MSAdapter, an Adaptation Tool for Efficiently Porting PyTorch Code to the MindSpore Ecosystem
MSAdapter, an Adaptation Tool for Efficiently Porting PyTorch Code to the MindSpore Ecosystem
As an important infrastructure for AI innovation, the AI framework is accelerating the progress of AI technologies and fueling the intelligent transformation and upgrade of many industries. However, due to a late start, the ecosystem of China's AI frameworks has not been established, and made it extremely difficult to promote the ecosystem. According to Papers with Code, PyTorch is the dominant framework among all commonly used frameworks from 2016 to 2023. As a self-developed AI convergence framework in China, MindSpore actively responds to industry requirements and continuously promotes the evolution of AI frameworks in terms of efficiency, usability, innovation, and user experience.
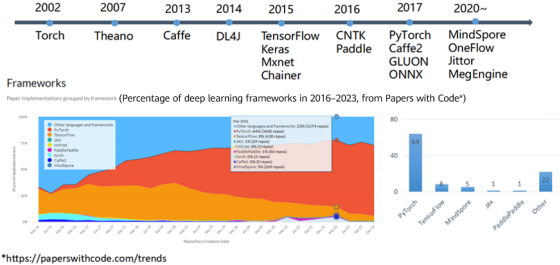
Figure 1 Deep learning framework ecosystem
To help users efficiently port PyTorch code to the MindSpore ecosystem, MindSpore and Pengcheng Laboratory jointly developed MSAdapter, an adaptation tool for the MindSpore ecosystem. MSAdapter, a collaboration between MindSpore and Pengcheng Laboratory, was created to facilitate the seamless porting of PyTorch code to the MindSpore ecosystem. It helps users efficiently use the Ascend computing power of the China Computing NET, and can quickly port code to the MindSpore ecosystem without changing the original PyTorch user habits. By leveraging the powerful Ascend computing capabilities of the China Computing NET, users can efficiently port their code to the MindSpore ecosystem using this tool without having to alter their familiar PyTorch user habits.
The APIs on MSAdapter are developed with a PyTorch-based design, enabling users to easily execute their PyTorch code on Ascend with minimal modifications. Currently, MSAdapter has been adapted to more than 800 APIs such as torch, torch.nn, torch.nn.function and torch.linalg, fully supporting Torchvision. And the porting of more than 70 mainstream PyTorch models has been verified on MSAdapter ModelZoo.
MSAdapter has been open-sourced in the OpenI community, which provides inclusive NPU computing resources for developers.
Code repositories:
https://openi.pcl.ac.cn/OpenI/MSAdapter
Resources:
https://openi.pcl.ac.cn/OpenI/MSAdapter/modelarts/notebook/create
MSAdapter Overall Design
MSAdapter is designed in a user-friendly manner, which can adapt PyTorch code to Ascend devices without user awareness. With the PyTorch APIs as references, MSAdapter provides users with a set of medium- and high-level model building and data processing APIs that are identical in functionality to those found in PyTorch. Figure 2 shows the structure of MSAdapter:
· Lightweight encapsulation
· Identical APIs and functions with PyTorch
· Adaptation of PyTorch code to Ascend with a few modifications
· Native MindSpore APIs supported
· High performance
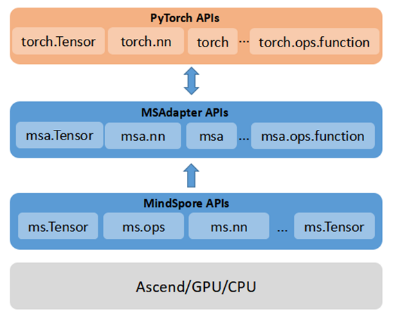
Figure 2 MSAdapter API layers
Quick Start on MSAdapter
1. Installing MSAdapter
Installation Using pip
pip install msadapter
Installation Using Source Code
git clone https://git.openi.org.cn/OpenI/MSAdapter.git
cd MSAdapter
python setup.py install
2. Using MSAdapter
The following uses an AlexNet model as an example. The PyTorch code for training the CIFAR-10 dataset is converted to the MSAdapter code. The complete code can be obtained on MSAdapter ModelZoo (https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/alexnet).
2.1 Modifying the Import Packages
# PyTorch import packages
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms.functional import InterpolationMode
import argparse
## MSAdapter import packages
import msadapter.pytorch as torch
import msadapter.pytorch.nn as nn
from msadapter.pytorch.utils.data import DataLoader
from msadapter.torchvision import datasets, transforms
from msadapter.torchvision.transforms.functional import InterpolationMode
import mindspore as ms
import argparse
2.2 Processing Data (Consistent)
# PyTorch data processing
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616])
])
# MSAdapter data processing
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616])
])
2.3 Defining the Model (Consistent)
# PyTorch model definition
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 10) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, (11, 11), (4, 4), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(64, 192, (5, 5), (1, 1), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(192, 384, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(384, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
return self._forward_impl(x)
def _forward_impl(self, x):
out = self.features(x)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
# MSAdapter model definition
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 10) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, (11, 11), (4, 4), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(64, 192, (5, 5), (1, 1), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(192, 384, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(384, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
return self._forward_impl(x)
def _forward_impl(self, x):
out = self.features(x)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
2.4 Training the Model (Customized Training)
# PyTorch model training
def train(config_args):
train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform)
train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
epochs = config_args.epoch
net = AlexNet().to(config_args.device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
net.train()
print("begin training ......")
for i in range(epochs):
for X, y in train_data:
X, y = X.to(config_args.device), y.to(config_args.device)
out = net(X)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("---------------------->epoch:{}, loss:{:.6f}".format(i, loss))
torch.save(net.state_dict(), config_args.save_path)
# MSAdapter model training
def train(config_args):
train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform)
train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
epochs = config_args.epoch
net = AlexNet().to(config_args.device)
criterion = nn.CrossEntropyLoss()
optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005)
loss_net = ms.nn.WithLossCell(net, criterion)
train_net = ms.nn.TrainOneStepCell(loss_net, optimizer)
net.train()
print("begin training ......")
for i in range(epochs):
for X, y in train_data:
res = train_net(X, y)
print("---------------------->epoch:{}, loss:{:.6f}".format(i, res.asnumpy()))
torch.save(net.state_dict(), config_args.save_path)
3. Running in the Ascend Environment
Currently, the OpenI platform provides inclusive Ascend computing power and MindSpore 2.0 images for external systems. Users can use these resources in their own projects.
Joining the MSAdapter SIG
A large number of MSAdapter developers and users are actively participating in the MSAdapter SIG and you can get a helping hand from our WeChat group. Welcome to join us and give your valuable suggestions!

Or add the assistant on WeChat with the message "MSAdapter SIG".
