[MLSys 2022] Paper Introduction: Apollo - Automatic Partition-based Operator Fusion through Layer by Layer Optimization
MLSys 2022 Paper Introduction: Apollo - Automatic Partition-based Operator Fusion through Layer by Layer Optimization
MLSys has published several papers on the MLSys Proceedings page. The first among them, titled Apollo: Automatic Partition-based Operator Fusion through Layer by Layer Optimization, is co-authored by the MindSpore graph kernel fusion team, Mr. Zhao Jie, and Mr. Chen Lei. This is also the third paper published through a collaboration between the MindSpore team and Mr. Zhao Jie. The other two papers, focusing on Auto Kernel Generator (AKG), are available at MICRO 2020 and PLDI 2021. The target of the Apollo paper is automatic optimization of operator fusion. The MindSpore team's ability to innovate—from automatic operator generation to automatic optimization of operator fusion, and then to combinations of these two features—is obvious.
To date, all these features have been implemented on MindSpore, helping achieve graph kernel fusion (GKF). The related code is open source. It is enormously challenging for a team to work on a project that may not have any product for over three years. But the MindSpore team did just that, succeeding in making the first GKF-based automatic operator fusion acceleration engine in China, surpassing the key performances of XLA, the TensorFlow's compiler for machine learning.
Development of Operator Fusion
Operator fusion is one of the most effective methods to optimize processor performance in AI networks. From the perspective of hardware performance, operator fusion is mainly used to solve two performance bottlenecks in AI processors: the memory wall and parallelism.
The memory wall is mainly caused by the memory access bottleneck. In operator fusion, the "producer-consumer" operators that show data dependency on computational graphs are typically fused to improve the access locality of tensor data, thereby solving the memory wall problem. This method, which has been the mainstream technology in operator fusion for many years, is also called buffer fusion.
In previous AI frameworks, buffer fusion with fixed patterns generally required manual code writing—specifically scripts for operator fusion, fusion pass, and pattern matching and modification. This method, however, cannot be generalized with more diverse and complex AI models, because it only fuses and optimizes the pattern combination of a specific operator group in a specific network.
To address this problem, teams of XLA, TVM, MLIR, and other AI compilers/frameworks have focused on optimizing buffer fusion. From the perspective of operator generation, early automatic buffer fusion is similar to Loop Fusion: data-dependent adjacent operators are deeply fused in the Loop space. In this way, the intermediate tensor data is degraded to local variables or even register variables, greatly reducing memory access overhead.
Despite these superior optimization effects, Loop Fusion has an obvious limitation: merging adjacent operator nodes depends on whether the operator loop can be merged effectively. This makes it difficult to further enlarge the size of the fusion subgraph. With rapid developments in AI processors' computing capability, the memory wall problem has become a key factor that restricts the development of fusion technologies. To address this, Alibaba proposed AStitch, which "stitches" interdependent operators together using hierarchical storage media, instead of relying on deep merging of the fusion operator cyclic space.
As for the parallelism problem, ways to solve it through operator fusion have been in the spotlight since the release of Rammer. This problem is caused by a mismatch between the multi-core increase of the processor and the multi-core parallelism of a single operator. With the fast stacking of parallel processor cores, the parallelism of a single operator node in an AI network cannot effectively utilize multi-core resources, especially in the inference scenario. Rammer was created for the parallel orchestration of operator nodes in computational graphs, to improve the overall computation parallelism. This method can achieve a better parallel acceleration effect, especially with parallel branch nodes in the network. To distinguish it from buffer fusion, this fusion mode is called parallel fusion.
But the aforementioned methods are essentially separate. Their features are not combined. To ameliorate the optimization of operator fusion, Apollo tries to combine the advantages of Loop Fusion, Stitch Fusion, and Parallel Fusion.
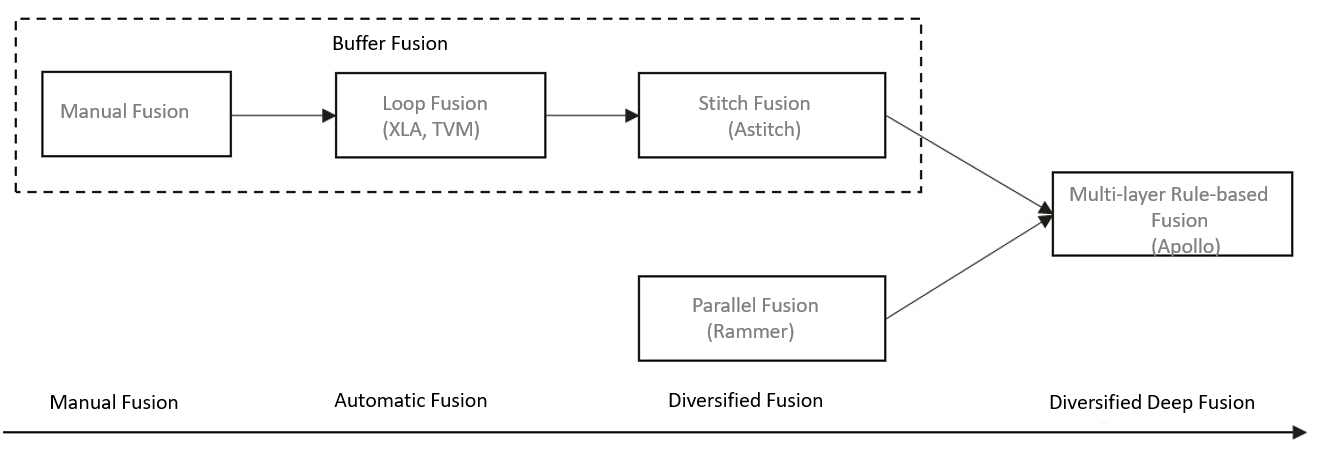
(Development of operator fusion)
Multi-layer Fusion Optimization
As shown in the figure, Apollo has an open architecture of multiple layers for different operator fusion modes. Operator fusion is implemented at each layer. After the layers are fused based on specific rules, the result is a fusion subgraph.
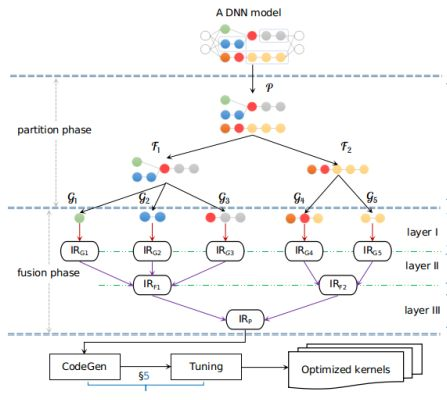
Prior to the fusion of hierarchical layers, the input computational graph is partitioned into micro-graphs. Each micro-graph serves as the basic unit for the operator schedule as well as the starting point for multi-layer fusion. In the Apollo architecture, fusion is done through three layers. Layer I uses the polyhedral automatic schedule technology to perform loop fusion and schedule optimization on each micro-graph. Layer II identifies the data-dependent operator intermediate representations (IRs) that can be stitched for fusion based on the IRs of fused operators. Layer III works with the IRs obtained at Layer II, identifying independent IRs and conducting parallel fusion based on parallel rules.
After the layer-by-layer fusion, the final IRs of fused operators are processed using the CodeGen tool to generate corresponding kernels for fused operators. Choosing proper IRs is very important during architecture design, as layer-by-layer fusion requires flexible merging and modification of IRs. For operators, the MindSpore team used Halide IR for AKG interconnection because of two reasons. First, Halide IR is compatible with AKG. Second, Halide IR is relatively mature and flexible, supporting various basic functions. For layer IR selection, we selected MindSpore IR (MindIR) instead of independent HLO IR similar to XLA due to the following advantages of MindIR:
(1) Reduces IR mapping and conversion from the MindSpore front-end framework to Apollo.
(2) Reduces code development (existing MindSpore infrastructure and common optimization policies are reused).
(3) Supports merging of subgraphs and the analysis of fusion policies at different layers in white-box mode.
Technical Effect and Typical Application
Apollo is now implemented in MindSpore and is used as the acceleration engine for graph kernel fusion, where it plays a key role in performance optimization across key networks. For example, in the Bert GPU network of MindSpore 1.3, Apollo accelerates performance by 3.1 to 3.6 times, surpassing XLA.
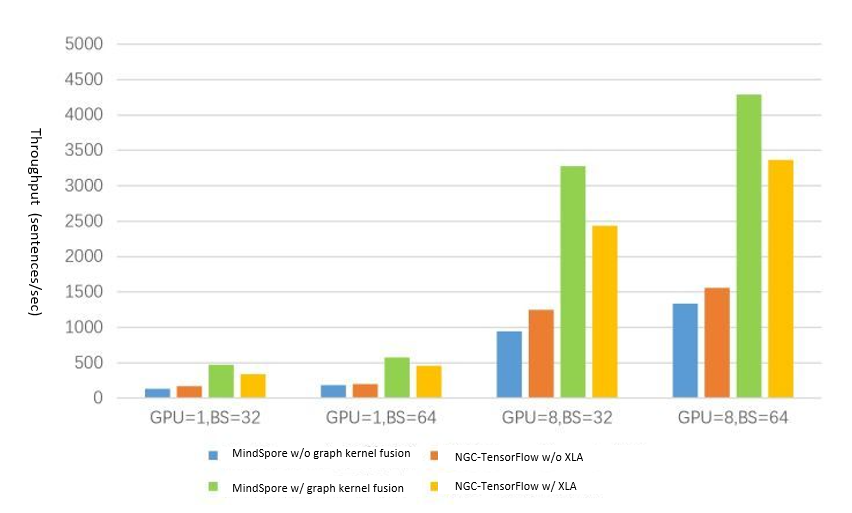
(Figure source: Advanced Data System Lab (ADSL), University of Science and Technology of China)
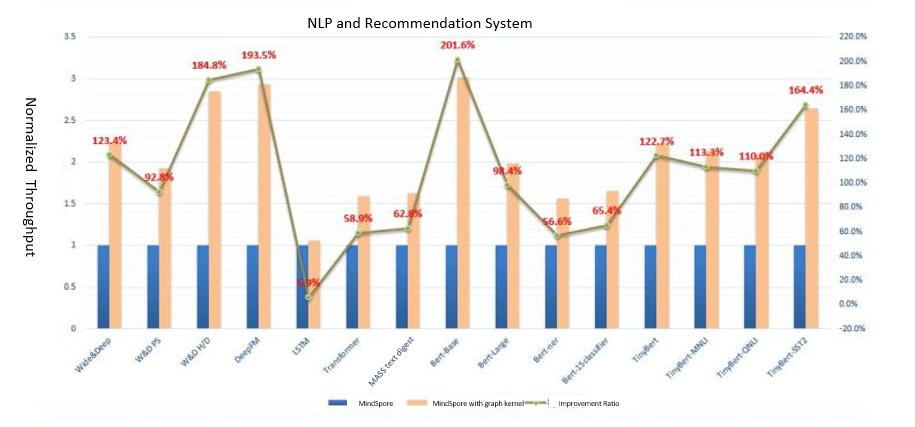
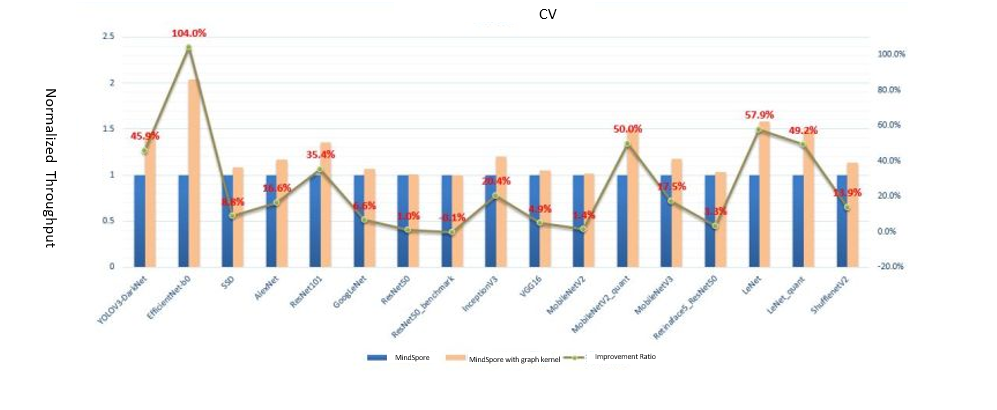
In the GNN network of MindSpore 1.6, on the other hand, Apollo increases performance by three to four times. It is worth mentioning that index-based operator fusion in irregular memory access is implemented based on the characteristics of the GNN network and Apollo multi-layer fusion architecture. Additionally, the unique execution pattern of GNN model tasks can be automatically identified for fusion and kernel-level optimization. Compared with other frameworks that optimize specified common operators, MindSpore is more scalable. It can cover all current operators in the framework and as well as new operator combinations. It is also without doubt that the Apollo framework has good scalability. We performed extensive verification on more than 50 networks. The average Apollo performance improved by 96.4% for NLP, 136.6% for recommendation systems, and 30.7% for CV.
Summary and Future
The rapid development of computing power, combined with Moore's Law restrictions, means that the memory and parallelism bottlenecks of AI processors will become more and more prominent. We designed Apollo to address these challenges. Apollo uses a multi-layer fusion architecture to combine different fusion modes, achieving significant fusion performance, as well as better scalability and elasticity.
As is the case with every new architecture, it can still use improvement. We hope to hear your suggestions. If you are interested in operator fusion, please contact us. Last, but not least, we are truly grateful to Mr. Dan Xiaoqiang, who was of great help to this project.
References
[1] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. TVM: An automated end-to-end optimizing compiler for deep learning. OSDI'18.
[2] Zhen Zheng, Xuanda Yang Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, et al. AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures. ASPLOS 2022.
[3] Lingxiao Ma, Zhiqiang Xie et al. Rammer: Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks. OSDI 2020.
[4] Jie Zhao, Bojie Li, et al. 2021. AKG: Automatic Kernel Generation for Neural Processing Units using Polyhedral Transformations. PLDI 2021.
[5] Jie Zhao, Peng Di. 2020. Optimizing the Memory Hierarchy by Compositing Automatic Transformations on Computations and Data. MICRO-53.
[6] Graph Kernel Fusion on the MindSpore official website