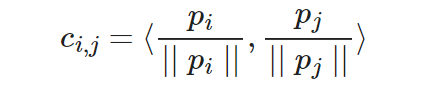
pi is the _i_th patch extracted outside the hole region in P, and pj is the _j_th patch extracted inside the hole region in P.
Apply Softmax on the similarity score to obtain the attention score of each patch in P:
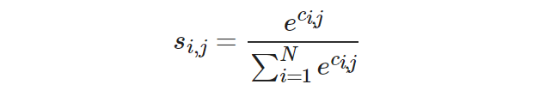
N is the number of patches outside the hole region in P. Our framework utilizes a 64 x 64 high-level feature map to compute the attention score. The patch size used for this computation is 3 x 3, and the resulting score is stored in the correspondence tensor.
from src.models.compute_attention import downsample, InitConv2d
class ContextualAttention(nn.Cell):
"""
Attention score computing module.
Args:
softmax_scale(int): scaled softmax for attention.
src(Tensor): input feature to match (foreground).
ref(Tensor): input feature for match (background).
mask(Tensor): input mask for ref, indicating patches not available.
Return:
out: Foreground area filled with context information
(It generally refers to the 64 * 64 feature map used to calculate attention scores).
correspondence: Attention score.
"""
def __init__(self, softmax_scale=10, fuse=True, dtype=mindspore.float32):
super(ContextualAttention, self).__init__()
self.softmax_scale = softmax_scale
self.fuse = fuse
self.dtype = dtype
self.reducesum = ops.ReduceSum(False)
self.unfold1 = nn.Unfold([1, 3, 3, 1], [1, 2, 2, 1], [1, 1, 1, 1], 'same')
self.unfold2 = nn.Unfold([1, 3, 3, 1], [1, 1, 1, 1], [1, 1, 1, 1], 'same')
self.transpose = ops.Transpose()
self.reshape = ops.Reshape()
self.pool1 = nn.MaxPool2d(16, 16, 'same', 'NCHW')
self.pool2 = nn.MaxPool2d(3, 1, 'same', 'NCHW')
self.maximum = ops.Maximum()
self.sqrt = ops.Sqrt()
self.square = ops.Square()
self.eye = ops.Eye()
self.reducemax = ops.ReduceMax(True)
self.greaterequal = ops.GreaterEqual()
self.pow = ops.Pow()
self.div = ops.Div()
self.softmax = nn.Softmax(1)
self.cat = ops.Concat(0)
self.conv1 = InitConv2d([3, 3, 128, 1024], 1, True)
self.conv2 = InitConv2d([3, 3, 1, 1], 1, True)
self.disconv1 = InitConv2d([3, 3, 128, 1024], 2, False)
def construct(self, src, ref, mask, method='SOFT'):
"""compute attention score"""
# get shapes
shape_src = src.shape
batch_size = shape_src[0]
nc = shape_src[1]
# raw features
raw_feats = self.unfold1(ref)
raw_feats = self.transpose(raw_feats, (0, 2, 3, 1))
raw_feats = self.reshape(raw_feats, (batch_size, -1, 3, 3, nc))
raw_feats = self.transpose(raw_feats, (0, 2, 3, 4, 1))
split = ops.Split(0, batch_size)
raw_feats_lst = split(raw_feats)
# resize
src = downsample(src)
ref = downsample(ref)
ss = src.shape
rs = ref.shape
src_lst = split(src)
feats = self.unfold2(ref)
feats = self.transpose(feats, (0, 2, 3, 1))
feats = self.reshape(feats, (batch_size, -1, 3, 3, nc))
feats = self.transpose(feats, (0, 2, 3, 4, 1))
feats_lst = split(feats)
# process mask
mask = self.pool1(mask)
mask = self.pool2(mask)
mask = 1 - mask
mask = self.reshape(mask, (1, -1, 1, 1))
y_lst, y_up_lst = [], []
offsets = []
fuse_weight = self.reshape(self.eye(3, 3, mindspore.float32), (3, 3, 1, 1))
for x, r, raw_r in zip(src_lst, feats_lst, raw_feats_lst):
r = r[0]
r = r / self.maximum(self.sqrt(self.reducesum(self.square(r), [0, 1, 2])), 1e-8)
r_kernel = self.transpose(r, (3, 2, 0, 1))
y = self.conv1(x, r_kernel)
if self.fuse:
# conv implementation for fuse scores to encourage large patches
yi = self.reshape(y, (1, 1, ss[2] * ss[3], rs[2] * rs[3]))
fuse_weight_kernel = ops.Transpose()(fuse_weight, (3, 2, 0, 1))
yi = self.conv2(yi, fuse_weight_kernel)
yi = self.transpose(yi, (0, 2, 3, 1))
yi = self.reshape(yi, (1, ss[2], ss[3], rs[2], rs[3]))
yi = self.transpose(yi, (0, 2, 1, 4, 3))
yi = self.reshape(yi, (1, ss[2] * ss[3], rs[2] * rs[3], 1))
yi = self.transpose(yi, (0, 3, 1, 2))
yi = self.conv2(yi, fuse_weight_kernel)
yi = self.transpose(yi, (0, 2, 3, 1))
yi = self.reshape(yi, (1, ss[3], ss[2], rs[3], rs[2]))
yi = self.transpose(yi, (0, 2, 1, 4, 3))
y = yi
y = self.reshape(y, (1, ss[2], ss[3], rs[2] * rs[3]))
y = self.transpose(y, (0, 3, 1, 2))
if method == 'HARD':
ym = self.reducemax(y, 1)
y = y * mask
coef = self.greaterequal(y, max(y, 1)).astype(self.dtype)
y = self.pow(coef * self.div(y, ym + 1e-04), 2)
elif method == 'SOFT':
y = (self.softmax(y * mask * self.softmax_scale)) * mask
y = self.reshape(y, (1, rs[2] * rs[3], ss[2], ss[3]))
if self.dtype == mindspore.float32:
offset = y.argmax(1)
offsets.append(offset)
feats = raw_r[0]
feats_kernel = self.transpose(feats, (3, 2, 0, 1))
y_up = self.disconv1(y, feats_kernel)
y_lst.append(y)
y_up_lst.append(y_up)
out, correspondence = self.cat(y_up_lst), self.cat(y_lst)
out = self.reshape(out, (shape_src[0], shape_src[1], shape_src[2], shape_src[3]))
return out, correspondence
Multi-Scale Attention Transfer and Score Sharing (ATM)
After the attention scores are computed from the high-level feature map P, the missing content in the lower-level feature map (P__L) can be filled with the weighted contextual patches by using the attention scores.
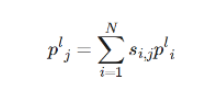
l ∈ 1, 2, 3 corresponds to network layers whose feature map sizes are 64, 128, and 256 respectively. P__l__i is the _i_th patch extracted outside the hole region, and P__l__j is the _j_th patch extracted inside the hole region. N indicates the number of patches divided in the background region. Because the size of a feature map varies from layer to layer, the size of patches divided at each layer should change accordingly.
In the paper framework, the same set of attention scores (correspondence) is applied to different feature maps multiple times to implement attention transfer. The sharing of attention scores reduces network parameters and improves computational efficiency.
class ApplyAttention(nn.Cell):
"""
Attention transfer module(used for training)
(It generally used for 128 * 128 / 256 * 256 feature map).
Args:
shp(list): the shape of input feature map.
shp_att(list): the shape of attention score.
Return:
out: Feature map filled by attention transfer module.
"""
def __init__(self, shp, shp_att):
super(ApplyAttention, self).__init__()
self.shp = shp
self.shp_att = shp_att
self.rate = self.shp[2] // self.shp_att[2]
self.kernel = self.rate * 2
self.batch_size = self.shp[0]
self.sz = self.shp[2]
self.nc = self.shp[1]
self.unfold = nn.Unfold([1, self.kernel, self.kernel, 1], [1, self.rate, self.rate, 1], [1, 1, 1, 1], 'same')
self.transpose = ops.Transpose()
self.reshape = ops.Reshape()
self.split = ops.Split(0, self.batch_size)
self.disconv1 = InitConv2d([8, 8, 64, 1024], self.rate, False)
self.disconv2 = InitConv2d([16, 16, 32, 1024], self.rate, False)
self.concat = ops.Concat(0)
self.conv_pl2 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 1),
GatedConv2d(64, 64, 3, 1, 2)
)
self.conv_pl1 = nn.SequentialCell(
GatedConv2d(32, 32, 3, 1, 1),
GatedConv2d(32, 32, 3, 1, 2)
)
def construct(self, x, correspondence):
"""apply attention on training"""
raw_feats = self.unfold(x)
raw_feats = self.transpose(raw_feats, (0, 2, 3, 1))
raw_feats = self.reshape(raw_feats, (self.batch_size, -1, self.kernel, self.kernel, self.nc))
raw_feats = self.transpose(raw_feats, (0, 2, 3, 4, 1))
raw_feats_lst = self.split(raw_feats)
ys = []
correspondence = self.transpose(correspondence, (0, 2, 3, 1))
att_lst = self.split(correspondence)
for feats, att in zip(raw_feats_lst, att_lst):
feats_kernel = self.transpose(feats[0], (3, 2, 0, 1))
att = self.transpose(att, (0, 3, 1, 2))
if self.shp[2] == 128:
y1 = self.disconv1(att, feats_kernel)
ys.append(y1)
elif self.shp[2] == 256:
y2 = self.disconv2(att, feats_kernel)
ys.append(y2)
else:
print('Value Error')
out = self.concat(ys)
if self.shp[2] == 128:
out = self.conv_pl2(out)
elif self.shp[2] == 256:
out = self.conv_pl1(out)
else:
print('conv error')
return out
Overall Pipeline of CRA
Take a high-resolution input image and downsample it to 512 x 512 to create a low-resolution image. Then, upsample the low-resolution image to produce a blurry image (low-frequency component) with the same size as the original input. The generator obtains the low-resolution image and inpaints it. At the same time, the ACM of the generator computes the attention score.
To obtain the final inpainting result of the hole region, start by computing the contextual residuals of the image by subtracting the blurry low-frequency component from the original input. Next, compute the aggregated residuals in the hole region using the context residuals and attention scores through the ATM. Finally, add the aggregated residuals to the upsampled image inpainting result. Note that the region outside the hole should still use the original input. The following figure shows the overall process of the CRA mechanism.
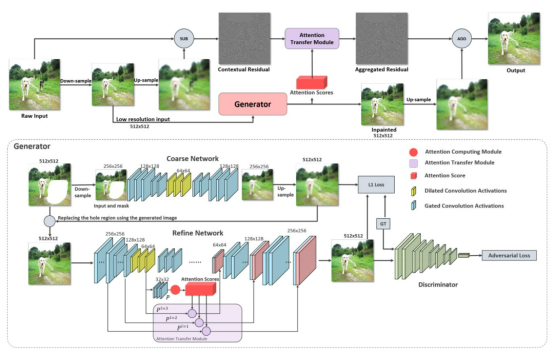
Generator
The generator adopts a two-stage coarse-to-fine network architecture, in which the coarse network generates a rough effect of image inpainting, and the fine network predicts a finer result. The generator takes the original image and mask as inputs to generate a complete inpainted image. The input and output sizes are 512 x 512. To expand the perceptive fields and reduce computation, inputs are downsampled to 256 x 256 before convolution on the coarse network. For inputs to the fine network, the input hole region is replaced with the corresponding region on the coarse network.
The fine network uses a high-level feature map to compute the contextual attention score and performs attention transfer on multiple lower-level feature maps. The paper also uses dilated convolutions in both the coarse and fine networks to further expand the size of the perceptive fields. In addition, to improve computational efficiency, LWGC is applied to all layers of the generator. Batch Normalization (BN) processing has been uniformly removed from the network convolutional layers, padding processing is done using the 'same' mode, and the activation functions for convolutional layers are all ELU.
from src.models.network_module import GatedConv2d, TransposeGatedConv2d
from src.models.compute_attention import ContextualAttention, ApplyAttention
class Coarse(nn.Cell):
"""Build the first stage of generator: coarse network"""
def __init__(self):
super(Coarse, self).__init__()
self.coarse1 = nn.SequentialCell(
GatedConv2d(4, 32, 5, 2, 1, sc=True),
GatedConv2d(32, 32, 3, 1, 1, sc=True),
GatedConv2d(32, 64, 3, 2, 1, sc=True)
)
self.coarse2 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True)
)
self.coarse3 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True)
)
self.coarse4 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 2, sc=True),
GatedConv2d(64, 64, 3, 1, 2, sc=True),
GatedConv2d(64, 64, 3, 1, 2, sc=True),
GatedConv2d(64, 64, 3, 1, 2, sc=True),
GatedConv2d(64, 64, 3, 1, 2, sc=True)
)
self.coarse5 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 4, sc=True),
GatedConv2d(64, 64, 3, 1, 4, sc=True),
GatedConv2d(64, 64, 3, 1, 4, sc=True),
GatedConv2d(64, 64, 3, 1, 4, sc=True)
)
self.coarse6 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 8, sc=True),
GatedConv2d(64, 64, 3, 1, 8, sc=True),
)
self.coarse7 = nn.SequentialCell(
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True),
GatedConv2d(64, 64, 3, 1, 1, sc=True),
)
self.coarse8 = nn.SequentialCell(
TransposeGatedConv2d(64, 32, 3, 1, 1, sc=True),
GatedConv2d(32, 32, 3, 1, 1, sc=True),
TransposeGatedConv2d(32, 3, 3, 1, 1, sc=True),
)
def construct(self, first_in):
first_out = self.coarse1(first_in)
first_out = self.coarse2(first_out)
first_out = self.coarse3(first_out)
first_out = self.coarse4(first_out)
first_out = self.coarse5(first_out)
first_out = self.coarse6(first_out)
first_out = self.coarse7(first_out)
first_out = self.coarse8(first_out)
first_out = ops.clip_by_value(first_out, -1, 1)
return first_out
class GatedGenerator(nn.Cell):
"""
Build the second stage of generator: refine network and complete generator.
Args:
opt(class): option class.
Return:
first_out: The output of coarse network.
second_out: The output of refine network.
match: Attention score.
"""
def __init__(self, opt):
super(GatedGenerator, self).__init__()
self.coarse = Coarse()
self.refinement1 = nn.SequentialCell(
GatedConv2d(4, 32, 3, 2, 1),
GatedConv2d(32, 32, 3, 1, 1)
)
self.refinement2 = nn.SequentialCell(
GatedConv2d(32, 64, 3, 2, 1),
GatedConv2d(64, 64, 3, 1, 1)
)
self.refinement3 = nn.SequentialCell(
GatedConv2d(64, 128, 3, 2, 1),
GatedConv2d(128, 128, 3, 1, 1)
)
self.refinement4 = GatedConv2d(128, 128, 3, 1, 1)
self.refinement5 = nn.SequentialCell(
GatedConv2d(128, 128, 3, 1, 2),
GatedConv2d(128, 128, 3, 1, 4)
)
self.refinement6 = nn.SequentialCell(
GatedConv2d(128, 128, 3, 1, 8),
GatedConv2d(128, 128, 3, 1, 16)
)
self.refinement7 = nn.SequentialCell(
TransposeGatedConv2d(128, 64, 3, 1, 1),
GatedConv2d(64, 64, 3, 1, 1)
)
self.refinement8 = nn.SequentialCell(
TransposeGatedConv2d(128, 32, 3, 1, 1),
GatedConv2d(32, 32, 3, 1, 1)
)
self.refinement9 = TransposeGatedConv2d(64, 3, 3, 1, 1)
self.conv_att1 = GatedConv2d(128, 128, 3, 1, 1)
self.conv_att2 = GatedConv2d(256, 128, 3, 1, 1)
self.batch = opt.train_batchsize
self.apply_attention1 = ApplyAttention([self.batch, 64, 128, 128], [self.batch, 1024, 32, 32])
self.apply_attention2 = ApplyAttention([self.batch, 32, 256, 256], [self.batch, 1024, 32, 32])
self.ones = ops.Ones()
self.concat = ops.Concat(1)
self.bilinear_256 = ops.ResizeBilinear((256, 256))
self.bilinear_512 = ops.ResizeBilinear((512, 512))
self.reshape = ops.Reshape()
self.contextual_attention = ContextualAttention(fuse=True, dtype=mindspore.float32)
self.cat = ops.Concat(1)
self.method = opt.attention_type
def construct(self, img, mask):
x_in = img.astype(mindspore.float32)
shape = x_in.shape
mask_batch = self.ones((shape[0], 1, shape[2], shape[3]), mindspore.float32)
mask_batch = mask_batch * mask
first_in = self.concat((x_in, mask_batch))
first_in = self.bilinear_256(first_in)
first_out = self.coarse(first_in)
first_out = self.bilinear_512(first_out)
first_out = self.reshape(first_out, (shape[0], shape[1], shape[2], shape[3]))
x_coarse = first_out * mask_batch + x_in * (1. - mask_batch)
second_in = self.concat([x_coarse, mask_batch])
pl1 = self.refinement1(second_in)
pl2 = self.refinement2(pl1)
second_out = self.refinement3(pl2)
second_out = self.refinement4(second_out)
second_out = self.refinement5(second_out)
pl3 = self.refinement6(second_out)
x_hallu = pl3
x, match = self.contextual_attention(pl3, pl3, mask, self.method)
x = self.conv_att1(x)
x = self.cat((x_hallu, x))
second_out = self.conv_att2(x)
second_out = self.refinement7(second_out)
second_out_att = self.apply_attention1(pl2, match)
second_out = self.concat([second_out_att, second_out])
second_out = self.refinement8(second_out)
second_out_att = self.apply_attention2(pl1, match)
second_out = self.concat([second_out_att, second_out])
second_out = self.refinement9(second_out)
second_out = ops.clip_by_value(second_out, -1, 1)
return first_out, second_out, match
Discriminator
Discriminator D uses a series of Conv2d and LeakyReLU layers for processing, and finally outputs the final discrimination result through the nn.Dense function. The code implementation of the discriminator is as follows:
from src.models.network_module import Conv2dLayer
class Discriminator(nn.Cell):
"""Build the complete discriminator"""
def __init__(self):
super(Discriminator, self).__init__()
self.block1 = Conv2dLayer(3, 64, 5, 2, 1)
self.block2 = Conv2dLayer(64, 128, 5, 2, 1)
self.block3 = Conv2dLayer(128, 256, 5, 2, 1)
self.block4 = Conv2dLayer(256, 256, 5, 2, 1)
self.block5 = Conv2dLayer(256, 256, 5, 2, 1)
self.block6 = Conv2dLayer(256, 256, 5, 2, 1)
self.block7 = nn.Dense(16384, 1)
def construct(self, img):
x = img
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = x.reshape([x.shape[0], -1])
x = self.block7(x)
return x
Connecting Loss Functions to the Network
MindSpore encapsulates operations such as loss functions and optimizers into a cell, which can pose challenges when implementing GANs. This is because the structure of GANs differs from that of general classification networks, and their losses are multi-output, consisting of both discriminator and generator losses. If the cell package is directly used, the framework cannot establish the connection between the losses and the network, making training impossible. Therefore, we need to customize the WithLossCell class to connect the losses to the network.
For generator losses, we create adversarial loss Ladv and reconstruction loss Lrec, respectively.
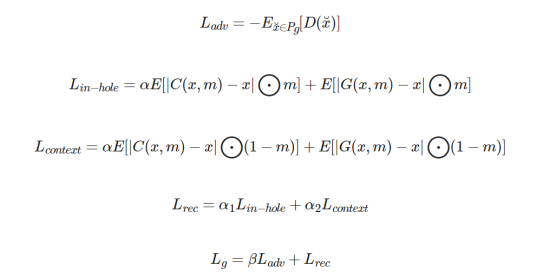
Generally, α, α1, and α2 are set to 1.2, and β is set to 0.001.
from src.models.cra_utils.utils import gan_wgan_loss
class GenWithLossCell(nn.Cell):
"""
Build the generator loss.
Args:
net_g(cell): generator network.
net_d(cell): discriminator network.
args(class): option class.
auto_prefix(bool): whether to automatically generate namespace for cell and its subcells.
If set to True, the network parameter name will be prefixed, otherwise it will not.
Return:
loss_g: the loss of generator.
"""
def __init__(self, net_g, net_d, args, auto_prefix=True):
super(GenWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.net_g = net_g
self.net_d = net_d
self.gan_wgan_loss = gan_wgan_loss
self.coarse_alpha = args.coarse_alpha
self.gan_with_mask = args.gan_with_mask
self.gan_loss_alpha = args.gan_loss_alpha
self.in_hole_alpha = args.in_hole_alpha
self.context_alpha = args.context_alpha
self.train_batchsize = args.train_batchsize
self.mean = ops.ReduceMean(False)
self.abs = ops.Abs()
self.concat_0 = ops.Concat(0)
self.concat_1 = ops.Concat(1)
self.split = ops.Split(0, 2)
self.tile = ops.Tile()
def construct(self, real, x, mask):
x1, x2, _ = self.net_g(x, mask)
fake = x2
losses = {}
fake_patched = fake * mask + real * (1 - mask)
fake_patched = fake_patched.astype(mindspore.float32)
losses['in_hole_loss'] = self.coarse_alpha * self.mean(self.abs(real - x1) * mask)
losses['in_hole_loss'] = losses['in_hole_loss'] + self.mean(self.abs(real - x2) * mask)
losses['context_loss'] = self.coarse_alpha * self.mean(self.abs(real - x1) * (1 - mask))
losses['context_loss'] = losses['context_loss'] + self.mean(self.abs(real - x2) * (1 - mask))
losses['context_loss'] = losses['context_loss'] / self.mean(1 - mask)
real_fake = self.concat_0((real, fake_patched))
if self.gan_with_mask:
real_fake = self.concat_1((real_fake, self.tile(mask, (self.train_batchsize * 2, 1, 1, 1))))
d_real_fake = self.net_d(real_fake)
d_real, d_fake = self.split(d_real_fake)
g_loss, _ = self.gan_wgan_loss(d_real, d_fake)
losses['adv_gloss'] = g_loss
losses['g_loss'] = self.gan_loss_alpha * losses['adv_gloss']
losses['g_loss'] = losses['g_loss'] + self.in_hole_alpha * losses['in_hole_loss']
losses['g_loss'] = losses['g_loss'] + self.context_alpha * losses['context_loss']
loss_g = losses['g_loss']
return loss_g
For discriminator losses, we add the WGAN-GP loss to enhance the global consistency of the refined network in the second phase.
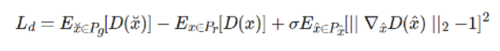
D(.) is the discriminator output and G(.) is the generator output. x, ˜x, ˆx, are the real image, generated image, and interpolations between them, respectively. P__g, P__r, P__ˆx are the corresponding distributions.
from src.models.cra_utils.utils import random_interpolates, GradientsPenalty
class DisWithLossCell(nn.Cell):
"""
Build the discriminator loss.
Args:
net_g(cell): generator network.
net_d(cell): discriminator network.
args(class): option class.
auto_prefix(bool): whether to automatically generate namespace for cell and its subcells.
If set to True, the network parameter name will be prefixed, otherwise it will not.
Return:
loss_d: the loss of discriminator.
"""
def __init__(self, net_g, net_d, args, auto_prefix=True):
super(DisWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.net_g = net_g
self.net_d = net_d
self.gan_wgan_loss = gan_wgan_loss
self.random_interpolates = random_interpolates
self.gradients_penalty = GradientsPenalty(self.net_d)
self.gan_with_mask = args.gan_with_mask
self.wgan_gp_lambda = args.wgan_gp_lambda
self.train_batchsize = args.train_batchsize
self.concat_0 = ops.Concat(0)
self.concat_1 = ops.Concat(1)
self.split = ops.Split(0, 2)
def construct(self, real, x, mask):
_, x2, _ = self.net_g(x, mask)
fake = x2
losses = {}
fake_patched = fake * mask + real * (1 - mask)
fake_patched = fake_patched.astype(mindspore.float32)
real_fake = self.concat_0((real, fake_patched))
if self.gan_with_mask:
real_fake = self.concat_1((real_fake, ops.Tile()(mask, (self.train_batchsize * 2, 1, 1, 1))))
d_real_fake = self.net_d(real_fake)
d_real, d_fake = self.split(d_real_fake)
_, d_loss = self.gan_wgan_loss(d_real, d_fake)
losses['adv_dloss'] = d_loss
interps = self.random_interpolates(real, fake_patched)
gp_loss = self.gradients_penalty(interps)
losses['gp_loss'] = self.wgan_gp_lambda * gp_loss
losses['d_loss'] = losses['adv_dloss'] + losses['gp_loss']
loss_d = losses['d_loss']
return loss_d
Set up the connection between loss functions and the network, and define the training network encapsulation class.
import mindspore.ops.functional as F
from mindspore.parallel._utils import (_get_device_num, _get_gradients_mean, _get_parallel_mode)
from mindspore.context import ParallelMode
from mindspore.nn.wrap.grad_reducer import DistributedGradReducer
class TrainOneStepD(nn.Cell):
"""Encapsulation class of discriminator network training."""
def __init__(self, d, optimizer, sens=1.0):
super(TrainOneStepD, self).__init__(auto_prefix=True)
self.optimizer = optimizer
self.d = d
self.d.net_d.set_grad()
self.d.net_d.set_train()
self.d.net_g.set_grad(False)
self.d.net_g.set_train(False)
self.grad = ops.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.weights = optimizer.parameters
self.reducer_flag = False
self.fill = ops.Fill()
self.dtype = ops.DType()
self.shape = ops.Shape()
self.grad_reducer = F.identity
self.parallel_mode = _get_parallel_mode()
if self.parallel_mode in (ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL):
self.reducer_flag = True
if self.reducer_flag:
mean = _get_gradients_mean()
degree = _get_device_num()
self.grad_reducer = DistributedGradReducer(self.weights, mean, degree)
def construct(self, real, x, mask):
weights = self.weights
loss_d = self.d(real, x, mask)
sens_d = self.fill(self.dtype(loss_d), self.shape(loss_d), self.sens)
grads_d = self.grad(self.d, weights)(real, x, mask, sens_d)
if self.reducer_flag:
grads_d = self.grad_reducer(grads_d)
self.optimizer(grads_d)
return loss_d
class TrainOneStepG(nn.Cell):
"""Encapsulation class of generator network training."""
def __init__(self, g, optimizer, sens=1.0):
super(TrainOneStepG, self).__init__(auto_prefix=True)
self.optimizer = optimizer
self.g = g
self.g.net_g.set_grad()
self.g.net_g.set_train()
self.g.net_d.set_grad(False)
self.g.net_d.set_train(False)
self.grad = ops.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.weights = optimizer.parameters
self.reducer_flag = False
self.fill = ops.Fill()
self.dtype = ops.DType()
self.shape = ops.Shape()
self.grad_reducer = F.identity
self.parallel_mode = _get_parallel_mode()
if self.parallel_mode in (ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL):
self.reducer_flag = True
if self.reducer_flag:
mean = _get_gradients_mean()
degree = _get_device_num()
self.grad_reducer = DistributedGradReducer(self.weights, mean, degree)
def construct(self, real, x, mask):
weights = self.weights
loss_g = self.g(real, x, mask)
sens_g = self.fill(self.dtype(loss_g), self.shape(loss_g), self.sens)
grads_g = self.grad(self.g, weights)(real, x, mask, sens_g)
if self.reducer_flag:
grads_g = self.grad_reducer(grads_g)
self.optimizer(grads_g)
return loss_g
Optimizer Building
net_g = GatedGenerator(config)
net_d = Discriminator()
lr = nn.exponential_decay_lr(config.learning_rate, config.lr_decrease_factor, total_batch * config.epochs, total_batch,
config.lr_decrease_epoch, True)
optimizer_g = nn.Adam(filter(lambda p: p.requires_grad, net_g.trainable_params()), lr, 0.5, 0.9)
optimizer_d = nn.Adam(net_d.trainable_params(), lr, 0.5, 0.9)
Here, two independent optimizers are set for the discriminator and generator respectively. The parameters beta1 and beta2 are set to 0.5 and 0.9 respectively. The learning rate is automatically updated using the exponential attenuation function.
Model Training
Training is divided into two parts: discriminator training and generator training. Discriminator training is to better identify authenticity, and try to separate an image generated by the generator from a real image. Generator training is to generate a fake image that is approximately real as much as possible.
Training process:
import cv2
import time
from mindspore import context, save_checkpoint, nn
from src.config.config import cra_config
from src.models.inpainting_network import GatedGenerator, Discriminator
from src.models.loss import GenWithLossCell, DisWithLossCell
from src.models.train_one_step import TrainOneStepD, TrainOneStepG
def trainer(args):
"""Train model."""
# Preprocess the data for training
context.set_context(mode=context.GRAPH_MODE, device_target='GPU')
dataset_generator = InpaintDataset(args)
dataset_size = len(dataset_generator)
total_batch = dataset_size // args.train_batchsize
dataset = ds.GeneratorDataset(dataset_generator, ['image'])
dataset = dataset.batch(args.train_batchsize, drop_remainder=True)
dataset = dataset.create_dict_iterator()
# Network
net_g = GatedGenerator(args)
net_d = Discriminator()
netg_with_loss = GenWithLossCell(net_g, net_d, args)
netd_with_loss = DisWithLossCell(net_g, net_d, args)
lr = nn.exponential_decay_lr(args.learning_rate, args.lr_decrease_factor, total_batch * 10, total_batch,
args.lr_decrease_epoch, True)
optimizer_g = nn.Adam(filter(lambda p: p.requires_grad, net_g.trainable_params()), lr, 0.5, 0.9)
optimizer_d = nn.Adam(net_d.trainable_params(), lr, 0.5, 0.9)
train_discriminator = TrainOneStepD(netd_with_loss, optimizer_d)
train_generator = TrainOneStepG(netg_with_loss, optimizer_g)
# Train
train_discriminator.set_train()
train_generator.set_train()
print("Starting Training Loop...")
for epoch in range(10):
for batch_idx, image in enumerate(dataset):
s = time.time()
real = image['image']
real = real.astype(mindspore.float32)
mask, _ = random_mask(args)
x = real * (1 - mask)
for _ in range(args.dis_iter):
netd_loss = train_discriminator(real, x, mask)
netg_loss = train_generator(real, x, mask)
gap = time.time() - s
# Print losses
print('epoch{}/{}, batch{}/{}, d_loss is {:.4f}, g_loss is {:.4f}, time is {:.4f}'.format(
epoch + 1, args.epochs, batch_idx + 1, total_batch, netd_loss.asnumpy(), netg_loss.asnumpy(), gap))
save_checkpoint_path = './ckpt_out'
if not os.path.isdir(save_checkpoint_path):
os.makedirs(save_checkpoint_path)
# Save checkpoint
gen_name = 'generator_epoch%d_batch%d.ckpt' % (epoch + 1, batch_idx + 1)
dis_name = 'discriminator_epoch%d_batch%d.ckpt' % (epoch + 1, batch_idx + 1)
gen_name = os.path.join(save_checkpoint_path, gen_name)
dis_name = os.path.join(save_checkpoint_path, dis_name)
if (batch_idx + 1) == total_batch:
save_checkpoint(train_generator, gen_name)
save_checkpoint(train_discriminator, dis_name)
trainer(cra_config)
Model Inference
After the GAN training is complete, we can use it to predict the inpainting result of a low-resolution image. However, to generate a complete high-resolution inpainted image, some postprocessing operations need to be performed, which are specifically: obtain the image's contextual residual information; generate aggregated residuals of missing content by using the high-frequency residual and attention mechanism; upsample the image generated by the GAN; add the aggregated residuals to the large and blurry image to obtain a clear inpainted image; and resize the inpainted image to a size the same as that of the original image.
import glob
import cv2
import numpy as np
def sort(str_lst):
"""Return the sorted list in ascending order."""
return [s for s in sorted(str_lst)]
def read_imgs_masks(args):
"""Sort the image and mask directories in order and return it."""
paths_img = glob.glob(args.image_dir + '/*.*[g|G]')
paths_img = sort(paths_img)
paths_mask = glob.glob(args.mask_dir + '/*.*[g|G]')
paths_mask = sort(paths_mask)
return paths_img, paths_mask
def get_input(path_img, path_mask):
"""Read and process the image and mask through the given path."""
image = cv2.imread(path_img)
mask = cv2.imread(path_mask)
image = np.expand_dims(image, 0)
mask = np.expand_dims(mask, 0)
return image[0], mask[0]
from mindspore import nn, ops
from src.models.inpainting_network import GatedGenerator
from src.models.compute_attention import ApplyAttention2
def post_processing(large_img, small_img, low_base, small_mask, corres, args):
"""Subtracting the large blurry image from the raw input to compute contextual residuals,
and calculate aggregated residuals through attention transfer module.
Adding the aggregated residuals to the up-sampled generator inpainted result."""
high_raw = large_img
low_raw = small_img
mask = 1 - small_mask
low_raw = nn.ResizeBilinear()(low_raw, scale_factor=args.times)
to_shape = list(ops.Shape()(mask))[2:]
to_shape[0], to_shape[1] = int(to_shape[0] * args.times), int(to_shape[1] * args.times)
resize = ops.ResizeNearestNeighbor((to_shape[0], to_shape[1]))
mask = resize(mask)
residual1 = (high_raw - low_raw) * mask
residual = ApplyAttention2([1, 3, 4096, 4096], [1, 1024, 32, 32])(residual1, corres)
low_base = nn.ResizeBilinear()(low_base, scale_factor=args.times)
x = low_base + residual
x = x.clip(-1, 1)
x = (x + 1.) * 127.5
return x, low_raw, low_base, residual
from scipy import signal
import mindspore
from mindspore import Tensor
def gaussian_kernel(size, std):
"""Return a gaussian kernel."""
k = signal.gaussian(size, std)
kk = np.matmul(k[:, np.newaxis], [k])
return kk / np.sum(kk)
def resize_back(raw_img, large_output, small_mask):
"""Process the test output result in the format of [1, 3,4096,4096] to the same size as the original input image."""
raw_shp = raw_img.shape
raw_size_output = nn.ResizeBilinear()(large_output, size=(raw_shp[2], raw_shp[3]))
raw_size_output = raw_size_output.astype(mindspore.float32)
gauss_kernel = gaussian_kernel(7, 1.)
gauss_kernel = Tensor(gauss_kernel)
gauss_kernel = gauss_kernel.astype(mindspore.float32)
gauss_kernel = ops.ExpandDims()(gauss_kernel, 2)
gauss_kernel = ops.ExpandDims()(gauss_kernel, 3)
a, b, c, d = ops.Shape()(gauss_kernel)
gauss_kernel = ops.Transpose()(gauss_kernel, (3, 2, 0, 1))
conv = nn.Conv2d(c, d, (a, b), 1, pad_mode='same', padding=0, weight_init=gauss_kernel, data_format='NCHW')
mask = conv(small_mask[:, 0:1, :, :])
mask = nn.ResizeBilinear()(mask, size=(raw_shp[2], raw_shp[3]))
mask = mask.astype(mindspore.float32)
raw_size_output = raw_size_output * mask + raw_img * (1 - mask)
raw_size_output = ops.Transpose()(raw_size_output, (0, 2, 3, 1))
raw_size_output = raw_size_output.astype(mindspore.uint8)
return raw_size_output
def build_inference_graph(real, mask, model_gen):
"""Input real and mask to generator and output the results."""
mask = mask[0:1, 0:1, :, :]
x = real * (1. - mask)
_, x2, corres = model_gen(x, mask)
fake = x2
fake_patched = fake * mask + x * (1 - mask)
return x2, fake_patched, corres
def build_inference_net(raw_img_ph, raw_mask_ph, model_gen, args):
"""
Complete CRA network testing model, including image preprocessing, generator generation and output,
and image post-processing operations.
Args:
raw_img_ph(Tensor): image read from folder.
It is processed into the format of [1,3,512,512], the data type is float32, and normalized.
raw_mask_ph(Tensor): mask read from folder.
It is processed into the format of [1,3,512,512], the data type is float32, and normalized.
model_gen(cell): generation network.
args(class): option class.
Return:
raw_size_output: Large test output results.
raw_img_ph: Image read from folder.
raw_mask_ph: Mask read from folder.
"""
# Process input image
raw_img = ops.ExpandDims()(raw_img_ph, 0)
raw_img = raw_img.astype(mindspore.float32)
raw_img = ops.Transpose()(raw_img, (0, 3, 1, 2))
resize = ops.ResizeNearestNeighbor((args.times * args.input_size, args.times * args.input_size))
large_img = resize(raw_img)
large_img = ops.Reshape()(large_img, (1, 3, args.times * args.input_size, args.times * args.input_size))
large_img = large_img / 127.5 - 1
net = nn.Unfold([1, args.times, args.times, 1], [1, args.times, args.times, 1], [1, 1, 1, 1], 'same')
small_img = net(large_img)
small_img = ops.Transpose()(small_img, (0, 2, 3, 1))
small_img = ops.Reshape()(small_img, (1, args.input_size, args.input_size, args.times, args.times, 3))
small_img = ops.ReduceMean(False)(small_img, axis=(3, 4))
small_img = ops.Transpose()(small_img, (0, 3, 1, 2))
# Process input mask
raw_mask = ops.ExpandDims()(raw_mask_ph, 0)
raw_mask = raw_mask.astype(mindspore.float32)
raw_mask = ops.Transpose()(raw_mask, (0, 3, 1, 2))
resize = ops.ResizeNearestNeighbor((args.input_size, args.input_size))
small_mask = resize(raw_mask)
small_mask = ops.Reshape()(small_mask, (1, 3, args.input_size, args.input_size))
small_mask = 1 - small_mask / 255
# Input image and mask to generator
x2, _, corres = build_inference_graph(real=small_img, mask=small_mask, model_gen=model_gen)
# Post processing
large_output, _, _, _ = post_processing(large_img, small_img, x2, small_mask, corres, args)
# Resize back
raw_size_output = resize_back(raw_img, large_output, small_mask)
return raw_size_output, raw_img_ph, raw_mask_ph
The inference code is as follows:
import os
import time
import argparse
import progressbar
from mindspore import context, load_checkpoint, load_param_into_net
def parse_args():
"""Parse parameters."""
parser = argparse.ArgumentParser()
parser.add_argument('--image_dir', default='./test/images', type=str, help='The directory of images to be tested.')
parser.add_argument('--mask_dir', default='./test/masks', type=str, help='The directory of masks.')
parser.add_argument('--output_dir', default='./output', type=str, help='Where to write testing output.')
parser.add_argument('--checkpoint_dir', default='./ckpt_out/generator_epoch10_batch4.ckpt', type=str,
help='The directory of loading checkpoint.')
parser.add_argument('--attention_type', default='SOFT', type=str, help='compute attention type.')
parser.add_argument('--train_batchsize', default=1, type=int, help='Batch size for testing.')
parser.add_argument('--input_size', default=512, type=int, help='The image size of the input network in the test.')
parser.add_argument('--times', default=8, type=int, help='The scaling size of input image.')
return parser.parse_args(args=[])
# setting test data
cra_config = parse_args()
img_paths, mask_paths = read_imgs_masks(cra_config)
if not os.path.exists(cra_config.output_dir):
os.makedirs(cra_config.output_dir)
total_time = 0
bar = progressbar.ProgressBar(maxval=len(img_paths), widgets=[progressbar.Bar('=', '[', ']'), ' ',
progressbar.Percentage()])
bar.start()
# load net and checkpoint file
gen = GatedGenerator(cra_config)
param_dict = load_checkpoint(cra_config.checkpoint_dir)
load_param_into_net(gen, param_dict)
#test
for (i, img_path) in enumerate(img_paths):
rint = i % len(mask_paths)
bar.update(i + 1)
img_test, mask_test = get_input(img_path, mask_paths[rint])
s = time.time()
input_img_ph = Tensor(img_test)
input_mask_ph = Tensor(255 - mask_test)
outputs, input_img_ph, input_mask_ph = build_inference_net(input_img_ph, input_mask_ph, gen, cra_config)
res = outputs[0]
res = res.asnumpy()
total_time += time.time() - s
img_hole = img_test * (1 - mask_test / 255) + mask_test
res = np.concatenate([img_test, img_hole, res], axis=1)
cv2.imwrite(cra_config.output_dir + '/' + str(i) + '.jpg', res)
print('test finish')
bar.finish()
print('average time per image', total_time / len(img_paths))
The inference result is displayed as follows. The first image is the original complete image, the second image is the image to be inpainted that contains holes, and the third image is the inpainting result.

References
[1] Z. Yi, Q. Tang, S. Azizi, D. Jang and Z. Xu. Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting[J]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7505-7514.