[CSD] Super-Resolution Model Compression and Acceleration via Contrastive Self-Distillation
CSD Super-Resolution Model Compression and Acceleration via Contrastive Self-Distillation
1. Background
Image super-resolution (SR) refers to the task of enhancing the resolution of a given image to enrich the details and textures. SR can significantly improve the performance of downstream high-level computer vision tasks such as vehicle detection and scene understanding. It is a frontier topic of common concern in the image processing and computer vision domains.
However, most existing image SR methods focus on constructing complex network structures. Such models do not work well on lightweight devices because of the high computational cost required for calculating the large number of parameters.
Research Direction
In this paper, the team designs a universal framework for SR model compression and acceleration via contrastive self-distillation (CSD).
2. Team Introduction
The team was led by Professor Xie Yuan, winner of the Wu Wenjun Artificial Intelligence Science and Technology Award and Shanghai Science and Technology Advancement Special Award.
3. Paper Abstract
In this paper, the team proposes a framework for SR model compression and acceleration via CSD.
In a self-distillation framework, the student network and teacher network share some parameters to implement implicit knowledge distillation, which provides the basis for dynamic loading. Different from the situation with classification tasks, the student network cannot be constrained effectively during simple implicit knowledge distillation.
Therefore, this paper introduces a contrastive loss function to explicitly constrain the relationship between the student network and teacher network, and selects multiple negative samples as the lower bounds to reduce the optimization space.
The correctness and effectiveness of the framework are verified through a large number of detailed experiments. With a similar computation amount, models trained by using the proposed framework yield higher performance. The proposed framework can also be applied to various existing SR models, so that state-of-the-art methods can be deployed to lightweight devices.
4. Related Links
Paper: https://arxiv.org/abs/2105.11683
Code implementation based on MindSpore: https://gitee.com/mindspore/models/tree/master/research/cv/csd
5. Technical Highlights of the Algorithm Framework
The algorithm framework consists of two parts, the teacher-student network based on the self-distillation framework, and the contrastive loss function.
The student-teacher network includes the shallow feature extraction module, deep feature extraction module and upsampler module. The student network and teacher network share some channels at each layer, which are controlled by the width scale.
In addition to the traditional reconstruction loss, the output of student network (the anchor), the output of teacher network (the positive samples), and the bicubic interpolated image (the negative samples) are input to the pre-trained VGG network for contrastive loss calculation.
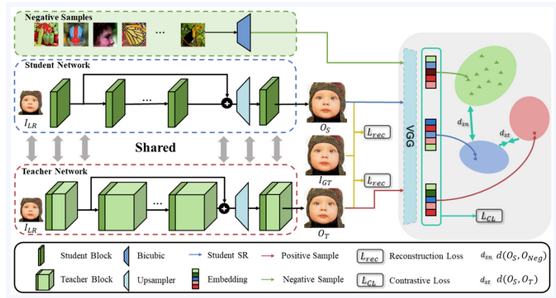
Figure 1: Framework of the proposed CSD framework.
6. Test Results
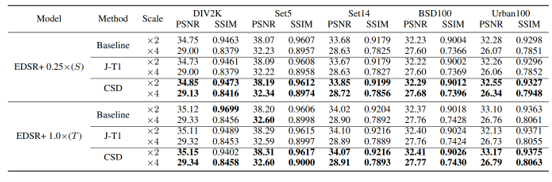
Figure 2: Performance comparison of the EDSR+ models compressed using different methods.
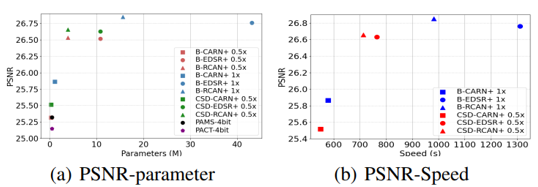
Figure 3: Results of different models compressed using the proposed CSD framework.

Figure 4: Qualitative (visual) comparison
7. Code implementation based on MindSpore
Key modules include the data loading module, network structure (the EDSR model is used as an example), loss functions, and trainer.
(1) Data loading module:
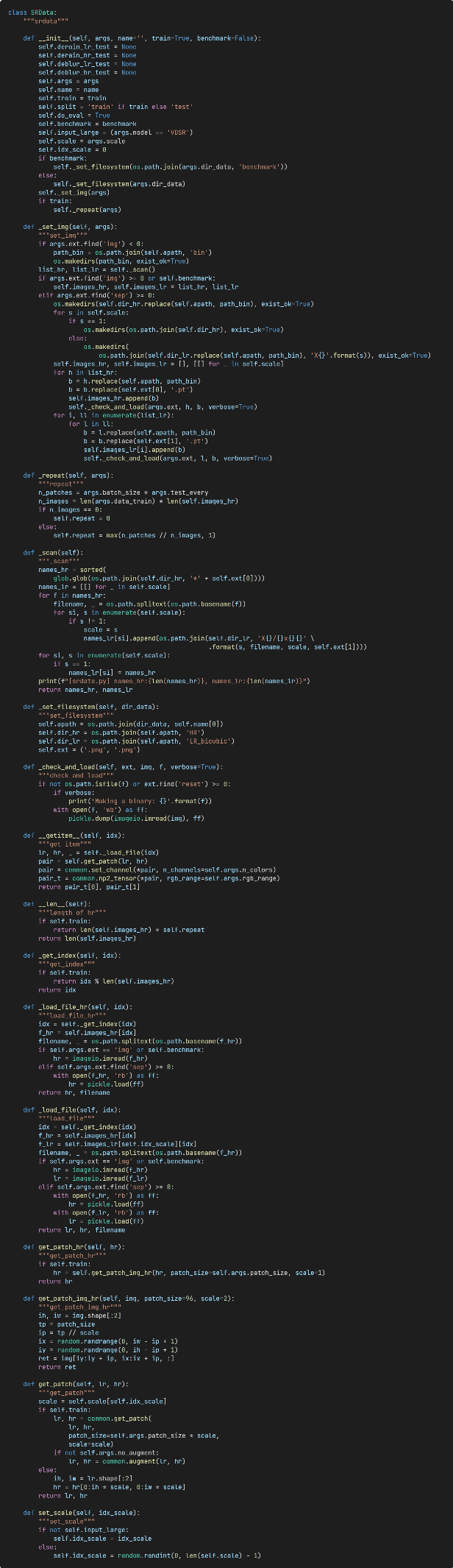
Figure 5: The dataset class.
(2) Network structure:
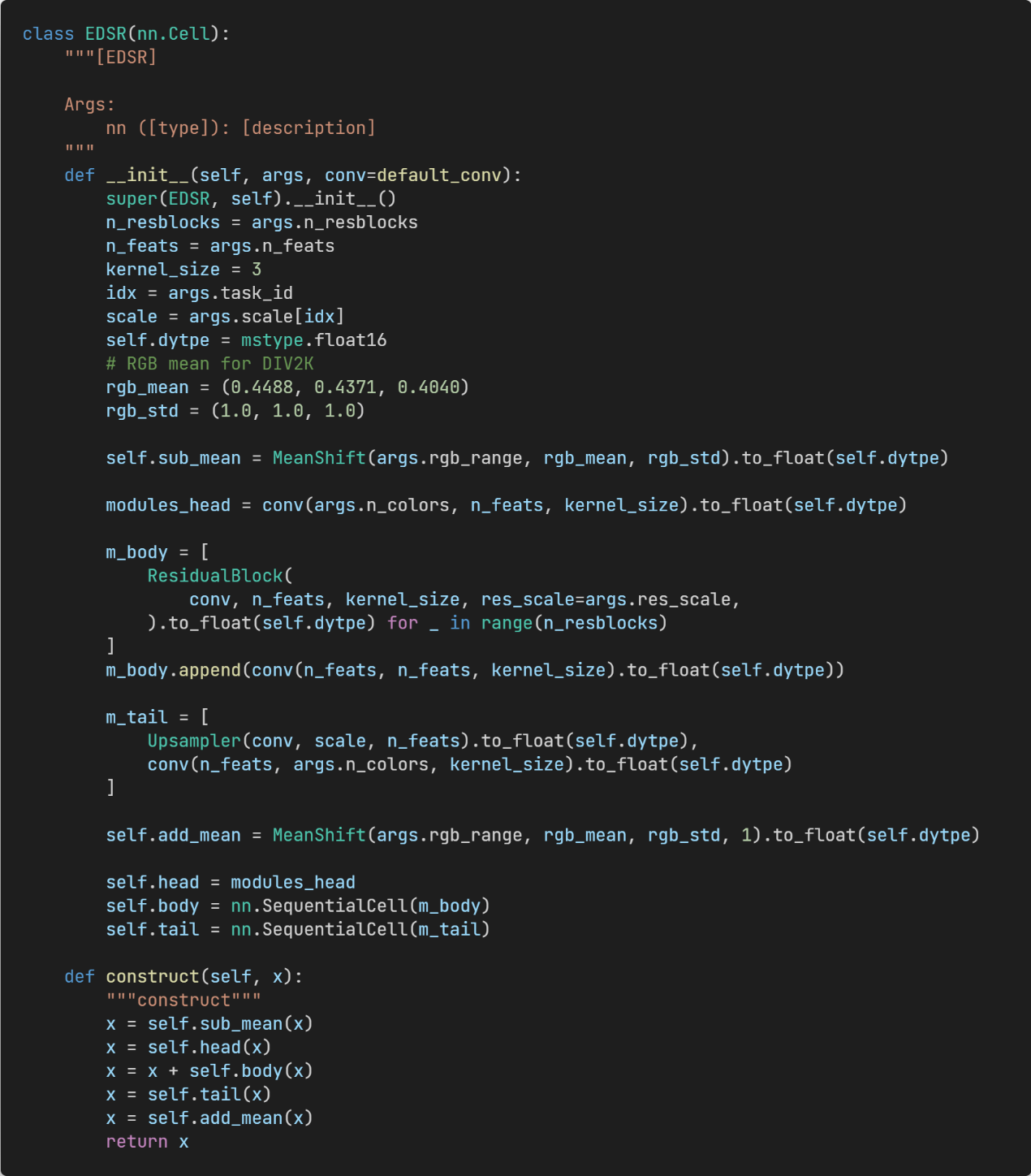
Figure 6: EDSR model with an adjustable width.
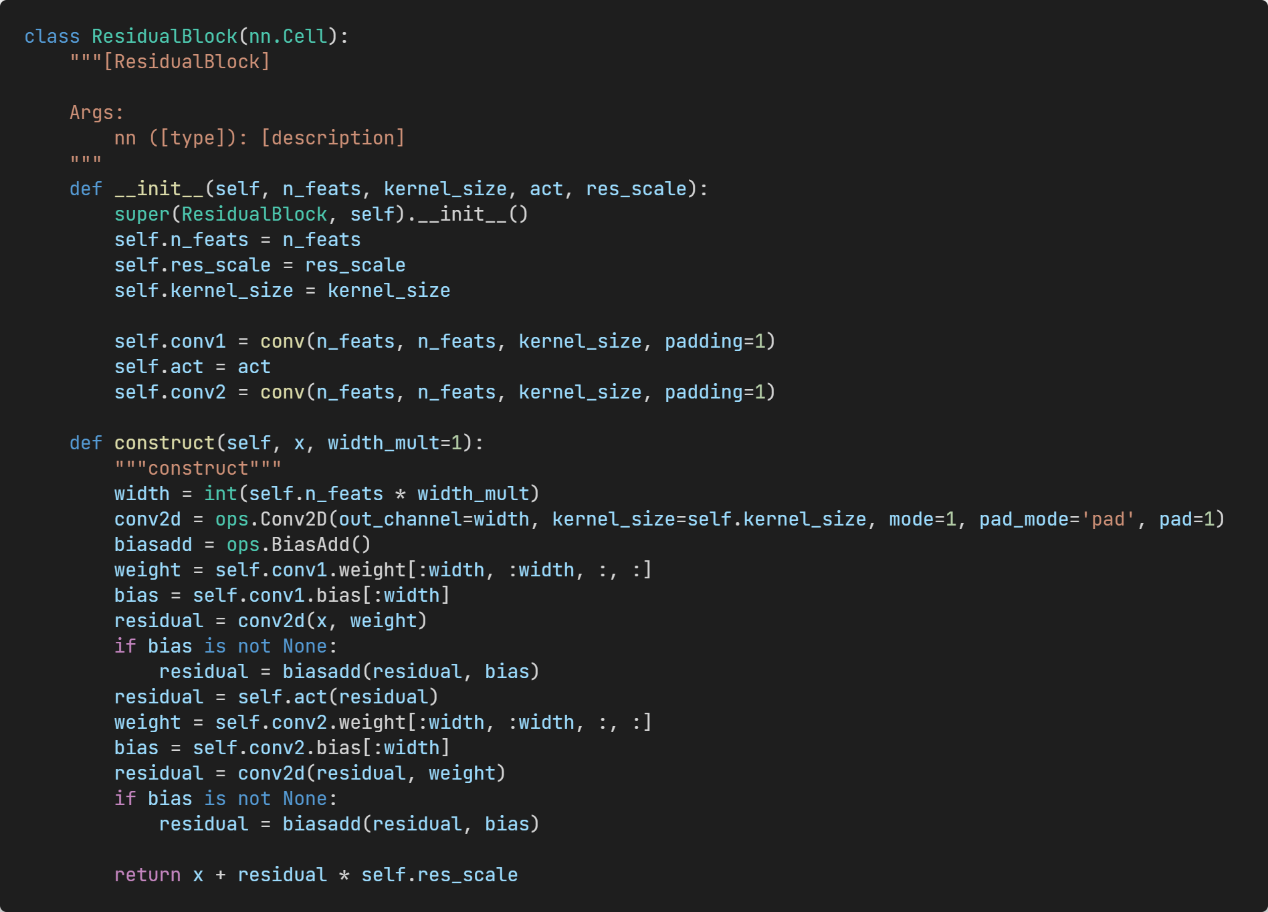
Figure 7: Residual block with an adjustable width.
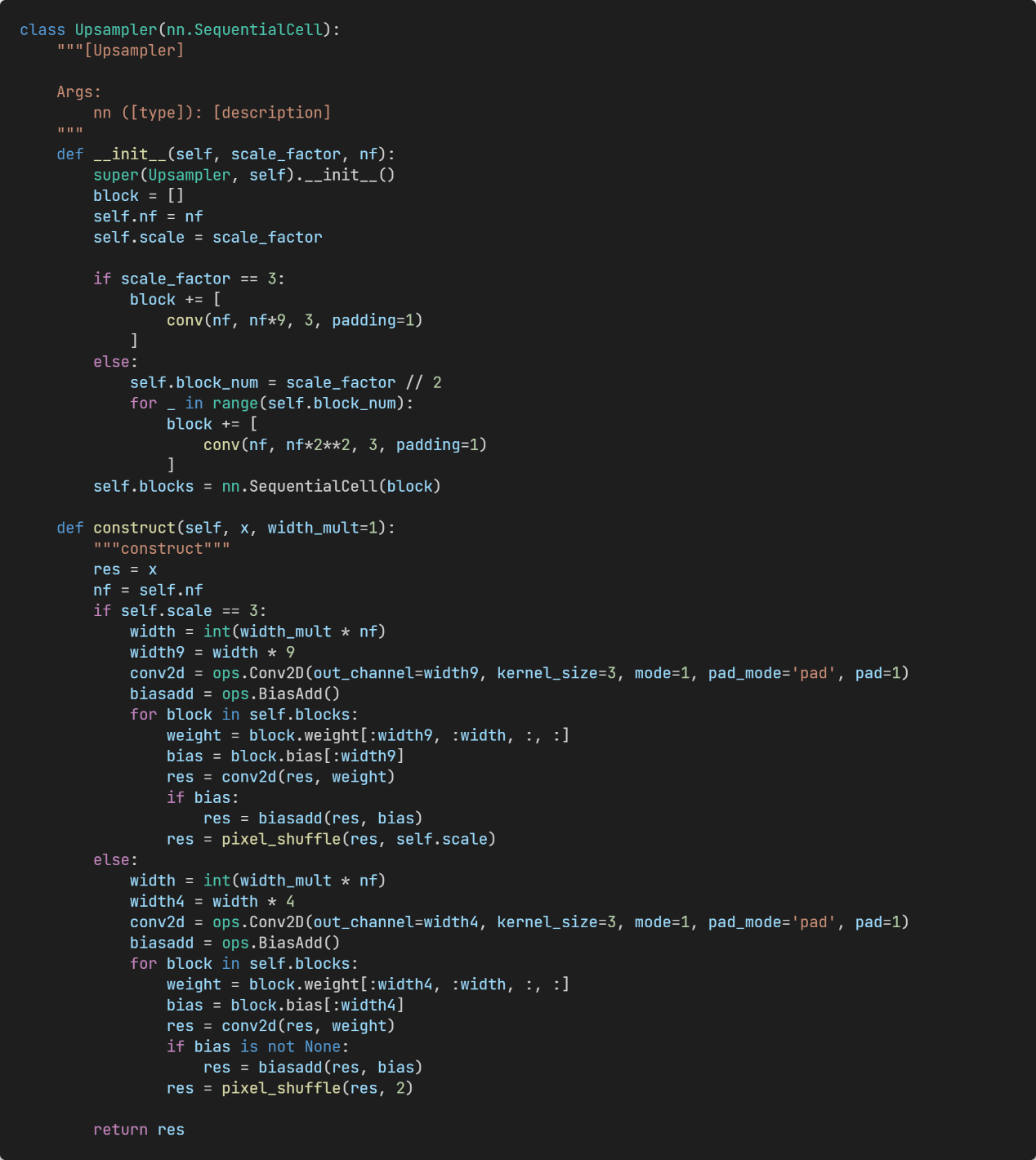
Figure 8: Upsampling block with an adjustable width.
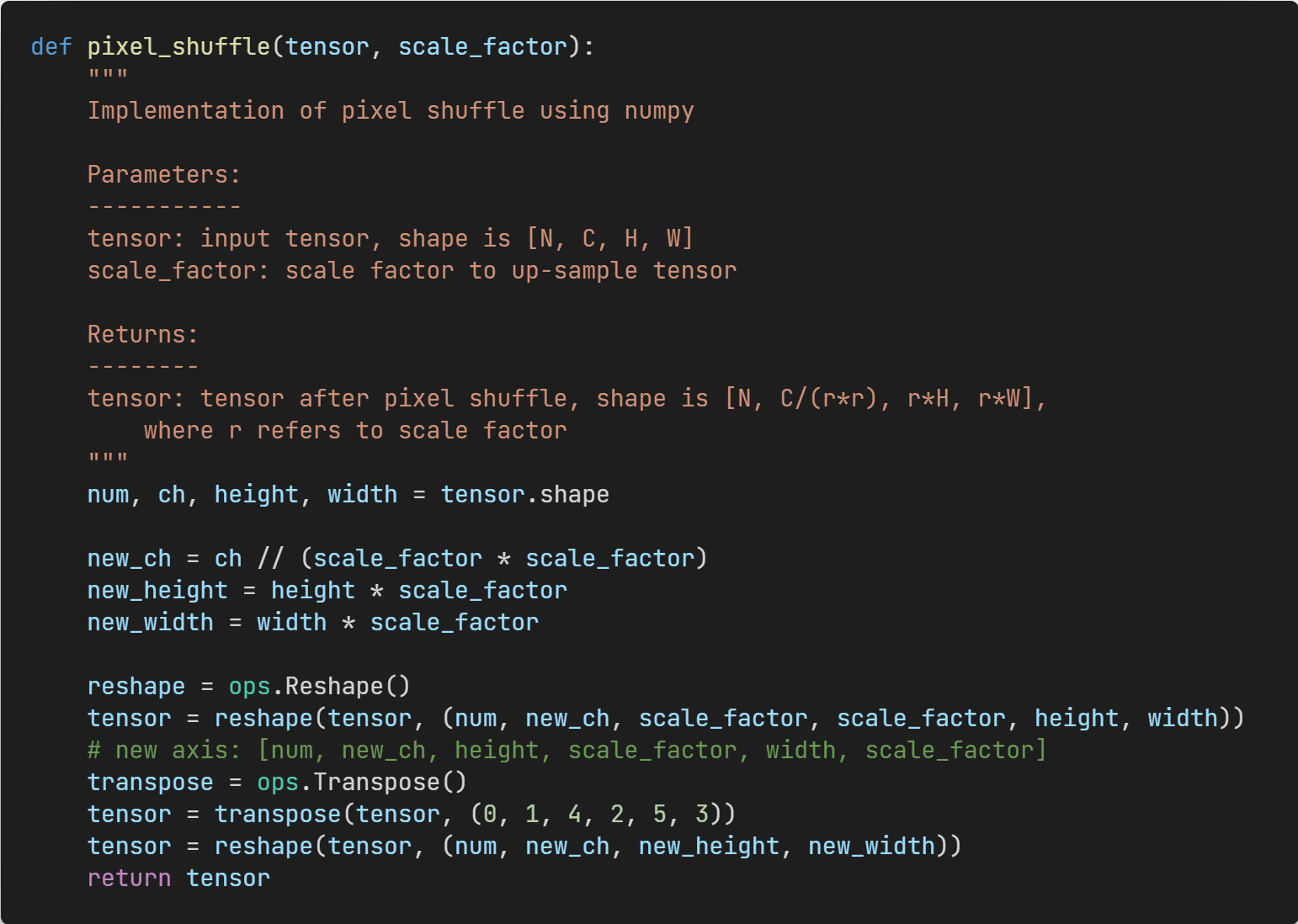
Figure 9: Pixel-shuffle operation.
(3) Loss functions:
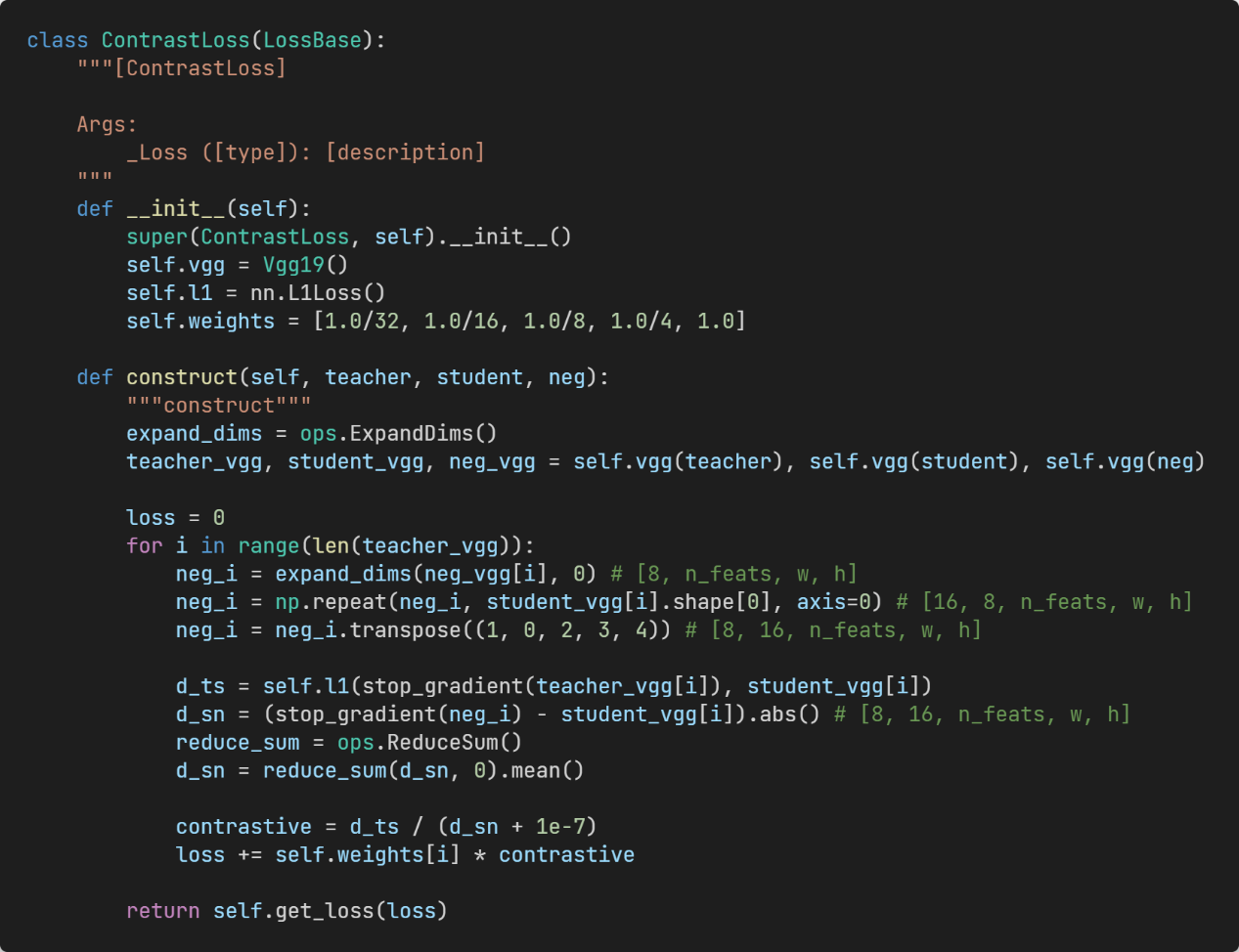
Figure 10: Contrastive loss.
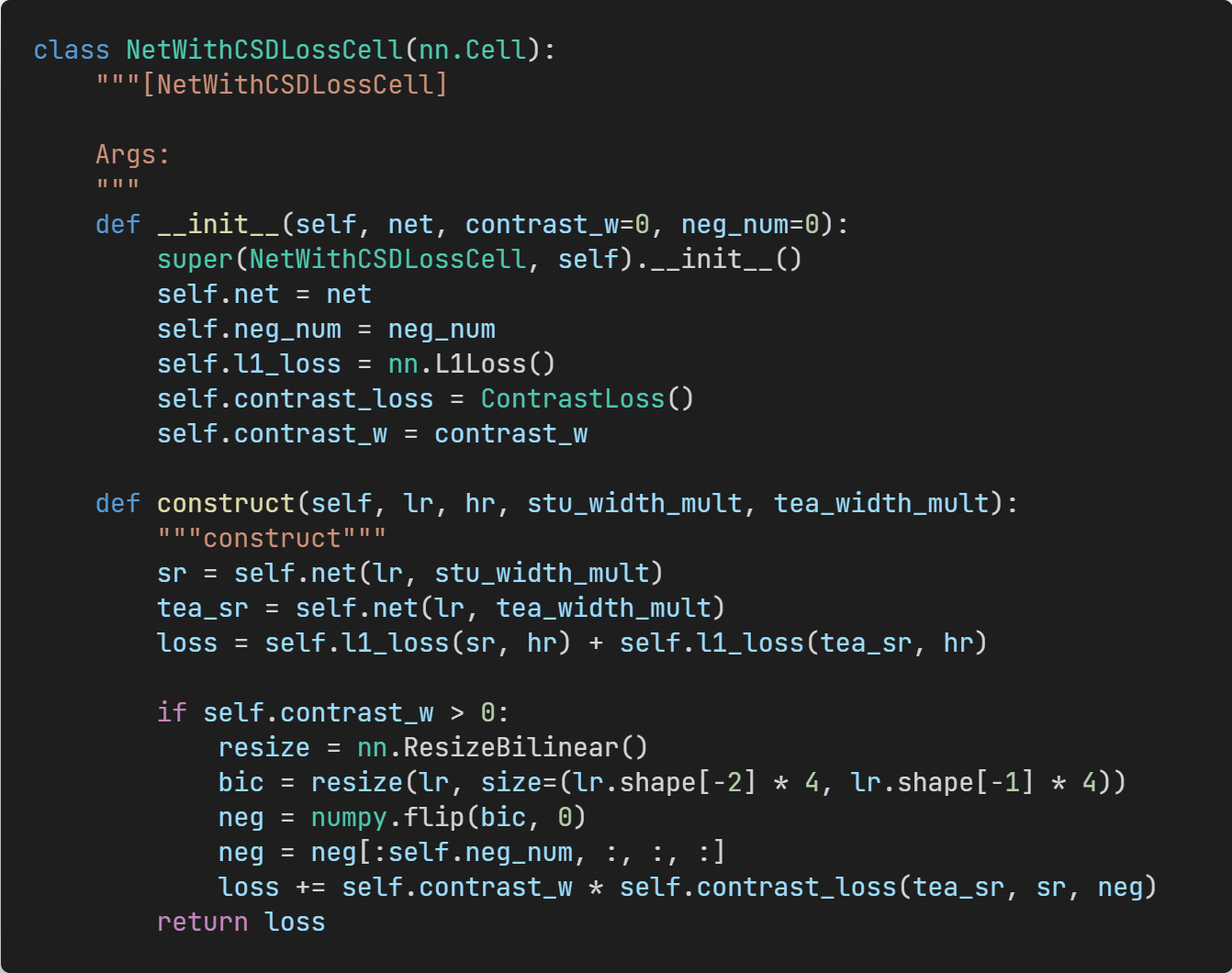
Figure 11: Complete loss function.
(4) Trainer:
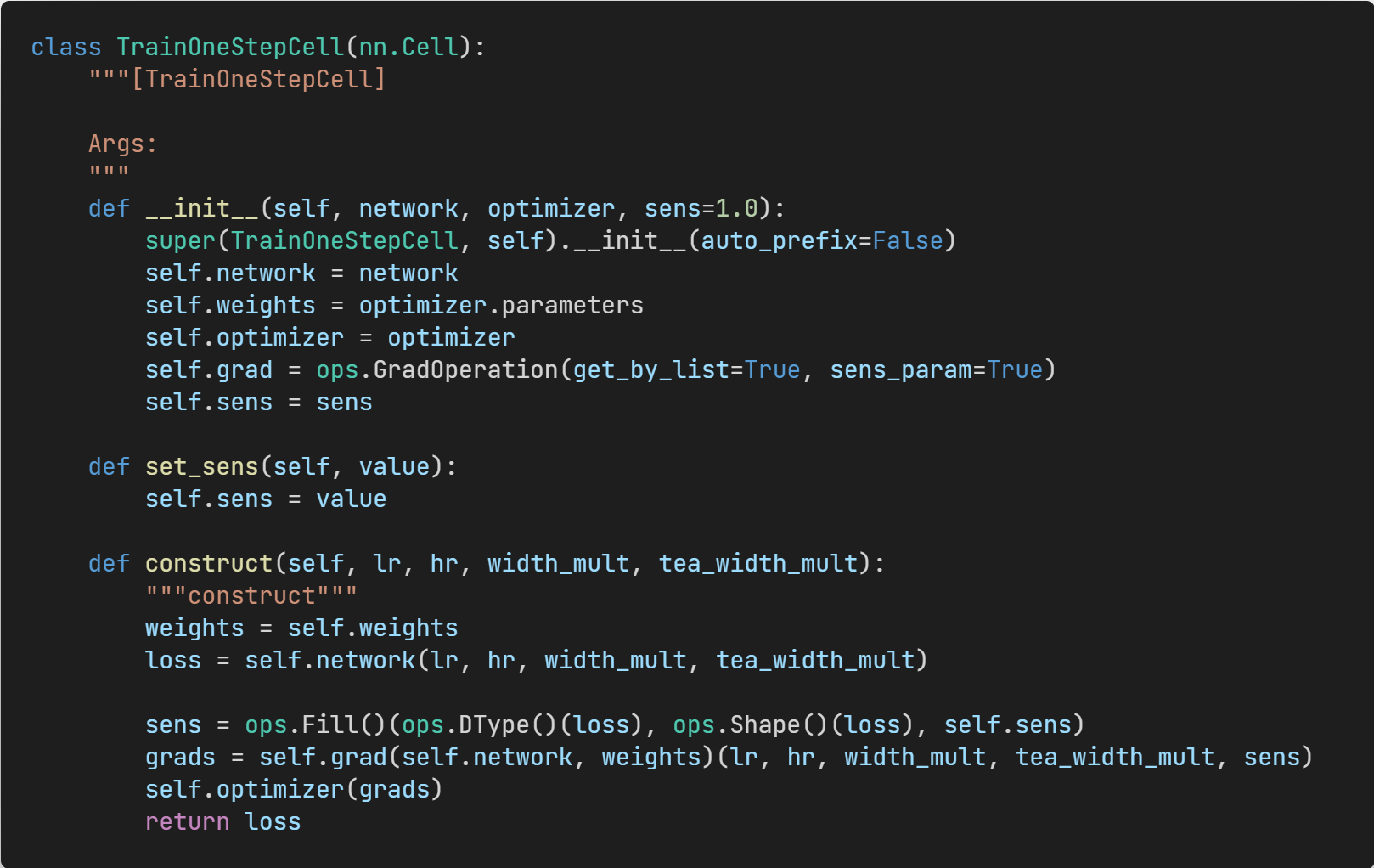
Figure 12: Single-step training process.
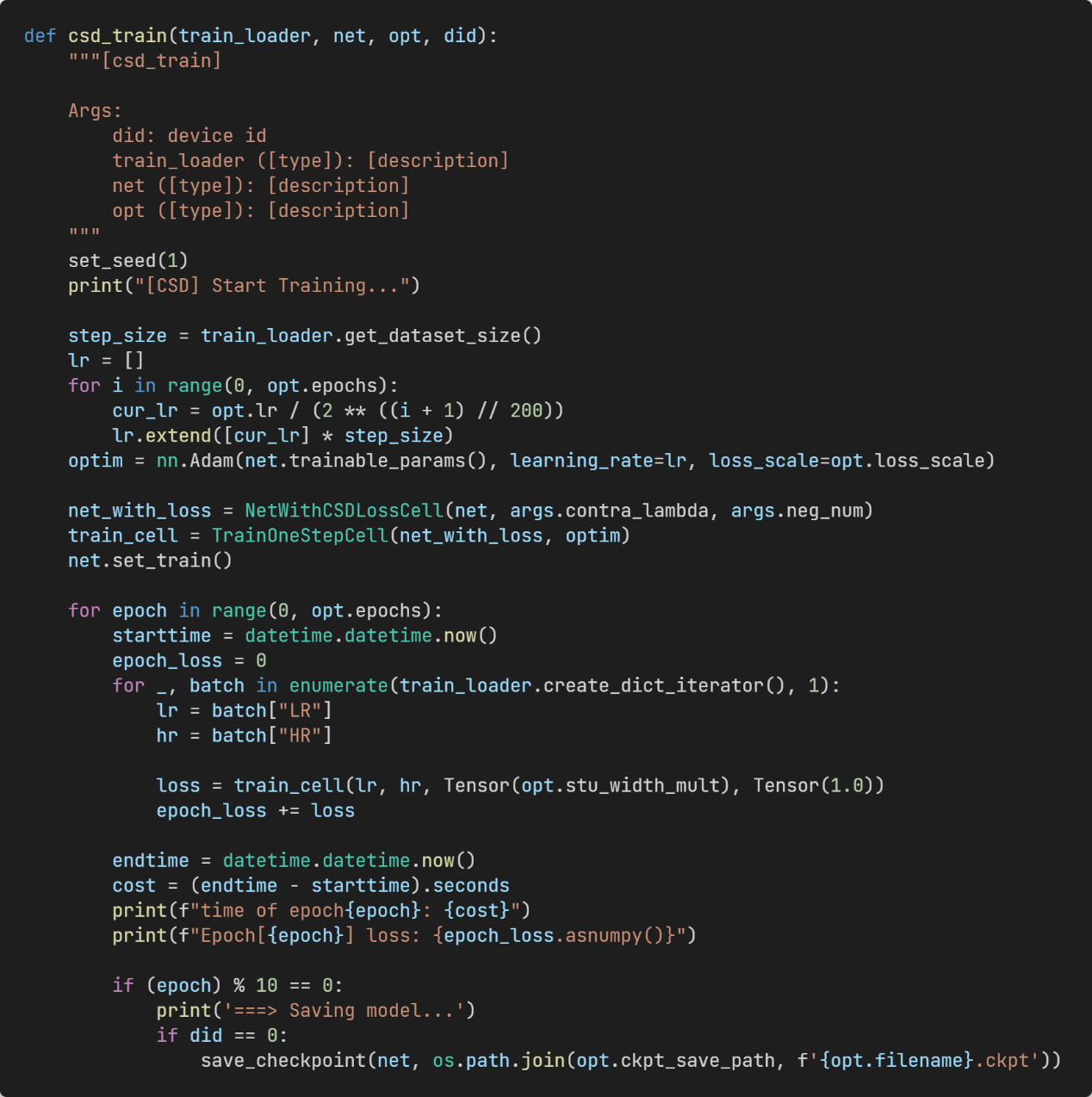
Figure 13: Complete training process.
8. Conclusion
In this paper, the team designs a universal framework for SR model compression and acceleration via contrastive self-distillation (CSD), facilitating dynamic resource adjustment based on actual computing resources. At the same time, positive and negative samples are introduced to effectively restrict the perception space, so that the knowledge is explicitly transferred from the teacher network to the student network.
The proposed framework for simultaneous compression and acceleration can be applied to most SR models. The team believes that the proposed CSD framework can be generalized to other low-level vision tasks (for example, image restoration), which will be explored in future work.

MindSpore website: https://www.mindspore.cn/en
MindSpore Repositories