MindSpore EPP-MVSNet Model: High-Precision and Efficient 3D Reconstruction
MindSpore EPP-MVSNet Model: High-Precision and Efficient 3D Reconstruction
October 25, 2021
Author: Yu Fan
Blog Source: https://zhuanlan.zhihu.com/p/424375514
Background
Multi-view Stereo (MVS) is an algorithm for predicting an image depth through pixel-level dense matching with images taken from a multi-view angle and a camera pose and by using spatial geometric relationships, and is widely applied to AR/VR, gaming, and surveying. Since MVSNet[1] was proposed, the learning-based method of constructing multi-view to cost volume based on fronto-parallel and differentiable homography proves its advantages in more and more public datasets. However, these methods are greatly affected by the depth assumption in terms of prediction precision and efficiency. When the depth range is large, it can be difficult to balance calculation amount and precision. Later, CasMVSNet [2] raises a multi-stage pipeline for predicting depth initially with a low-resolution cost volume at the coarse stage and refine predicted coarse depth at high resolution in a narrow depth range. The coarse-to-fine paradigm controls the overall number of depth assumptions to some extent. Therefore, the depth prediction precision can be improved without increasing the computation workload. However, there isn't much discussion of depth assumptions.
To solve this problem, MindSpore proposes a high-precision, efficient, and dense reconstruction algorithm EPP-MVSNet based on depth assumptions. EPP-MVSNet inherits the coarse-to-fine idea. Based on the coarse-to-fine idea, EPP-MVSNet proposes the EAM (epipolar assembling) and ER (entropy refining strategy) modules for optimizing the depth assumptions in the coarse and fine phases. In addition, the 3D regular network is simplified to further improve the computing efficiency of the entire model. By March 2021, EPP-MVSNet ranked No. 1 in the intermediate list and No. 4 in the advanced list on the public dataset Tanks & Temples in the dense reconstruction field. Related papers have been received by ICCV 2021. The code has been released based on MindSpore open source. Welcome to use it.
Code link: https://gitee.com/mindspore/models/tree/master/research/cv/eppmvsnet
Terms
Depth assumption: a depth assumption plane on which a three-dimensional point corresponding to a pixel may be located in a depth prediction process.
Depth interval: interval between depth assumption planes in the depth prediction process.
Polar line: A real three-dimensional point of an object and the camera center of the main/auxiliary view form a polar plane. The intersection line between the polar plane and the auxiliary view is called a polar line.
Main view: image that requires depth prediction in the depth prediction process.
Auxiliary view: a set of images that are most closely related to the main view in the depth prediction process.
Cost Volume: a set formed by matching relationships between pixels in the main view within a preset depth assumption range and corresponding sampling points in the auxiliary view in a depth prediction process.
Algorithm description
The Learning-based coarse-to-fine method mainly includes the following steps: two-dimensional feature extraction, cost volume construction, 3D regular expression, and depth result prediction. The EAM and ER modules of EPP-MVSNet focus on cost volume construction. The following figure shows the algorithm pipeline.
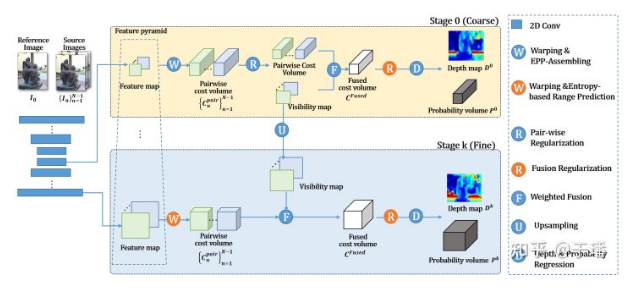
Epipolar Assembling Module
As a key step in most coarse-to-fine dense reconstruction methods, the configuration of depth hypothesis varies greatly in different phases. In the coarse phase, several depth assumptions in a global depth range need to be set. In addition, to control a size of a cost volume, only a relatively small quantity of depth assumptions can be set in this phase. As a result, the depth assumption interval in the coarse phase is relatively large, which is reflected in the auxiliary view. The sampling points of the epipolar line are relatively sparse, and key feature points are easily missed.
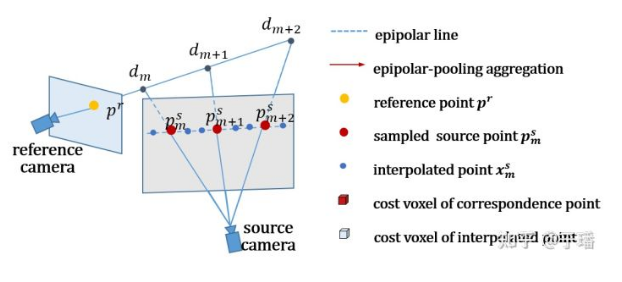
To solve this problem, EPP-MVSNet proposes the epipolar assembling module (EAM), which calculates the distribution of original sampling points on the auxiliary view in advance under the default depth assumption range, and inserts new sampling points adaptively according to the distribution interval. According to the distribution of sampling points generated by different spatial geometric relationships between the main view and different auxiliary views, EPP-MVSNet can adaptively maintain the density of sampling points and reduce the chance of missing key feature points.
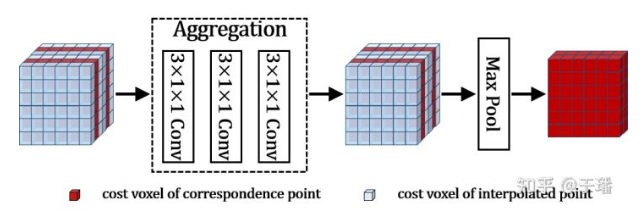
Although adaptively inserting sample points increases the sampling density, it inevitably leads to a linear increase of the cost volume. In addition, the shapes of the cost volumes generated by the main view and different auxiliary views may be different. To control the size of the cost volume, the EAM uses deep convolution to extract simple information from the cost volume after interpolation. Then, the EAM selects max pooling with different window sizes and steps based on interpolation conditions to down-sample the cost volume so that the cost volume changes back to the shape before interpolation. The dynamic pooling of the EAM aggregates the cost information of the interpolation point in the cost volume depth dimension to the original point.
The cost volume processed by the EAM module still maintains the original shape. However, each cost voxel aggregates information about adjacent interpolation sampling points, and its perception is much better than that before the processing. In this way, more accurate depth prediction can be performed.
Entropy Refining Strategy
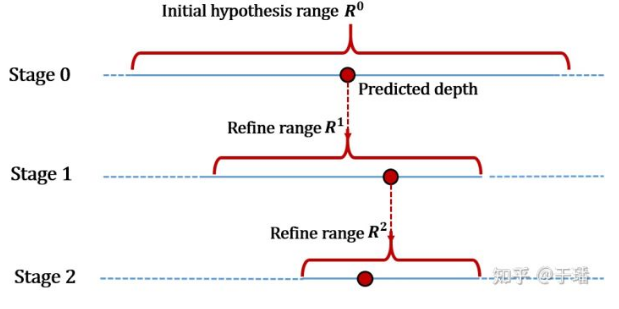
EAM mostly solves the depth assumption in the coarse phase. The refine phase centers the depth assumption on the depth predictions from the preceding phases and extends a certain range to each side. Since depth prediction in the refine phase relies on high-resolution features, too many depth assumptions are not recommended considering the computing efficiency. If the depth assumption range is narrowed down for predicting the precision, the depth prediction in the pre-stage phase may be inaccurate and the true value may be excluded. If the depth assumption range is relatively relaxed, the depth interval increases, and the prediction precision decreases.
To solve the preceding problem, EPP-MVSNet proposes the entropy refining strategy (ER) module, which can adaptively adjust the depth assumption range of the next phase based on the depth prediction of the current phase. The ER module uses the property of entropy to express the confidence of the model in the prediction result. A larger entropy indicates that the model is less confident in the prediction result.
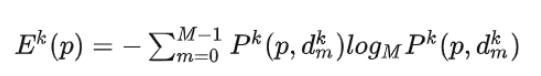
As shown above, E represents entropy, k represents a current phase, M represents a quantity of depth assumptions of the current phase, P represents a depth prediction probability, p represents a pixel location, and d represents a corresponding depth assumption.
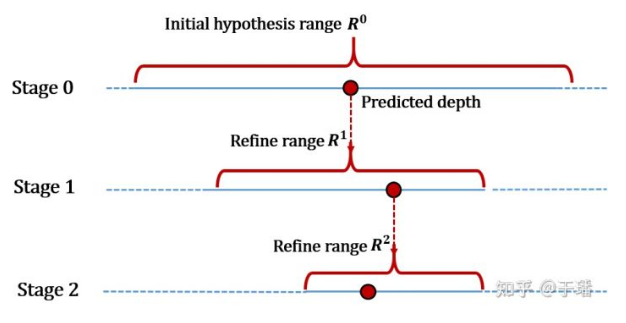
After the entropy corresponding to each point on the depth map of the current phase is obtained, the assumed depth range of the next phase can be calculated according to the foregoing formula. r represents a depth range, and λ is a hyperparameter.
The ER module may adaptively determine, according to a depth prediction status of each phase, an appropriate depth assumption range of a next phase, so as to further refine depth prediction precision, and avoid cases where a true value is incorrectly excluded from the depth assumption range.
Light-weighted Network
EPP-MVSNet uses weighted aggregation for cost volume aggregation by referring to [3]. In addition, to save the computing workload, the visibility map as the weight is generated only in the coarse phase. In subsequent phases, the weight is reused through upsampling. Inspired by [4], EPP-MVSNet uses pseudo-3D convolution instead of traditional 3D convolution to further improve the computing efficiency of the entire model. Specifically, the 3D regular network of EPP-MVSNet consists of 3*1*1 and 1*3*3 convolutions, and the cost volume information is extracted by dimension.
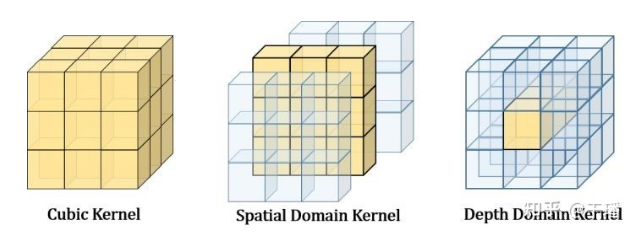
With the preceding settings, the overall computing efficiency and video memory usage of EPP-MVSNet are further improved.
Result
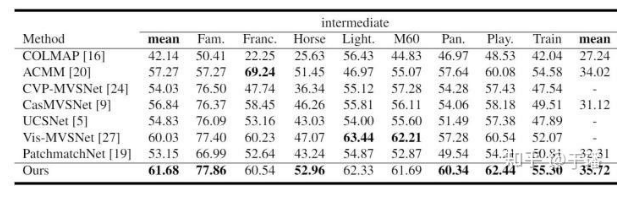
As shown in the preceding figure, the EPP-MVSNet that uses the EAM and ER modules surpasses the SOTA method on the Tanks and Temples intermediate benchmark.
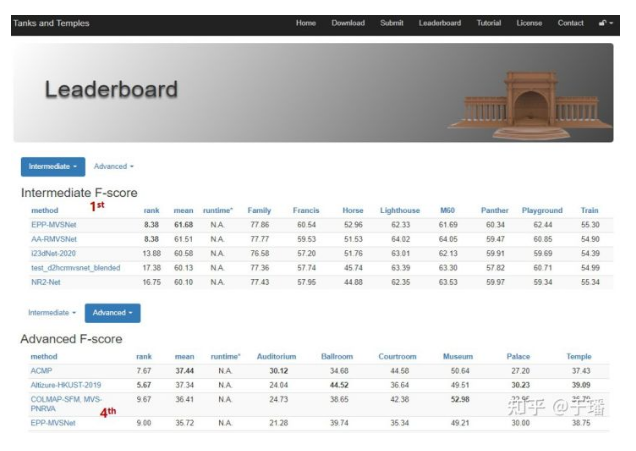
By March 18, 2021, EPP-MVSNet ranked No. 1 in the Tanks & Temples intermediate benchmark and No. 4 in the advanced benchmark.
Summary
In the coarse phase, EAM effectively resolves the sampling problem caused by a relatively large depth interval. The dynamic pooling design controls the calculation amount and improves the depth prediction precision. The ER module provides a new idea for the depth hypothesis setting of the coarse-to-fine method in the refine phase. Thanks to lightweight network design and the use of pseudo-3d convolution, EPP-MVSNet also outperforms most SOTA methods in runtime, second only to PatchmatchNet[5].
That's all for the introduction to EPP-MVSNet. You are welcome to discuss and give suggestions on GitHub.
MindSpore website: https://www.mindspore.cn/en
GitHub: https://github.com/mindspore-ai
References:
[1] Yao Y, Luo Z, Li S, et al. Mvsnet: Depth inference for unstructured multi-view stereo[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 767-783.
[2] LaroGu X, Fan Z, Zhu S, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 2495-2504.chelle H, Erhan D, Bengio Y. Zero-data learning of new tasks[C]//AAAI. 2008, 1(2): 3.
[3] https://arxiv.org/abs/2008.07928
[4] Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3d residual networks[C]//proceedings of the IEEE International Conference on Computer Vision. 2017: 5533-5541.
[5] Wang F, Galliani S, Vogel C, et al. PatchmatchNet: Learned Multi-View Patchmatch Stereo[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 14194-14203.