Idea Sharing: Geometric Deep Learning Series - Neural Network from a Unified Perspective
Idea Sharing: Geometric Deep Learning Series - Neural Network from a Unified Perspective
Background
In the previous article of the Idea Sharing series, I briefly introduced the concept of symmetry and groups and how symmetry acts as the first principle in geometry and physics. In this article, you will see that geometric deep learning can be considered as the Erlangen program in the field of deep learning, unifying and classifying various neural network architectures with symmetry as the first principle.
1. Symmetry and Neural Networks
With the fast increase in computing power, deep learning is developing rapidly and demonstrating its unique advantages in many fields such as computer vision and natural language processing. Today, neural networks have evolved from the original multilayer perceptrons (MLPs) to different neural network architectures such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), graph neural networks (GNNs), and transformers. The situation is just like geometry in the late nineteenth century. In recent years, researchers have developed a unified neural network theoretical framework, geometric deep learning, with symmetry as the first principle. Researchers have proposed the concept of "5G", that is, five important objects in geometric deep learning: grids, groups, graphs, geodesics, and gauges.
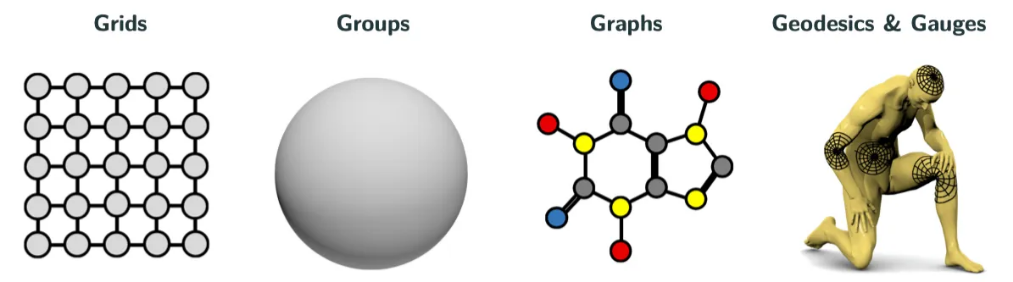
Figure 1 "5G"
2. Space and Feature Fields
To have a better understanding of neural networks, we need to clarify two concepts: space and feature fields. Simply put, space is the extension of information on a spatial scale, and feature field defines a feature vector at each point in the space. The essence of a neural network is a mapping between feature fields.
Let's review the preceding neural network architectures. The MLP has no spatial scale, in other words, the space is a point, and the feature field is the features in the network layer. The MLP maps the features in one layer to those in the next layer. The spatial scale of a 2D CNN is a 2D discrete plane, and the feature field is the channel information of each point on the plane, including the initial RGB channel and multiple channels in the hidden layer. RNN, on the other hand, extends on a temporal scale. GNN extends on a general graph structure. Transformer can be considered as a special complete graph GNN.
The representation of a group refers to the homomorphism from the group to the linear space. The transformation of points in the space is described by a symmetric transformation group, and the transformation between the feature fields is described by the representation of the symmetric transformation group. In other words, a neural network mapping is a mapping between representations.
For example, in the following figure, a feature of a point in the image is three values (R, G, and B), that is, a direct sum of three scalars. The scalar here is the trivial representation of the transformation group, and its value remains unchanged under the action of the transformation group. Trivial representation means that for any transformation group, the representation mapping maps it to an identity matrix, which means that the symmetry information is lost in the mapping process. If the neural network is required to maintain a certain degree of symmetry, we need to describe the transformation of the feature field with a nontrivial representation, indicating that there is a submatrix whose dimension is greater than 1 in the direct sum decomposition of the matrix. Therefore, the neural network is a mapping in which each piece of the submatrix maintains symmetry, as shown in Figure 2.
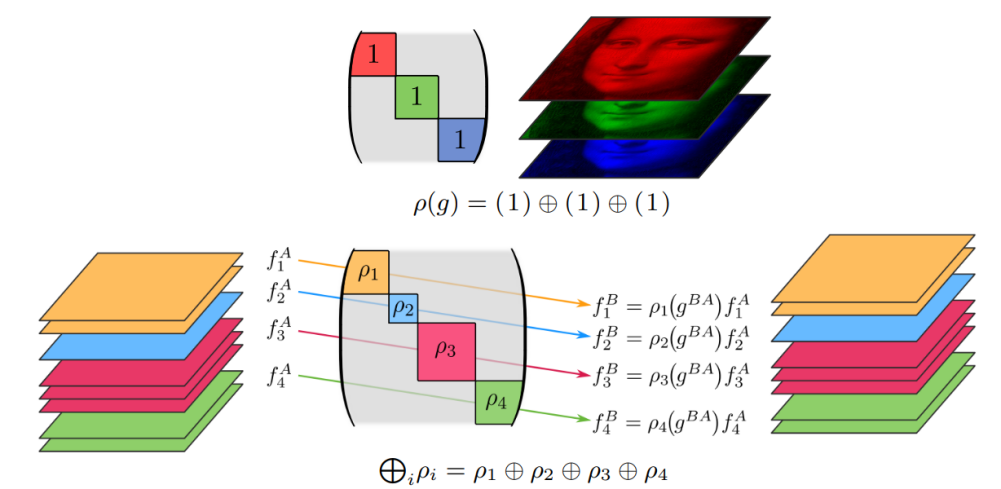
Figure 2 Representation of a transformation group between feature fields
3. Invariance and Equivariance
As mentioned above, if the transformation of the feature field is only some trivial representation, the neural network acts as a mapping between the feature fields and the transformation of the input feature fields does not affect its output feature fields. In this case, the neural network is invariant to the transformation group.
For nontrivial representation, the transformation of the input feature fields does affect the output feature fields. The transformation method depends on the representation of the transformation group. In this case, the neural network is equivariant to the transformation group. It can be seen that the invariance of the mapping is a special case of equivariance.
Intuitively understood, the equivariance of a neural network maintains symmetry. For example, a CNN has spatial translation equivariance. In an image recognition task, when an object in an image is translated, the feature image of the object is also translated accordingly. Therefore, the network can correctly identify the object. Similarly, an RNN has temporal translation equivariance, only that the translation is directional. A GNN has vertex number gauge equivariance. If the adjacent matrix is used to represent the graph information, the permutation of the vertex number of the graph is also reflected on the adjacent matrix. As for a basic MLP, it has data set permutation gauge equivariance.
It can be seen that any neural network is a symmetric equivariant mapping. Another important conclusion about equivariance is that: equivariance = coordinate independence + weight sharing. For example, the equivariance of a CNN may be considered as spatial position coordinate independence, and the weight is shared in spatial translation with reference to the convolution kernel. The observation of the feature field deepens people's understanding of equivariance and is important for designing neural networks in more general spatial structures, such as curved spaces. We will briefly introduce how to perform convolution on Riemannian manifolds later.
4. Perspective of Category Theory
We can also further abstract and look at the essence of neural networks from the perspective of category theory.
Category is an abstraction tool of mathematics used to describe different mathematical structures and their relationships. A category consists of the following three parts:
1. A class of objects, which can be any mathematical entities with certain structures, such as sets, groups, or topological spaces.
2. A class of morphisms, which can be any mappings that maintain the structure, such as functions, group homomorphisms, and continuous mappings. Each morphism has a source object and a target object, indicating the mapping direction.
3. A composition of morphisms, which satisfies the law of binding and the existence of identity element.
An example of a category is a set category. Its objects are all the sets, its morphisms are all the functions, and its composition is the composition of functions.
Functors are mappings between categories. It can transform the objects and morphisms of one category into another category, and maintain the morphisms and the composition of morphism. For example, the representation of a group is a functor that maps the group category to the linear space category.
Natural transformation is a mapping that converts one functor into another while keeping the internal structure of the category unchanged.
As mentioned above, all neural networks are symmetric equivariant mappings. From the perspective of category theory, this conclusion is obvious because the essence of neural networks is natural transformation of group representation functors, and different categories correspond to different network architectures. For example, the set category corresponds to the MLP, and the graph category corresponds to the GNN.
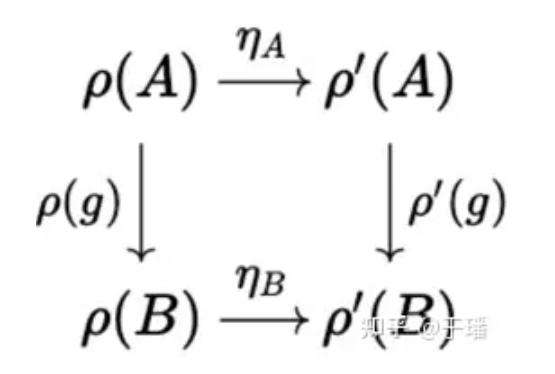
Figure 3 Natural transformation η of group representation functor ρ(g)
5. Neural Network Design Blueprint
So far, we have a unified overall understanding of the neural network, so that a general neural network design blueprint can be obtained.
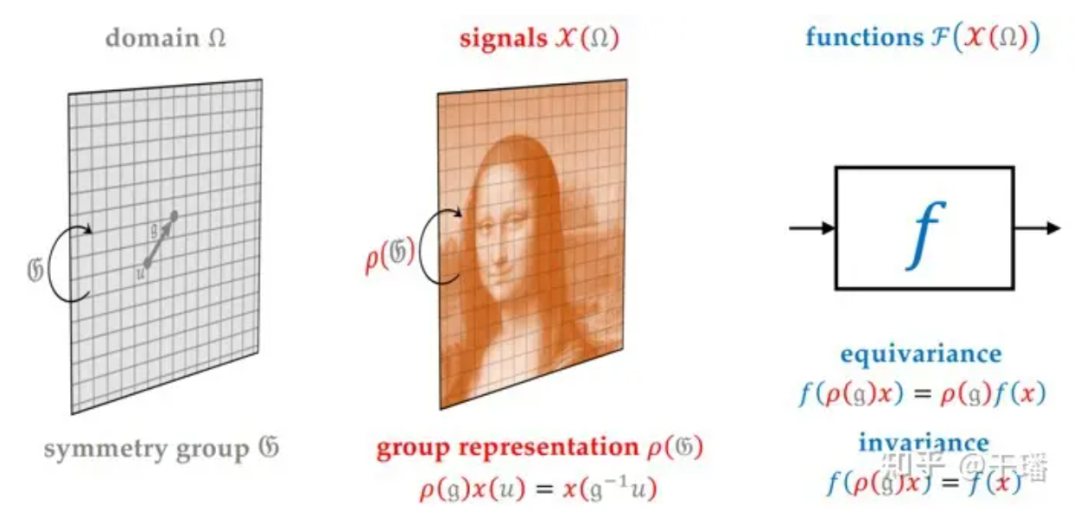
Figure 4 Neural Network Design Blueprint
A neural network needs to specify the space/domain in which information extends, space transformation group (G), feature field/signals in the space, and feature field transformation (ρ(G)). The network consists of the following modules: linear equivariant layer, nonlinear (equivariant) layer, local pooling layer (coarse-grained), and linear invariant layer (global pooling).
Take CNN as an example. The space is a two-dimensional discrete plane, the transformation group is a two-dimensional translation group, the feature field is the channel information of the image, the transform representation is a trivial representation, and the linear equivariant layer is a convolutional layer. The nonlinear layer may be any nonlinear function because the feature field consists of scalars and does not constrain the nonlinear layer. The local pooling layer is a pooling layer in the CNN, and the linear invariant layer is an MLP at the end of the network.
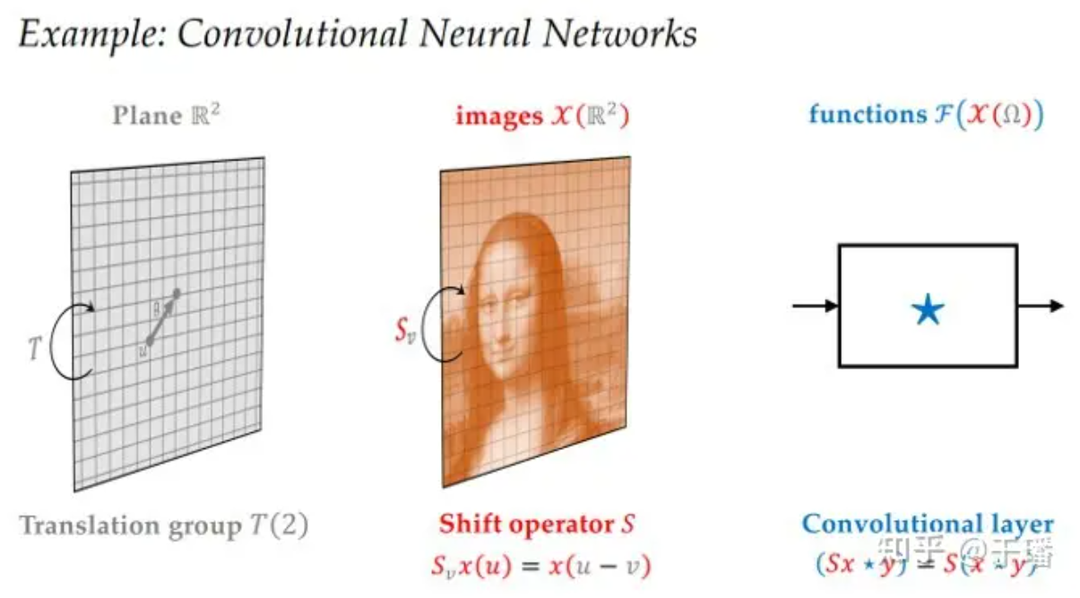
Figure 5 CNN architecture
So far, we have reviewed various neural network architectures from a macroscopic and unified perspective and introduced a symmetric neural network design blueprint. In the next article, we'll take a look at three typical symmetric neural network types: GNNs, group equivariant neural networks, and manifold neural networks.
References
[1]Bronstein, Michael M., et al. "Geometric deep learning: Grids, groups, graphs, geodesics, and gauges." arXiv preprint arXiv:2104.13478 (2021).
[2]Weiler, Maurice, et al. "Coordinate Independent Convolutional Networks--Isometry and Gauge Equivariant Convolutions on Riemannian Manifolds." arXiv preprint arXiv:2106.06020 (2021).