MindSpore paper 13 [IEEE TPAMI] Zero-DCE++, MindSpore Real-time Zero-Reference Low-Light Image Enhancement Algorithm
MindSpore paper 13 IEEE TPAMI Zero-DCE++, MindSpore Real-time Zero-Reference Low-Light Image Enhancement Algorithm
By Li Ruifeng
Article Source: https://zhuanlan.zhihu.com/p/527358875
As an open source AI framework, MindSpore brings device-edge-cloud synergy, simplified development, ultimate performance, ultra-large-scale AI pre-training, and secure and reliable experience to production, education, research, and developers. Since its open source debut on March 28, 2020, the number of downloads has exceeded one million. MindSpore has been seen in hundreds of AI top conference papers and been introduced into more than 100 major universities. It has been put into commercial use on over 5000 apps through Huawei Mobile Services (HMS) and has a huge number of developers. It is widely used in AI computing centers, smart manufacturing, finance, cloud, wireless, datacom, energy, consumer 1+8+N, intelligent vehicles and device-edge-cloud scenarios. It is the open source software with the highest Gitee index. You are welcome to participate in open source contributions, kits, model brainstorming, industry innovation and application, algorithm innovation, academic cooperation, and AI book cooperation, and submit your application cases in the cloud, device, edge, and security fields.
Thanks to the support of MindSpore from the scientific, academic, and industrial circles, MindSpore-based AI papers accounted for 6% of all AI frameworks in Q2 2022, ranking No. 2 in the world for the first time and No. 3 in Q4 2021. Thank CAAI and teachers from universities for their support. We will continue to work hard to innovate AI scientific research. The MindSpore community supports research on top-level conference papers and continuously builds original AI achievements. This blog briefly introduces the paper Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation from Nankai University.
1. Background
Affected by the environment and devices, people often obtain some low-light images, which not only degrade people's visual experience, but also greatly reduce the reliability of the computer vision system. Therefore, low-light image enhancement is very crucial to improve the visual quality of images and the performance of computer vision systems in extreme lighting conditions.
This article introduces the paper in the field of low-light image enhancement (LLIE), Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation, published in the IEEE TPAMI journal. It is improved based on the Zero-DCE Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement published in IEEE CVPR in 2020.


2. People Working on the MindSpore Framework-based Algorithm Implementation
Guo Chunle, who is a postdoctoral teacher in the Media Computing Lab of the College of Computer Science of Nankai University. The cooperative mentor is Professor Cheng Mingming. Guo Chunle mainly researches deep learning-based image/video restoration and enhancement technologies, such as low-light image enhancement, image defogging, and video completion. He published multiple papers in CCF-A conferences and journals such as IEEE CVPR, IEEE TPAMI, and IEEE TIP as the first author or corresponding author.
Jin Xin, who is an undergraduate student from the College of Software, Nankai University, and a scientific research assistant in the Media Computing Lab, College of Computer Science, Nankai University. He mainly researches the low-light image enhancement algorithm based on raw data. He won the third place in NTIRE 2022 Night Photography Rendering, migrated multiple SOTA algorithms to the MindSpore framework and obtained the developer certificate of the MindSpore community.
3. Abstract
3.1 Research Motivation
Many photos are often captured under suboptimal lighting conditions due to inevitable environmental and/or technical constraints. These include inadequate and unbalanced lighting conditions, incorrect placement of objects against extreme back light, and under-exposure during image capturing. Such low-light photos suffer from compromised aesthetic quality and unsatisfactory transmission of information. The former affects viewers’ experience while the latter leads to wrong message being communicated, such as inaccurate object/face recognition. Although deep neural networks show impressive performance in image enhancement and restoration, they inevitably lead to high memory usage and long inference time due to excessive parameters. Low computational costs and fast inference speed of deep models are required in practical applications, especially for real-time devices with limited resources, such as mobile platforms.
3.2 Zero-DCE
Therefore, this paper proposes a new low-light image enhancement strategy, which does not directly perform image-to-image mapping, but reformulates the task as an image-specific curve estimation problem to achieve extremely fast inference. Figure 1 shows the algorithm framework. First, we introduce three important components of Zero-DCE, including the light-enhancement curves (LE-curves), deep curve estimation network (DCE-Net), and non-reference loss functions.
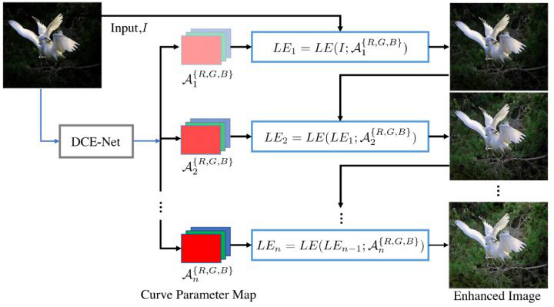
Figure 1: Zero-DCE map
Light-Enhancement Curve (LE-Curve)
Inspired by the curves adjustment used in photo editing software, we designed a kind of curve that can map a low-light image to its enhanced version automatically, where the self-adaptive curve parameters are solely dependent on the input image. There are three objectives in the design of such a curve: 1. Each pixel value of the enhanced image should be in the normalized range of [0,1] to avoid information loss induced by overflow truncation; 2. this curve should be monotonous to preserve the differences (contrast) of neighboring pixels; 3. the form of this curve should be as simple as possible and differentiable in the process of gradient backpropagation.
Deep Curve Estimation Network (DCE-Net)
We employ a simple convolutional network to estimate the parameter map specific to the image, and then enhance the input image iteratively with the light-enhancement curve. The DCE-Net network consists of convolutional layers and activation functions. The skip-connection layer is used to reuse shallow features. Finally, the Tanh activation function is used to output the parameter map between values. Figure 2 shows the network structure of DCE-Net.
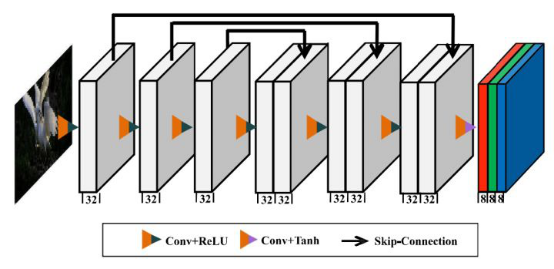
Figure 2: Zero-DCE network structure
Non-Reference Loss Function
For no-reference learning, it is very important to choose a proper loss function. In this method, spatial consistency loss, exposure control loss, color constancy loss, and illumination smoothness loss are used.
Zero-DCE++
Based on sufficient experiments and observations, we optimize Zero-DCE from three aspects and finally obtain Zero-DCE++ with fewer parameters, lower calculation workload, and faster inference speed.
1. Adopting a lightweight network structure
Based on the basic network structure, we use depthwise separable convolution to replace the traditional convolutional layer, greatly reducing the number of network parameters and calculation workload.
2. Simplifying the light-enhancement curve
Based on sufficient experiments, we find that the change is small in each iteration process (as shown in Figure 3). A unified curve parameter can be used for approximate replacement. In this way, not only a quantity of parameters can be reduced, but also the inference speed of the model can be further increased.

Figure 3: Parameter visualization of the enhanced curve after different number of iterations
3. Performing downsampling on the input image to estimate curve parameters
There is a lot of redundant information between the image pixels, and the curve parameter map estimated by the network is smooth. Based on the above reasons, we downsample the input image to estimate the curve parameters, and then upsample the curve parameters to the original size for iterative enhancement of the image. According to the subjective and objective assessment results, 12x downsampling is selected to balance the algorithm performance and computing efficiency. Figure 4 shows the enhancement results of an image at different sampling rates.

Figure 4 Enhancement results of an image at different sampling rates
4. MindSpore Code Link
[The full paper]:https://ieeexplore.ieee.org
[Code implementation based on MindSpore]:
https://gitee.com/mindspore/contrib/tree/master/papers/Zero-DCE++
https://github.com/mindspore-ai/contrib/tree/master/papers/Zero-DCE%2B%2B
5. Technical Highlights of the Algorithm Framework
Zero-DCE++ further reduces the number of parameters by stacking depth-wise and point-wise convolutions. The module code is as follows:
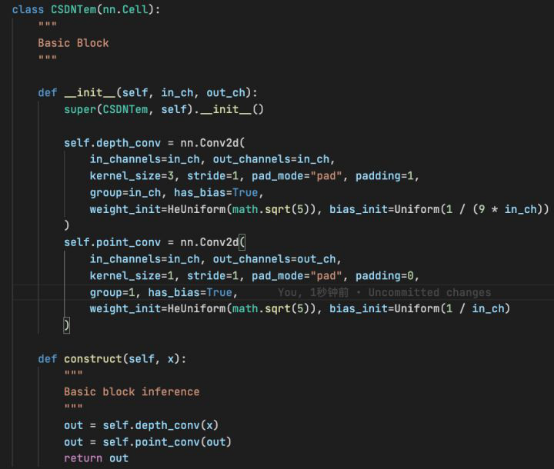
Figure 5 Basic convolution module
As mentioned earlier, Zero-DCE++ supports downsampling of images to increase the inference speed. Therefore, the model implementation process needs to downsample tensors after input. In this implementation, the downsampling operation is bilinear interpolation downsampling, which is implemented by the MindSpore built-in interface mindspore.ops.ResizeBilinear. Zero-DCE++ can reuse shallow features by connecting layers in the channel dimension, which is implemented by the MindSpore built-in interface mindspore.ops.Concat. The channel dimension is restricted by the axis=1 parameter.
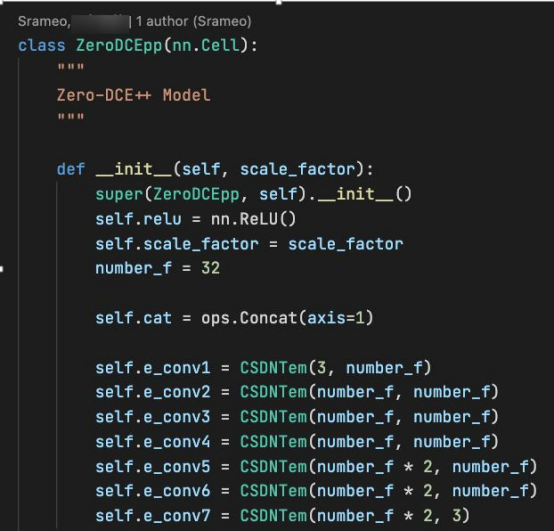
Figure 6
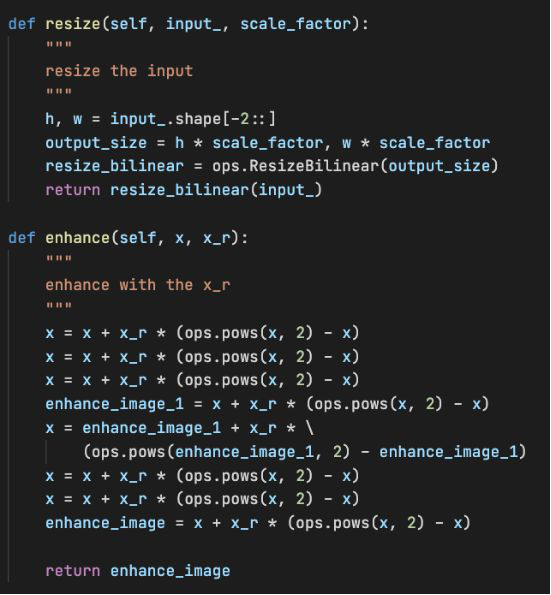
Figure 7 Zero-DCE++ basic network structure with resizing and enhancement operations
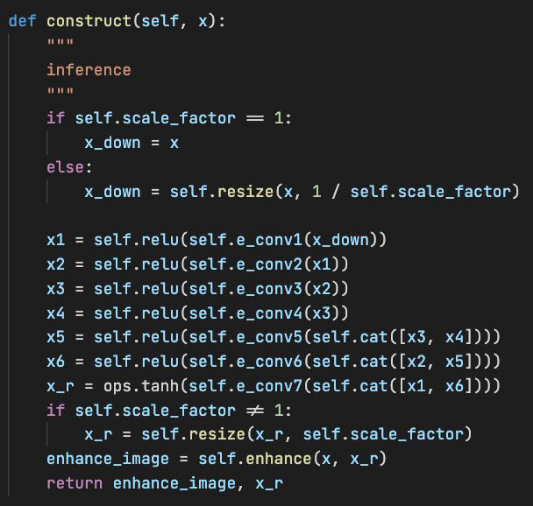
Figure 8 Zero-DCE++ forward process
Note that the enhancement operation of Zero-DCE++ is performed after bilinear interpolation upsampling is performed on curve parameters. That is, images in the enhancement process are not downsampled, so that Zero-DCE++ can balance algorithm performance and calculation efficiency.
The spatial consistency loss of Zero-DCE++ requires calculating the difference between patches of the image. First, perform average operations on the R, G, and B channels of the output tensor to obtain the grayscale image indicating the average strength. Then, use the built-in mindspore.nn.AvgPool2d of MindSpore to perform average pooling operations, in which the kernel size and step are the patch size, on images. Four surrounding patches are required for patch difference calculation, which can be implemented by a custom convolutional operation.
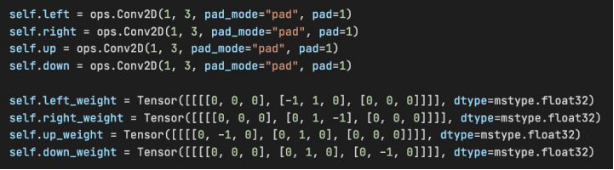
Figure 9 Customizing convolution operations and weights

Figure 10 Performing an operation using custom convolutions and weights
The implementation of exposure control loss is similar to that of spatial consistency loss. First, calculate the grayscale image of the output tensor. Then, use AvgPool2d to perform an average pooling operations, in which the kernel size and step are the patch size, on the image to obtain the tensor indicating the average lighting of each patch. Then, you only need to make a difference between the preset average lighting and the desired average lighting.
The color constancy loss is based on the gray world hypothesis. The implementation method is as follows: Use the built-in mindspore.ops.Split interface of MindSpore to separate the R, G, and B channels of the output tensor, and then use mindspore.ops.ReduceMean to calculate the average value of the three channels one by one. Finally, perform further calculation to obtain the final loss.
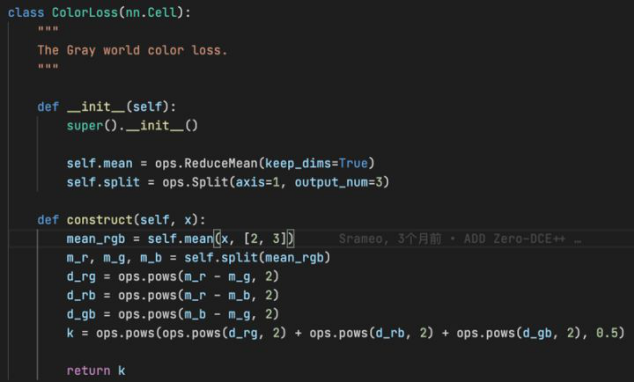
Figure 11 Color constancy loss
In terms of the illumination smoothness loss, the gradient calculation can be easily implemented using the Slice feature of MindSpore, and then the average value can be calculated using the formula.
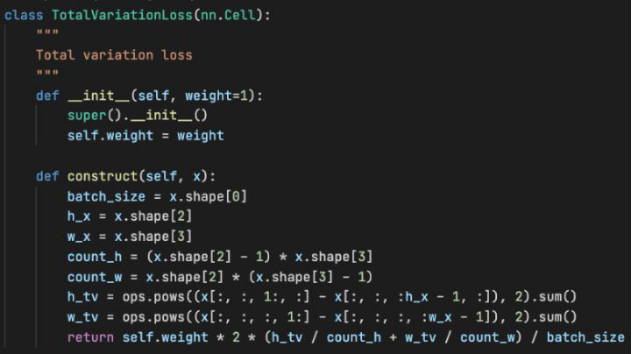
Figure 12 Illumination smoothness loss
The training and test code can be found in the open source repository. Details are not described herein again.
6. Test Result
We provide subjective and objective comparisons between this algorithm and other SOTA algorithms in typical low-light scenarios. Figure 13 shows the comparison of subjective results. It can be seen that Zero-DCE and Zero-DCE++ achieve the optimal visual effect. Table 1 shows the performance comparison of objective evaluation indicators of each algorithm in the test set. It can be seen that although Zero-DCE and Zero-DCE++ are zero-reference algorithms, good quantization results are still obtained.

Figure 13 Comparison of subjective results
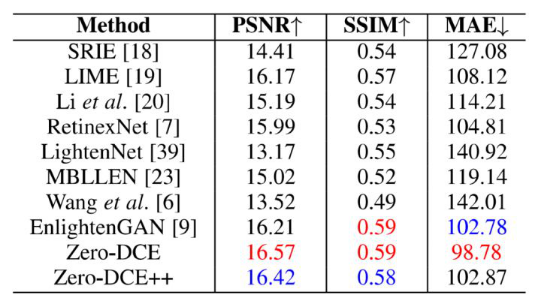
Table 1 Comparison of objective quantitative results
7 Conclusion
We propose a new low-light enhancement learning strategy based on zero-reference learning. This is achieved by formulating a low-light image enhancement task as an image-specific curve estimation problem, and devising a set of differentiable nonreference losses. Based on Zero-DCE, Zero-DCE++ can be further improved by redesigning the network structure, redesigning the curve estimation, and controlling the size of the input image, so that our method can be applied to devices with limited computing resources.
The author of this article is engaged in AI work in the MindSpore community. You are welcome to scan the QR code to join the QQ group and communicate with thousands of MindSpore developers. MindSpore enables thousands of industries and lights up your smart life.
If you have any questions, contact the official QQ group 871543426.
MindSpore website: https://www.mindspore.cn/en
MindSpore forum: https://bbs.huaweicloud.com/forum/forum-1076-1.html
Code repository addresses: