Implementation of the YOLOv3 Object Detection Model (1)
Implementation of the YOLOv3 Object Detection Model (1)
In this blog, I'll introduce how to use the MindSpore framework to build a YOLOv3 object detection model, which is trained on data extracted from the PASCAL VOC 2012 (VOC2012 for short) dataset. I hope my practice would inspire you to contribute to the MindSpore community.
1. Environment Setup
l MindSpore 1.5 or 1.6
l Hardware: GPU
For details about how to prepare for the environment and upgrade MindSpore, visit https://www.mindspore.cn/install/en.
In my practice, the Notebook environment with an installed MindSpore, a V100-32 GB GPU, and an 8-core 64 GB CPU is used. To install the Notebook environment, log in to the ModelArts console and choose DevEnviron > Notebook.
2. Dataset Processing
The VOC2012 dataset contains 20 detection classes, 5717 images for training and 5823 images for validation.
2.1 Extracting Object Data and Clustering Bounding Boxes
Extract images and traverse the bounding boxes both labeled as "person" from the dataset. Then, based on the lengths and widths of the bounding boxes, select nine clustering center points, whose coordinates are used to define the prior box size of YOLOv3.
For details about the code, see the \choose_person folder. Move the Python code in this folder to the VOCtrainval_11-May-2012\VOCdevkit directory of the VOC2012 dataset. (The VOC2012 folder that contains directories such as ImageSets also exists in VOCtrainval_11-May-2012\VOCdevkit.) Then run cluster.py and rand_choose.py in sequence. For details, see readme.txt.
After the two Python programs are executed, TXT files similar to train.txt and val.txt in the VOCtrainval_11-May-2012\VOCdevkit\VOC2012\ImageSets\Main\ directory of the VOC2012 dataset are generated. Place them in the Main\ directory.
2.2 Loading the Dataset
MindSpore provides the VOCDataset API for loading the VOC2012 dataset. For details, see the documentation at the MindSpore official website. The following provides other methods to process and encapsulate it. (See \dataset\voc2012_dataset.py.)
"""Read the VOC2012 dataset""
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as CV
import cv2
import numpy as np
# Execute \dataset\transforms.py
from transforms import reshape_fn, MultiScaleTrans
def create_voc2012_dataset(config, cv_num):
"""create VOC2012 dataset"""
voc2012_dat = ds.VOCDataset(dataset_dir=config.data_path, task="Detection", usage=config.data_usage,
shuffle=config.data_training, num_parallel_workers=8)
dataset_size = voc2012_dat.get_dataset_size()
config.class_to_idx = voc2012_dat.get_class_indexing()
cv2.setNumThreads(0)
if config.data_training:
multi_scale_trans = MultiScaleTrans(config, cv_num)
dataset_input_column_names = ["image", "bbox", "label", "truncate", "difficult"]
dataset_output_column_names = ["image", "annotation", "bbox1", "bbox2", "bbox3", "gt_box1", "gt_box2", "gt_box3"]
voc2012_dat = voc2012_dat.map(operations=CV.Decode(), input_columns=["image"])
voc2012_dat = voc2012_dat.batch(config.batch_size, per_batch_map=multi_scale_trans, input_columns=dataset_input_column_names,
output_columns=dataset_output_column_names, num_parallel_workers=8, drop_remainder=True)
voc2012_dat = voc2012_dat.repeat(config.max_epoch-config.pretrained_epoch_num)
else:
img_id = np.array(range(0,dataset_size))
img_id = img_id.reshape((-1,1))
img_id = ds.GeneratorDataset(img_id, ['img_id'], shuffle=False)
voc2012_dat = voc2012_dat.zip(img_id)
compose_map_func = (lambda image, img_id: reshape_fn(image, img_id, config))
voc2012_dat = voc2012_dat.map(operations=CV.Decode(), input_columns=["image"], num_parallel_workers=8)
voc2012_dat = voc2012_dat.map(operations=compose_map_func, input_columns=["image", "img_id"],
output_columns=["image", "image_shape", "img_id"],
column_order=["image", "image_shape", "img_id"],
num_parallel_workers=8)
hwc_to_chw = CV.HWC2CHW()
voc2012_dat = voc2012_dat.map(operations=hwc_to_chw, input_columns=["image"], num_parallel_workers=8)
voc2012_dat = voc2012_dat.batch(config.batch_size, drop_remainder=True)
voc2012_dat = voc2012_dat.repeat(1)
return voc2012_dat, dataset_size
After the execution, voc2012_dat and dataset_size (indicating the number of images) are returned.
For training (config.data_training==True), the dataset needs to be combined into batches and returned as MindSpore tensors. This requires that images in a batch be reshaped to the same size. In addition, each input image needs to correspond to an output feature map with three scales, that is, bbox1, bbox2, and bbox3 in the preceding script.
The create_voc2012_dataset function maps the data of label bounding boxes in the dataset to the feature maps with specific scales based on the coordinates and size. This is performed by calculating the IoU of the label bounding boxes and the target prior box. The label bounding box with a larger IoU score corresponds to the prior box, and all label bounding boxes are stored in gt_box as tensors. For details, see the _preprocess_true_boxes function in \dataset\transforms.py.
Image augmentation needs to be performed on images used for training, including random resizing, flipping, rotation, cropping, translation, and color change. Positions of the corresponding label bounding boxes also need to be changed. Methods of these operations are stored in the \dataset\transforms.py file and finally conducted in MultiScaleTrans. (The file content is slightly modified. For example, the format of the label bounding box [x y w h] read by VOCDataset is modified as [xmin ymin xmax ymax]. To obtain the source file, visit https://gitee.com/mindspore/models/blob/r1.5/official/cv/yolov3_darknet53/src/transforms.py.
For testing, images also need to be combined into batches and reshaped to the same size. However, the original shape (image_shape) needs to be retained so that the coordinates obtained during model inference can be mapped to the original image. The value of img_id ranges from 0 to n - 1 (n is the value of dataset_size), indicating the row number of the TXT file (generated in section 2.1) to which config.data_usage points. In this way, the corresponding image can be accurately located.
For details about the definition and setting of the config parameter, and the usage method of the dataset, see the followup description relating to model training and testing.
3. Model Building
This section is a reference of the content of the models repository of MindSpore. DarkNet-53 is used as the backbone network of YOLOv3. The following figures show the structures of the DarkNet-53 and YOLOv3 models.
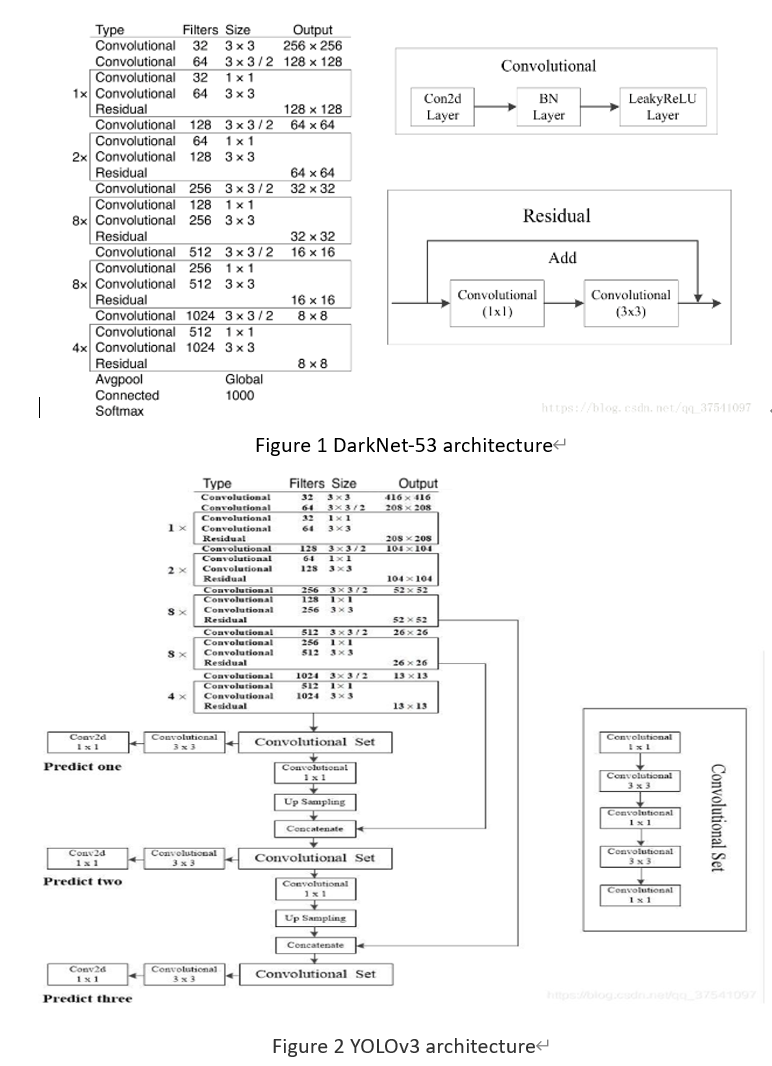
3.1 DarkNet-53
"""YOLOv3 backbone: darknet53"""
import mindspore.nn as nn
from mindspore.ops import operations as P
def conv_block(in_channels,
out_channels,
kernel_size,
stride,
dilation=1):
"""Get a conv2d batchnorm and relu layer"""
pad_mode = 'same'
padding = 0
return nn.SequentialCell(
[nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
pad_mode=pad_mode),
nn.BatchNorm2d(out_channels, momentum=0.1),
nn.ReLU()]
)
class ResidualBlock(nn.Cell):
"""
DarkNet V1 residual block definition.
Args:
in_channels: Integer. Input channel.
out_channels: Integer. Output channel.
Returns:
Tensor, output tensor.
Examples:
ResidualBlock(3, 208)
"""
expansion = 4
def __init__(self,
in_channels,
out_channels):
super(ResidualBlock, self).__init__()
out_chls = out_channels//2
self.conv1 = conv_block(in_channels, out_chls, kernel_size=1, stride=1)
self.conv2 = conv_block(out_chls, out_channels, kernel_size=3, stride=1)
self.add = P.Add()
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out = self.add(out, identity)
return out
class DarkNet(nn.Cell):
"""
DarkNet V1 network.
Args:
block: Cell. Block for network.
layer_nums: List. Numbers of different layers.
in_channels: Integer. Input channel.
out_channels: Integer. Output channel.
detect: Bool. Whether detect or not. Default:False.
Returns:
Tuple, tuple of output tensor,(f1,f2,f3,f4,f5).
Examples:
DarkNet(ResidualBlock,
[1, 2, 8, 8, 4],
[32, 64, 128, 256, 512],
[64, 128, 256, 512, 1024],
100)
"""
def __init__(self,
block,
layer_nums,
in_channels,
out_channels,
detect=False):
super(DarkNet, self).__init__()
self.outchannel = out_channels[-1]
self.detect = detect
if not len(layer_nums) == len(in_channels) == len(out_channels) == 5:
raise ValueError("the length of layer_num, inchannel, outchannel list must be 5!")
self.conv0 = conv_block(3,
in_channels[0],
kernel_size=3,
stride=1)
self.conv1 = conv_block(in_channels[0],
out_channels[0],
kernel_size=3,
stride=2)
self.layer1 = self._make_layer(block,
layer_nums[0],
in_channel=out_channels[0],
out_channel=out_channels[0])
self.conv2 = conv_block(in_channels[1],
out_channels[1],
kernel_size=3,
stride=2)
self.layer2 = self._make_layer(block,
layer_nums[1],
in_channel=out_channels[1],
out_channel=out_channels[1])
self.conv3 = conv_block(in_channels[2],
out_channels[2],
kernel_size=3,
stride=2)
self.layer3 = self._make_layer(block,
layer_nums[2],
in_channel=out_channels[2],
out_channel=out_channels[2])
self.conv4 = conv_block(in_channels[3],
out_channels[3],
kernel_size=3,
stride=2)
self.layer4 = self._make_layer(block,
layer_nums[3],
in_channel=out_channels[3],
out_channel=out_channels[3])
self.conv5 = conv_block(in_channels[4],
out_channels[4],
kernel_size=3,
stride=2)
self.layer5 = self._make_layer(block,
layer_nums[4],
in_channel=out_channels[4],
out_channel=out_channels[4])
def _make_layer(self, block, layer_num, in_channel, out_channel):
"""
Make Layer for DarkNet.
:param block: Cell. DarkNet block.
:param layer_num: Integer. Layer number.
:param in_channel: Integer. Input channel.
:param out_channel: Integer. Output channel.
Examples:
_make_layer(ConvBlock, 1, 128, 256)
"""
layers = []
darkblk = block(in_channel, out_channel)
layers.append(darkblk)
for _ in range(1, layer_num):
darkblk = block(out_channel, out_channel)
layers.append(darkblk)
return nn.SequentialCell(layers)
def construct(self, x):
c1 = self.conv0(x)
c2 = self.conv1(c1)
c3 = self.layer1(c2)
c4 = self.conv2(c3)
c5 = self.layer2(c4)
c6 = self.conv3(c5)
c7 = self.layer3(c6)
c8 = self.conv4(c7)
c9 = self.layer4(c8)
c10 = self.conv5(c9)
c11 = self.layer5(c10)
if self.detect:
return c7, c9, c11
return c11
def get_out_channels(self):
return self.outchannel
def get_darknet53(detect=False):
"""
Get DarkNet53 neural network.
Returns:
Cell, cell instance of DarkNet53 neural network.
Examples:
darknet53()
"""
return DarkNet(ResidualBlock, [1, 2, 8, 8, 4],
[32, 64, 128, 256, 512],
[64, 128, 256, 512, 1024], detect)
(For more information, stay tuned to this series.)