Accelerated Foundation Model Development Using MindSpore Technologies
Accelerated Foundation Model Development Using MindSpore Technologies
AI has been developing by leaps and bounds from the end of 2022 to the beginning of 2023. Different from previous technological breakthroughs, the foundation model attracts attention from all walks of life, including the technology and investment fields, the industry, and consumers. Its application has become a phenomenon and the number of active users exceeded 100 million with the shortest time ever, triggering an AI competition among global technology giants.
The high intelligence of foundation models depends on large-scale pre-training of models, which requires a powerful AI framework as underlying support. Then how to develop foundation models with hundreds of billions of parameters against the current background? Let's break down the technology solutions to explore the capabilities of the MindSpore AI framework.
Development of Pre-trained Foundation Models
Large-scale Pre-training: PCL-L
In April 2021, based on the multidimensional, automatic hybrid parallelism of the MindSpore AI framework, the joint research team led by Pengcheng Lab trained PCL-L, the industry's first pre-trained language model (Chinese as the core) with 200 billion parameters, on Pengcheng Cloud Brain II, a large-scale AI computing platform. The joint team collected nearly 80 TB raw data from open-source datasets, Common Crawl web pages, and e-books, building a distributed cluster for large-scale corpus preprocessing. By performing data cleaning, filtering, deduplication, and quality evaluation, the team constructed a high-quality Chinese corpus dataset of about 1.1 TB, which includes about 250 billion tokens according to statistics.
Thanks to the ultra-large number of parameters, the pre-trained model PCL-L has the powerful capability of context learning and extensive base of world knowledge.
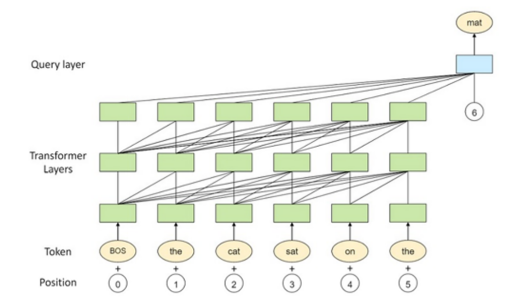
△ Figure 1 PCL-L model architecture
With the automatic parallelism of the MindSpore AI framework, developers can implement automatic model segmentation and distributed parallel computing with only one line of code, saving complex designs. Models with billions to trillions of parameters can be efficiently trained in large clusters.
An Inevitable Process of the Chain of Thought: Code Pre-training
Chain of thought (CoT) is the key to the humanized dialogue capability of a foundation model. After GPT-3, the CoT capability was considered to be stimulated through few-shot learning and further triggered by the zero-shot prompt of "Let's think step by step". However, foundation models then were still limited to a weak capability of CoT on various datasets.
Later, the emergence of pre-trained models of code data, and its integration into natural language pre-trained models, elevated the CoT capability of foundation models to a new level. The following figure shows the evolution roadmap of OpenAI since GPT-3. The branch on the left displays the continuous evolution of code foundation models. On the basis of Code-davinci-002 which combines LM and code training while integrating instruct tuning, the well-known ChatGPT is generated.
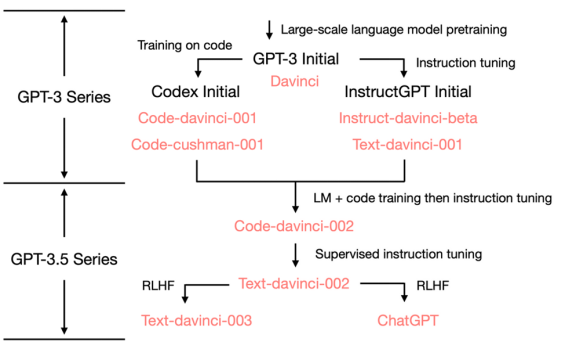
△ Figure 2 ChatGPT evolution roadmap
In September 2022, the Tsinghua University team developed a code pre-trained foundation model, CodeGeeX, based on MindSpore 1.7 using the large-scale AI computing platform (Pengcheng Cloud Brain II) of Pengcheng Lab. The CodeGeeX training corpus consists of two parts: open-source code datasets (The Pile and CodeParrot) and supplemental data (Python, Java, and C++ code directly crawled from GitHub). The entire code corpus contains 23 programming languages and 158.7 billion identifiers (excluding stuffers).
During development and training, Tsinghua University cooperated with the MindSpore team to optimize operator fusion. The optimization includes single-element operator fusion, layer normalization operator fusion, fusion between FastGelu and matrix multiplication, and fusion between batch matrix multiplication and addition, significantly accelerating the training.
Injection of Human Wisdom: RLHF and PPO
ChatGPT astonishes the public in that it truly humanizes dialogues and generates content that is more in line with human perceptions and values. Before ChatGPT, foundation models still differed greatly from human expression habits, though already strong in world knowledge reserve, context learning, and CoT capabilities while refreshing major NLP datasets. InstructGPT, the predecessor of ChatGPT, demonstrated a great change brought by the integration of human feedback into the model training cycle. In this way, reinforcement learning from human feedback (RLHF) is shaped.
RLHF consists of the following steps:
(1) Unsupervised pre-training: Pre-trains a language model, such as GPT-3.
(2) Supervised fine-tuning: Generates a set of prompts and human feedback for each prompt, that is, a training dataset consisting of pairs; fine-tunes the pre-trained model.
(3) Training a reward model of "human feedback": Builds a reward model and scores the output of the pre-trained language model. Given a set of prompts, the device generates answers to instructions, and humans score or rank the quality. This dataset is used to train a reward model to output a quality score for any pair.
(4) Training a reinforcement learning strategy, which is optimized based on the reward model.
The following figure shows the core PPO algorithm of RLHF.
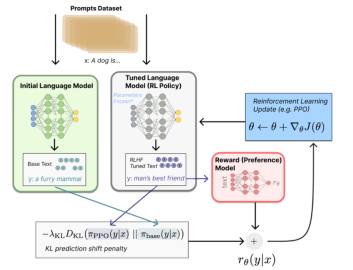
△ Figure 3 PPO algorithm logic
MindSpore released the MindSpore Reinforcement Learning suite to provide simple API abstraction for writing reinforcement learning algorithms and decouple algorithms from deployment and scheduling. The reinforcement learning algorithms are converted into a series of compiled computing graphs, and then run by the MindSpore AI framework efficiently on Ascend AI processors, CPUs, and GPUs. Currently, the MindSpore Reinforcement Learning suite provides the following capabilities:
(1) Various reinforcement learning algorithms: Currently, more than 15 classic reinforcement learning algorithms are supported, covering Model-free/Model-based/Offline-RL/Imitation Learning, single-agent/multi-agent, continuous/discrete action space, and Episodic/Non-Episodic algorithms. Common simulation environments such as MuJoCo, MPE, StarCraft 2, and DeepMind Control are connected.
(2) Focus on high-performance training: With computing graph and ReplayBuffer acceleration, asynchronous environment parallelism, and high-performance domain components, the average throughput of supported algorithms is improved by 120% compared with mainstream frameworks.
(3) Large-scale distributed training: The reinforcement learning algorithms are divided into multiple fragmented dataflow graphs and mapped to heterogeneous devices for efficient execution. The performance is improved by three to five times compared with mainstream frameworks.
MindSpore Enabling Foundation ModelsWith the development of AI technologies, pre-trained foundation models have become the focus of competition among technological powers around the world. Pre-trained foundation models first made eye-catching breakthroughs in the NLP field, and soon expanded to multimodal inference tasks that involve images, videos, graphs, and languages, and a large number of commercial applications, demonstrating great potentials. In the past few years, a series of influential foundation models based on MindSpore have been released, as shown in the following figure.
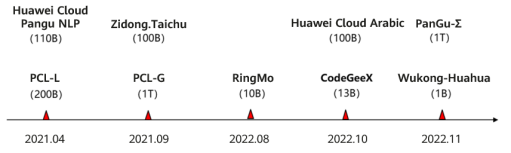
△ Figure 4 MindSpore foundation models
The model structures include Transformer Encoder, Transformer Decoder, MOE, Clip, and Diffusion, which are trained based on the MindSpore AI framework.
Thanks to powerful parallel capabilities, MindSpore can easily complete training tasks of 4096-device clusters and trillions of parameters. In China, MindSpore supports the training of multiple fields' first foundation models, covering knowledge Q&A, knowledge retrieval, knowledge reasoning, reading comprehension, text/visual/speech multimodal, biopharmaceutical, remote sensing, and code generation capabilities.
Base of the Foundation Models: MindSpore Distributed Parallelism
The distributed parallelism serves as the core of the MindSpore AI framework to support a large number of foundation models.
Distributed Training
MindSpore supports mainstream distributed training paradigms and develops a series of automatic hybrid parallel solutions that provide the following key technologies:
(1) Data slicing preprocessing: The training data is sliced in any dimension and then imported to the device for training.
(2) Operator-level parallelism: Each operator in the forward network is independently modeled, and each operator can have different tiling policies.
(3) Optimizer parallelism: Parameter copies of parallel data are divided onto multiple devices to reduce memory usage.
(4) Pipeline parallelism: The computing graphs in the neural network are divided into multiple stages, and then the stages are mapped to different devices, so that different devices calculate different parts of the neural network.
(5) MOE parallelism: Dedicated computing tasks are assigned to each expert. Different experts can use different devices to host tasks.
(6) Multi-copy parallelism: In an iteration step, a training batch is split into multiple micro-batches to concurrently perform model parallel communication and computing.
(7) Heterogeneous parallelism: Operators are allocated to heterogeneous hardware for execution, making full use of hardware resources and improving the overall training throughput.
(8) Forward recomputation: During forward propagation, the input instead of intermediate output is saved, reducing memory usage. During backward propagation, the forward output is recomputed based on the input, greatly reducing the memory peak accumulated in the process.
(9) Global memory overcommitment: Static compilation and optimization are performed on computing graphs to obtain the optimal memory overcommitment policy.
Compared with other deep learning or distributed parallel frameworks, MindSpore features various supported capabilities, high level of automation, and strong usability in terms of key distributed technologies:
(1) More model types (such as Transformer, super-resolution image, and recommendation) have higher universality than other frameworks (for example, Megatron is customized for Transformer).
(2) With the same computing power and network, more parallel policies can achieve a larger computing and communication ratio and better performance (on the same hardware platform (V100 and A100), the performance is 15% higher than that of Megatron).
(3) Various parallel policies require no manual segmentation. The development and optimization efficiency of foundation models is better than that of the industry.
Distributed Inference
Compared with training, inference has higher requirements on computing performance. How to realize efficient and fast foundation model inference on clusters is both important and difficult in the research of frameworks. To address this issue, MindSpore proposed the solution of distributed inference + incremental inference, which uses multi-dimensional hybrid parallelism (data, model, and pipeline parallelism) and performs inference on large clusters. In addition, unlike the autoregressive language models of Transformer Decoder which perform repeated calculations in the traditional inference mode, the incremental inference capability provided by MindSpore improves inference efficiency by cutting these repetitions.
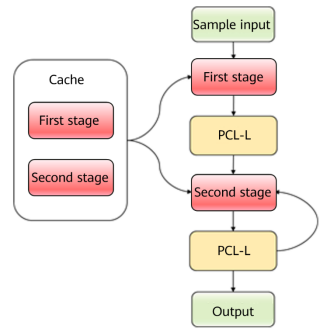
△ Figure 5 Incremental inference process
As shown in the preceding figure, the first stage adopts complete input inference to save the vector corresponding to the current word. In the second stage, the input is only the word obtained through inference in the previous step. Then, the vector obtained through inference in this step is concatenated with the saved pre-order vector to form the complete vector of inference in this step, and the output word is obtained. Repeat the preceding two stages.
Easy-to-Use Foundation Model Training: Foundation Model Suite
During foundation model development, users often find that the SOTA basic model code is not modularized, which affects further innovative development. In addition, it is difficult to find the corresponding SOTA model and downstream tasks during model implementation, which prolongs the development period and affects the progress of papers or projects. Facing these challenges, MindSpore Transformers emerges.
It is a MindSpore-based development kit for deep learning foundation models which serves for the full-process development including model training, fine-tuning, evaluation, inference, and deployment. The suite can be used out-of-the-box and has the following features:
· (1) Provides various pre-trained models, including typical pre-trained foundation models (such as Bert, T5, and VIT) and covering popular AIGC fields such as CV and NLP.
In addition, it contains various downstream fine-tuning tasks, and the precision is basically the same as that of SOTA.
· (2) Provides unified development paradigms.
With feature APIs such as Trainer and Pipeline, the suite implements modular and configuration-based development, greatly improving the development efficiency of typical models (especially Transformer-based networks).
In terms of model deployment, the suite supports the Ascend AI basic software and hardware platform and provides one-click cloud deployment APIs.
· (3) Provides unified external APIs.
The current version of the suite is consistent with the popular Huggingface API in the industry. Users can switch between them by one click, greatly reducing the cost of code migration.
· (4) Inherits the advantages of the MindSpore AI framework, including multi-dimensional parallelism (model, pipeline, optimizer, and multi-copy parallelism) and graph computing convergence. It can effectively improve the memory utilization and accelerate model training, enabling users to efficiently train models with millions, billions or even trillions of parameters.
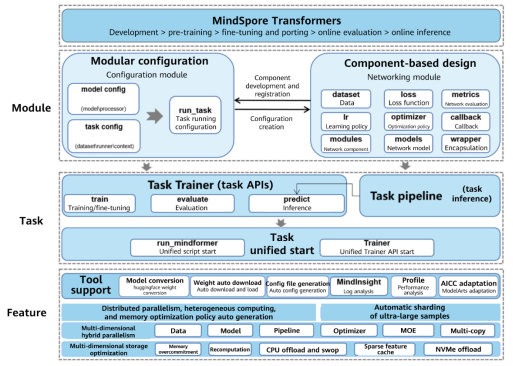
△ Figure 6 MindSpore Transformers architecture
MindSpore has developed various core technologies required for foundation model development and provides a complete set of efficient and easy-to-use enablement suites, forming the end-to-end enabling foundation model development capability. The MindSpore AI framework has been innovating and prospering foundation models in the AI industry.
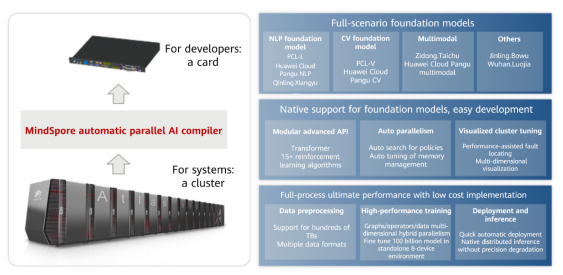
△ Figure 7 Advantages of MindSpore's native support for foundation models
Welcome to try the MindSpore AI framework: https://mindspore.cn/en/ https://gitee.com/mindspore/mindformers
References: [1]Zeng W, Ren X, Su T, et al. Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation[J]. arXiv preprint arXiv:2104.12369 [2]https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756 [3]https://huggingface.co/blog/rlhf [4] https://aijishu.com/a/1060000000222564 [5]https://gitee.com/mindspore/mindformers/wikis/%E7%89%B9%E6%80%A7%E8%AE%BE%E8%AE%A1%E6%96%87%E6%A1%A3