MindSpore Transformer Model Library: Handling Transformer Models Using Only Several Code Lines With 20% Higher Performance Than NVIDIA Megatron
MindSpore Transformer Model Library: Handling Transformer Models Using Only Several Code Lines With 20% Higher Performance Than NVIDIA Megatron
August 12, 2022
Author: Jin Xuefeng
Blog Source: https://zhuanlan.zhihu.com/p/419182257
MindSpore 1.8.1 will be released recently. In this version, we will launch the Transformer model library and introduce two model acceleration libraries. This document describes the Transformer library.
The Transformer model and self-supervised pre-training mode opened up a new direction for multiple AI application fields such as NLP and CV. By increasing the number of model parameters and data scale, the performance of the pre-trained model in the actual field can be continuously improved.
However, the increase in the number of parameters brings new challenges to model training. Transformer models, such as GPT-3 and T5, usually require at least hundreds of GPUs and take months for training, consuming millions of dollars. How to train these mega-size models in a more efficient and distributed manner is a challenge that the entire industry is confronted with.
Currently, many enterprises and open-source organizations have launched dedicated Transformer model training libraries. The PyTorch-based Megatron-LM training library of NVIDIA shows outstanding performance in various aspects. MindSpore also launched a Transformer model training library. Compared with Megatron, MindSpore's Transformer model training library features higher development efficiency, memory usage efficiency, and performance, with the support of diverse backends.
1. Performance Result Comparison
The 10-billion-scale GPT (hiddensize = 5120, num_layers = 35, num_heads = 40) performance is tested on the 8-processor, 16-processor, and 32-processor A100 clusters. The number of parallel channels is set to 8, the number of parallel data channels is set to 1, 2, and 4, and the number of global batches is set to 1024. For Megatron, the micro batch size is 2 (reached the upper limit). For MindSpore, the micro batch size is 8. Compared with Megatron, MindSpore features higher memory utilization and can train a larger batch size.
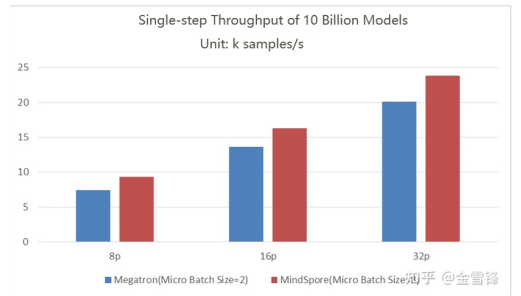
Throughput comparison
As shown in the preceding figure:
The maximum throughput of 8-processor Megatron is 7.4 k samples/s, and that of MindSpore is 9.3 k samples/s, which is 25% higher than that of Megatron.
The maximum throughput of 16-processor Megatron is 13.6 k samples/s, and that of MindSpore is 16.9 k samples/s, which is 24% higher than that of Megatron.
The maximum throughput of 32-processor Megatron is 20.1 k samples/s, and that of MindSpore is 23.8 k samples/s, which is 18% higher than that of Megatron.
These performance improvements are mainly attributed to the powerful graph computing convergence technology and refined automatic parallel scheduling capability of MindSpore.
2. Higher Development Efficiency
MindSpore Transformer uses the built-in parallel technology of MindSpore to automatically detect topologies, efficiently converge data parallelism and model parallelism policies, and implement seamless switchover from a single device to a large-scale cluster.
Easy-to-use Parallel Technology: MindSpore Transformer training can be switched from a single-device to a cluster with multiple devices in one click.
context.set_auto_parallel_context(parallel_mode="stand_alone") # single-device
context.set_auto_parallel_context(parallel_mode="data_parallel") # data parallelism
context.set_auto_parallel_context(parallel_mode="semi_auto_parallel") # semi-automatic parallelism
Users can add --parallel_model=data_parallel to the startup script to enable the preceding functions.
Diverse Parallelism Features Enabled in just One Click: The following code shows how to set model parallelism in the MindSpore Transformer library. MindSpore predefines a set of basic models that can implement model parallelism on Transformer networks and implement foundation model training by configuring model_parallel and data_parallel to.
parallel_config = TransformerOpParallelConfig(model_parallel=config.model_parallel, # model parallelism
data_parallel=config.data_parallel, # data parallelism
recompute=True, # Enable recalculation
optimizer_shard=True) # Enable optimizer parallelism
transformer = Transformer(hidden_size=config.hidden_size,
batch_size=config.batch_size,
ffn_hidden_size=config.hidden_size * 4,
src_seq_length=config.seq_length,
tgt_seq_length=config.seq_length,
encoder_layers=config.num_layers,
attention_dropout_rate=config.dropout_rate,
hidden_dropout_rate=config.dropout_rate,
decoder_layers=0,
num_heads=config.num_heads,
parallel_config=config.parallel_config)
The MindSpore framework features rich basic parallel capabilities, which makes the implementation of MindSpore Transformer simple. 7,000 lines of code in MindSpore framework can compare to tens of thousands of lines of Megatron code. Compared with libraries of other frameworks, MindSpore Transformer has the following advantages: The code is more flexible and universal, which facilitates the customization and generalization of large models.
In addition, the MindSpore Transformer library provides multiple parallel technologies: pipeline, optimizer, and expert parallelism. Users can continuously pay attention to the latest progress of the warehouse.
3. Prospect
Foundation model training has always been one of the hot topics in the industry. Foundation models in and outside China are constantly emerging, and the MindSpore Transformer library will be continuously updated and evolved. In the future, we plan to add more pre-trained language models, such as MoE and multi-modal models.
Gitee code repository link:
MindSpore/transformergitee.com/mindspore/transformer
Github: