[MindSpore Data] Training Data Processing - Unified Vision Interfaces
MindSpore Data Training Data Processing - Unified Vision Interfaces
This blog presents the usability improvement of MindSpore Data, a data processing engine, in the image processing field, and provides an interface usage guide for simplified data preprocessing.
1. Introduction to MindSpore Data
MindSpore Data uses an efficient pipeline framework to implement data processing. The framework can be used to automatically generate pipeline processes based on user-defined data processing steps. As shown in the following figure, each pipeline processes samples in a self-loop manner with high-concurrency capabilities to achieve efficient data preprocessing.
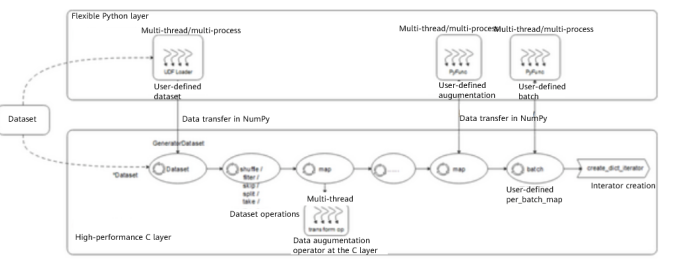
Example of a MindSpore dataset pipeline
(1) Data is concurrently loaded from the storage layer to the buffer by using an existing dataset loading interface or a custom loading class and GeneratorDataset. For details about how to load a dataset, visit https://www.mindspore.cn/docs/en/r1.8/api_python/mindspore.dataset.html
(2) The shuffle process is completed in a memory pool. After samples whose number is equal to the value of buffer_size are cached, some random samples are selected for subsequent processing.
(3) As an execution module, map calls data preprocessing operators at the C layer, such as Decode, Resize, Crop, Normalize, HWC2CHW. It also implements the user-defined PyFunc augmentation with input and output being NumPy data.
For details about the data preprocessing operators in map, visit the following links:
· Vision:
https://www.mindspore.cn/docs/en/r1.8/api_python/mindspore.dataset.vision.html
· Text:
https://www.mindspore.cn/docs/en/r1.8/api_python/mindspore.dataset.text.html
· Audio:
https://www.mindspore.cn/docs/en/r1.8/api_python/mindspore.dataset.audio.html
(4) The samples are batched into batch_size.
With the preceding framework capabilities, map can call operators at the C layer and Python functions. Based on this feature, we created two sets of vision data preprocessing interfaces.
l Developed based on OpenCV of the C++ version. Operators at the C layer provide the multi-thread high-concurrency capability of C++ and has high efficiency.
l Developed based on the Python Pillow library. Operators at the Python layer (PyFunc) perform better in terms of development efficiency and complex implementation than C++ operators, but have lower concurrency capability.
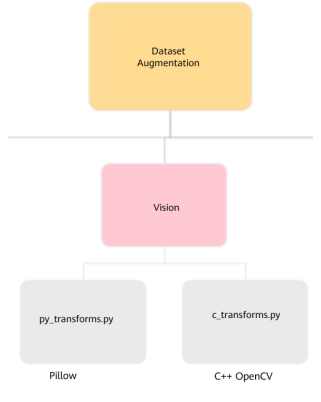
The two sets of interfaces can be used independently or together. However, it may be difficult for users to get started. Therefore, we unified the C++ and Python interfaces, allowing users to call corresponding interfaces for operations through automatic decision-making or explicit transformation.
2. Interface List and Usage of the Old Version
2.1 Interface List
In MindSpore 1.7 and earlier versions, the following interfaces are still used.
mindspore.dataset.vision
mindspore.dataset.vision.c_transforms
mindspore.dataset.vision.py_transforms
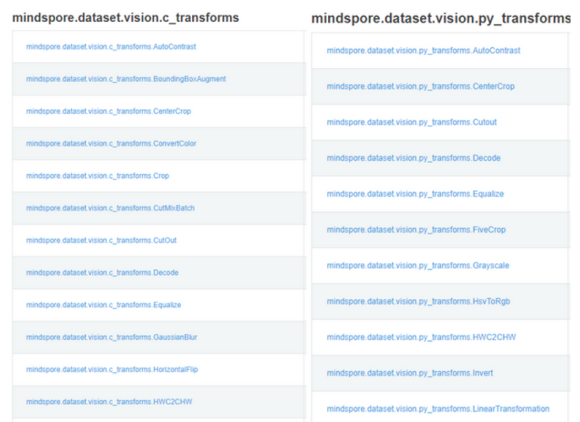
According to the preceding comparison, many interfaces have the same name but different package
names. This causes difficulties for users to understand and select them.
2.2 Usage
If Python and C++ operators are used together, two packages need to be imported for explicit transformation before you call these operators.
import mindspore.dataset.vision.c_transforms as c_vision
import mindspore.dataset.vision.py_transforms as py_vision
trans = [c_vision.Decode()
c_vision.RandomResizedCrop(...),
py_vision.ToPIL(),
py_vision.RandomGrayscale(...),
py_vision.ToTensor()]
dataset = dataset.map(operations=trans, ...)
3 Interface List and Usage of the New Version
3.1 Implementation
The definition of an operator whose interfaces are unified contains different backend implementations, which are invoked by the parse and execute_py interfaces. In addition, self.implementation is used to dynamically mark which layer is invoked for implementation during the operator running.
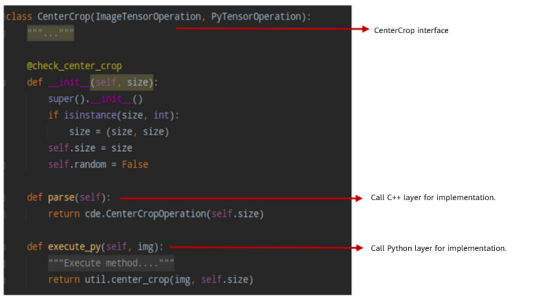
3.2 Interface List
3.3 Usage
All interfaces can be imported by importing a package and can be called for flexible implementation through transformation.
import mindspore.dataset.vision as vision
trans = [vision.Decode()
vision.RandomResizedCrop(...),
vision.ToPIL(),
vision.RandomGrayscale(...),
vision.ToTensor()]
dataset = dataset.map(operations=trans, ...)
4. Summary
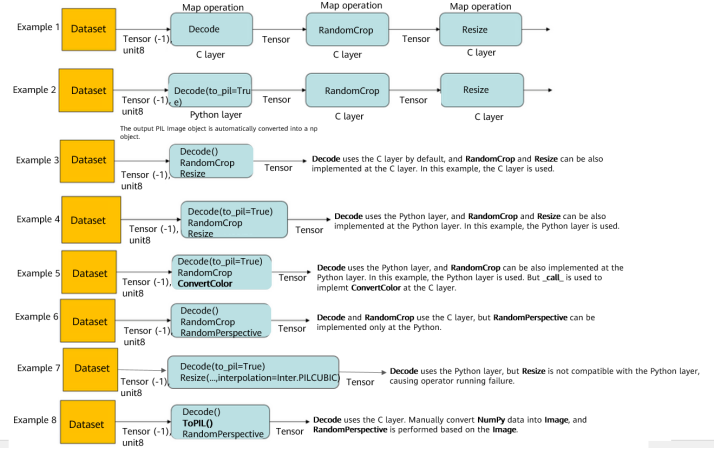
As such, the operator execution logic of the data processing pipeline is as follows:
(1) By default, the C++ layer is used to ensure high efficiency.
(2) If the Python layer needs to be used, options need to be specified or automatically deducted.
Typical data preprocessing operations are as follows: