[AI Design Patterns] 02-Data Representation-Embeddings
AI Design Patterns 02-Data Representation-Embeddings
In the previous blog, we introduced Hashed Feature, a pattern for data representation. Hashed Feature is able to reduce dimensions of the categorical data by placing data into hash buckets, but it cannot retain the association between data. To solve this problem, embeddings are introduced.
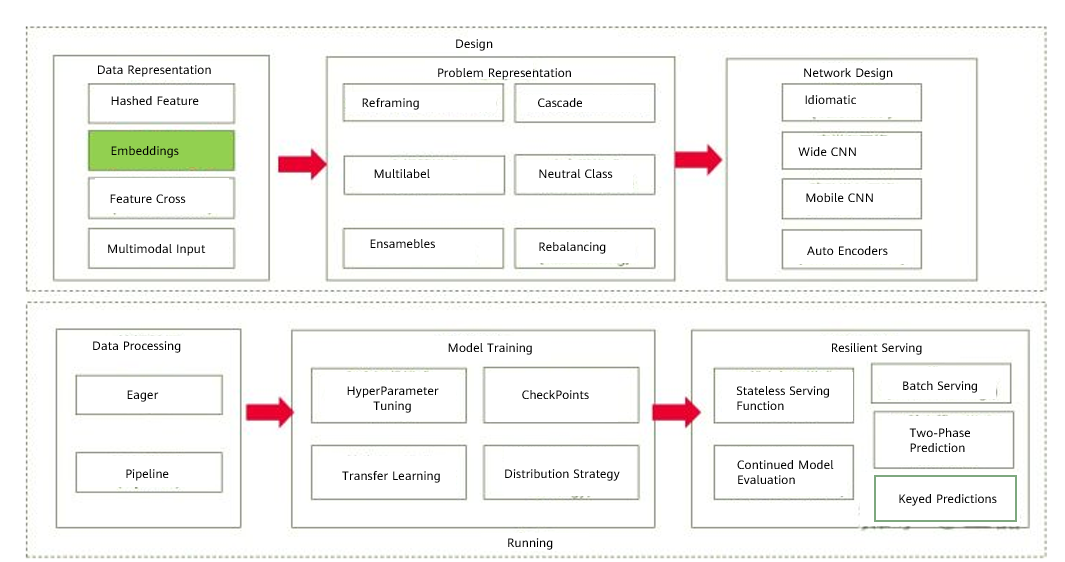
Figure 1 Overview of AI design patterns
Pattern Definition
Embeddings are a learnable data representation that retains the association between data by adding a hidden layer to a neural network, and controls the output dimensions of the hidden layer to ensure that they are less than the input dimensions. In doing so, the dimensions of high-cardinality data can be reduced. Embeddings are a popular practice in modern-day machine learning and have been widely used in fields such as NLP and image processing.
Challenges
Machine learning models must explain how the model's input features relate to the output labels. The model quality is determined by the data quality, as GIGO (garbage in, garbage out) suggests. While handling structured numeric input is fairly simple, the data needed to train a machine learning model may come in myriad varieties, such as categorical features, text, images, audio, time sequences, and many more. These data representations require a meaningful numeric value for the machine learning model, so these features can fit a typical training paradigm. One-hot encoding is a common way to process these data, but it incurs the following shortcomings:
1. Each field in the categorical data may have millions of variables. One-hot encoding converts them into vectors, and thus, inputs are presented as sparse matrices. As a result, a large number of meaningless computations are performed during training, greatly increasing the training time. Take the Xi'an city's postal code 710000 as an example. After encoding, it is converted into 10101101010101110000. If it is represented as a matrix, it has more than 2,097,151 elements, of which 83% is 0.
2. After one-hot encoding is applied to categorical data, each piece of the data is independent and orthogonal. However, in some scenarios, these data are associated with each other and the association information is lost during one-hot encoding. For example, consider the plurality input in the natality dataset. The categorical input has six values: single (1), multiple (2+), twins (2), triplets (3), quadruplets (4), and quintuplets (5). In real life, twins and triplets are more often to be seen than quintuplets. Represented in vector distances, the vector distance between twins and triplets is closer to each other. This association cannot be reflected after one-hot encoding. The same problem also occurs in images and text. Images consist of thousands of pixels, which are not independent of one another. Natural language text is drawn from a vocabulary in the tens of thousands of words, and a word like walk is closer to the word run than to the word book.
Solution
The Embeddings design pattern addresses the problem of representing high-cardinality data densely in a lower dimension by passing the input data through an embedding layer that has trainable weights. This will map the high-dimensional, categorical input variable to a real-valued vector in some low-dimensional space. The weights to create the dense representation are learned as part of the optimization parameters of the model. The Machine Learning Design Patterns describes an example model of predicting a baby's weight. The inputs are gender, gestation weeks, mothers age, and plurality (number of babies), and the output is the predicted value of the baby's weight. For plurality, an embedding layer is used as a replacement for clustering techniques (e.g., K-means clustering) to retain the association between categorical data.
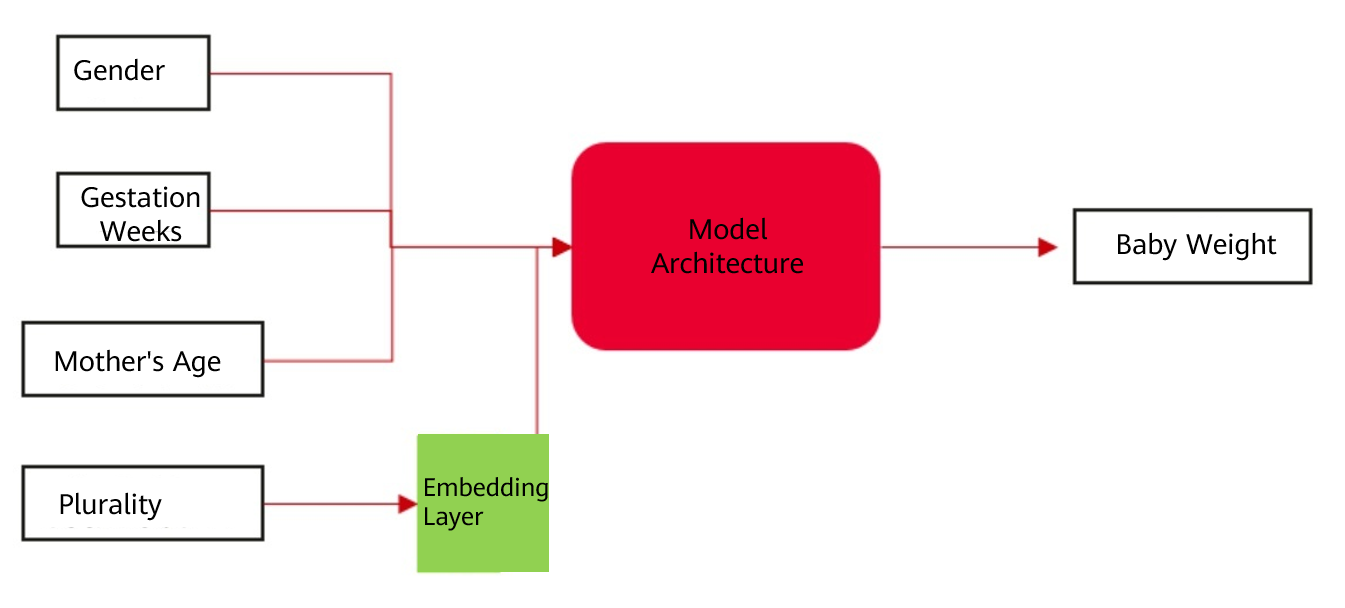
Figure 2 Model for predicting the baby weight
After training, the final encoding information may be as follows:
Plurality
One-hot Encoding
Learned Encoding
Single (1)
[1,0,0,0,0,0]
[0.4, 0.6]
Multiple (2+)
[0,1,0,0,0,0]
[0.1, 0.5]
Twins (2)
[0,0,1,0,0,0]
[-0.1, 0.3]
Triplets (3)
[0,0,0,1,0,0]
[-0.2, 0.5]
Quadruplets (4)
[0,0,0,0,1,0]
[-0.4, 0.3]
Quintuplets (5)
[0,0,0,0,0,1]
[-0.6, 0.5]
The embedding layer is just a hidden layer of the neural network. The weights are associated with each high-cardinality dimension, and the output is passed through the rest of the neural network. Therefore, the weights to create the embedding are learned through the process of gradient descent just like any other weights in the neural network. This means that the generated weight vector represents the most efficient low-dimensional representation of those feature values.
Case Study
Most AI frameworks provide modules or APIs for embeddings, such as nn.Embedding of MindSpore, to store word vectors and use indexes for retrieval. The detail is as follows:
class mindspore.nn.Embedding(vocab_size, embedding_size, use_one_hot=False, embedding_table="normal", dtype=mstype.float32, padding_idx=None)
Options include the dictionary size (vocab_size) and embedded vector size (embedding_size), just name a few. The input tensor has a shape (batch_size, Tensor_length). The elements are integers (int32 or int64). The number of elements must be less than or equal to the dictionary size; otherwise, the corresponding embedding vector will be zero.
The nn.Embedding module provided by MindSpore can also be used to perform the aforementioned model prediction. Assume that the first five lines of the input data are as follows, in which two Singles, one Twins, one Triplets, and one Multiples are included.
weight_pounds,is_male,mother_age,plurality,gestation_weeks
5.2690480617999995,false,15,Single(1),28
6.37576861704,Unknown,15,Single(1),30
1.25002102554,true,14,Twins(2),25
1.99959271634,Unknown,44,Multiple(2+),29
5.06181353552,false,12,Triplets(3),29
Save the input data to babyweight.csv for data processing:
import mindspore
import pandas as pd
from mindspore import Tensor
from mindspore.nn import Embedding
df = pd.read_csv("./babyweight.csv")
df.plurality.head(5)
df.plurality.unique()
CLASSES = {
'Single(1)': 0,
'Multiple(2+)': 1,
'Twins(2)': 2,
'Triplets(3)': 3,
'Quadruplets(4)': 4,
'Quintuplets(5)': 5
}
N_CLASSES = len(CLASSES)
plurality_class = [CLASSES[plurality] for plurality in df.plurality]
EMBED_DIM = 2
Perform encoding based on the hidden embedding layer of MindSpore:
embedding_layer = Embedding(vocab_size=N_CLASSES, embedding_size=EMBED_DIM)
embeds = embedding_layer(Tensor(plurality_class, mindspore.int32))
print(embeds[:5])
The final encoding of the plurality is displayed as follows:
[[ 0.00107764 0.01330051]
[ 0.00107764 0.01330051]
[-0.01124579 0.00154593]
[-0.0111084 -0.00735236]
[ 0.01125109 -0.01859649]]
After calculating vector distances between Single and Twins, Single and Triplets, we can see that the vector distance between Single and Triplets is greater than that between Single and Twins. The result indicates that the associations between data after encoding are retained.
>>> import math
>>> one_to_two = math.sqrt((0.00107764 + 0.01124579)**2 + (0.01330051- 0.00154593)**2)
>>> print(one_to_two)
0.0170304749769729
>>> one_to_three = math.sqrt((0.00107764 + 0.0111084)**2 + (0.01330051+ 0.00735236)**2)
>>> print(one_to_three)
0.02398000438111928
Summary
Embeddings cope well with the problem of high cardinality of categorical data and the sparse matrices caused by one-hot encoding, though there is a loss of information involved in going from a high-dimensional representation to a lower-dimensional representation, which is similar to the Hashed Feature pattern. However, embeddings are able to retain associations between data to some extent. The loss of the representation is controlled by the size of the embedding layer. If the dimension of an embedding layer is too small, too much information is forced into a small vector space and context may be lost. If it is too large, the data size cannot be compressed. The optimal embedding dimension is often found through experimentation. One rule of thumb is to use the fourth root of the total number of unique categorical elements while another is that the embedding dimension should be approximately 1.6 times the square root of the number of unique elements in the category. To do hyperparameter tuning, it might be worth searching within this range.
To date, we have introduced patterns for data representation, and we will elaborate on patterns for data processing in the next blog. Please stay tuned to this series.
References