[MindSpore Made Easy] Conversion from PyTorch Source Code into MindSpore Low-Level API Code and Single-Server Single-Device Training on Ascend Processors
MindSpore Made Easy Conversion from PyTorch Source Code into MindSpore Low-Level API Code and Single-Server Single-Device Training on Ascend Processors
August 12, 2022 1. Overview This blog describes how to convert the PyTorch source code into MindSpore low-level API code and implement single-server single-device training on Ascend processors. The following figure shows the differences between the training processes of MindSpore high-level APIs, low-level APIs, and PyTorch. 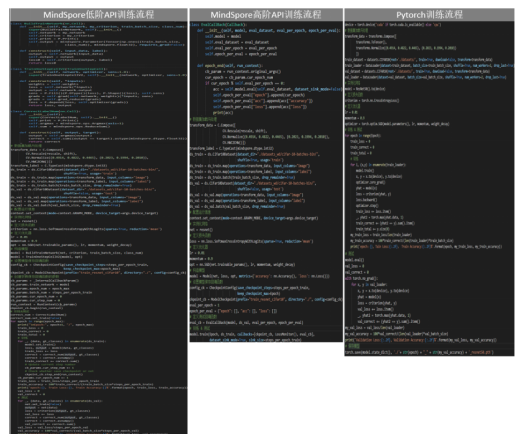
Similar to MindSpore high-level APIs, low-level API training also requires run configuration, data reading and preprocessing, network definition, loss function definition and optimizers. 2. Model Construction (Low-Level APIs) During model construction, the network prototype and loss function are encapsulated first. Then the combined model is encapsulated with an optimizer to form a network that can be used for training. Training and validation require the accuracy on the training set. Therefore, the return value must contain the output value of the network.
import mindsporefrom mindspore import Modelimport mindspore.nn as nnfrom mindspore.ops import functional as Ffrom mindspore.ops import operations as P
class BuildTrainNetwork(nn.Cell):
'''Build train network.'''
def __init__(self, my_network, my_criterion, train_batch_size, class_num):
super(BuildTrainNetwork, self).__init__()
self.network = my_network
self.criterion = my_criterion
self.print = P.Print()
# Initialize self.output
self.output = mindspore.Parameter(Tensor(np.ones((train_batch_size,
class_num)), mindspore.float32), requires_grad=False)
def construct(self, input_data, label):
output = self.network(input_data)
# Get the network output and assign it to self.output
self.output = output
loss0 = self.criterion(output, label)
return loss0
class TrainOneStepCellV2(TrainOneStepCell):
'''Build train network.'''
def __init__(self, network, optimizer, sens=1.0):
super(TrainOneStepCellV2, self).__init__(network, optimizer, sens=1.0)
def construct(self, *inputs):
weights = self.weights
loss = self.network(*inputs)
# Obtain self.network from BuildTrainNetwork
output = self.network.output
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
# Get the gradient of the network parameters
grads = self.grad(self.network, weights)(*inputs, sens)
grads = self.grad_reducer(grads)
# Optimize model parameters
loss = F.depend(loss, self.optimizer(grads))
return loss, output
# Construct model
model_constructed = BuildTrainNetwork(net, loss_function, TRAIN_BATCH_SIZE, CLASS_NUM)
model_constructed = TrainOneStepCellV2(model_constructed, opt)
3 Training and Validation (Low-Level APIs) Similar to PyTorch, network training and validation are performed with low-level APIs.
class CorrectLabelNum(nn.Cell):
def __init__(self):
super(CorrectLabelNum, self).__init__()
self.print = P.Print()
self.argmax = mindspore.ops.Argmax(axis=1)
self.sum = mindspore.ops.ReduceSum()
def construct(self, output, target):
output = self.argmax(output)
correct = self.sum((output == target).astype(mindspore.dtype.float32))
return correct
def train_net(model, network, criterion,
epoch_max, train_path, val_path,
train_batch_size, val_batch_size,
repeat_size):
"""define the training method"""
# Create dataset
ds_train, steps_per_epoch_train = create_dataset(train_path,
do_train=True, batch_size=train_batch_size, repeat_num=repeat_size)
ds_val, steps_per_epoch_val = create_dataset(val_path, do_train=False,
batch_size=val_batch_size, repeat_num=repeat_size)
# CheckPoint CallBack definition
config_ck = CheckpointConfig(save_checkpoint_steps=steps_per_epoch_train,
keep_checkpoint_max=epoch_max)
ckpoint_cb = ModelCheckpoint(prefix="train_resnet_cifar10",
directory="./", config=config_ck)
# Create dict to save internal callback object's parameters
cb_params = _InternalCallbackParam()
cb_params.train_network = model
cb_params.epoch_num = epoch_max
cb_params.batch_num = steps_per_epoch_train
cb_params.cur_epoch_num = 0
cb_params.cur_step_num = 0
run_context = RunContext(cb_params)
ckpoint_cb.begin(run_context)
print("============== Starting Training ==============")
correct_num = CorrectLabelNum()
correct_num.set_train(False)
for epoch in range(epoch_max):
print("
Epoch:", epoch+1, "/", epoch_max)
train_loss = 0
train_correct = 0
train_total = 0
for _, (data, gt_classes) in enumerate(ds_train):
model.set_train()
loss, output = model(data, gt_classes)
train_loss += loss
correct = correct_num(output, gt_classes)
correct = correct.asnumpy()
train_correct += correct.sum()
# Update current step number
cb_params.cur_step_num += 1
# Check whether to save checkpoint or not
ckpoint_cb.step_end(run_context)
cb_params.cur_epoch_num += 1
my_train_loss = train_loss/steps_per_epoch_train
my_train_accuracy = 100*train_correct/(train_batch_size*
steps_per_epoch_train)
print('Train Loss:', my_train_loss)
print('Train Accuracy:', my_train_accuracy, '%')
print('evaluating {}/{} ...'.format(epoch + 1, epoch_max))
val_loss = 0
val_correct = 0
for _, (data, gt_classes) in enumerate(ds_val):
network.set_train(False)
output = network(data)
loss = criterion(output, gt_classes)
val_loss += loss
correct = correct_num(output, gt_classes)
correct = correct.asnumpy()
val_correct += correct.sum()
my_val_loss = val_loss/steps_per_epoch_val
my_val_accuracy = 100*val_correct/(val_batch_size*steps_per_epoch_val)
print('Validation Loss:', my_val_loss)
print('Validation Accuracy:', my_val_accuracy, '%')
print("--------- trains out ---------")
4 Script Running Run the command:
python MindSpore_1P_low_API.py --data_path=xxx --epoch_num=xxx
Run the script on the terminal in the development environment and the network output is displayed.
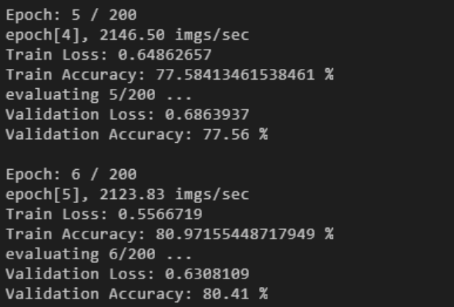
Note: High-level APIs support model training in data offloading mode, which is not supported by low-level APIs. Therefore, model training with high-level APIs is faster than that with low-level APIs. Performance comparison: Low-level APIs: 2000 imgs/sec; high-level APIs: 2200 imgs/sec