The Relationship Between PaLM and Pathways
The Relationship Between PaLM and Pathways
April 13, 2022
Author: Jin Xuefeng
PaLM, the AI architecture, is typically trained using Pathways. Recently, I spent time studying the benefits of using Pathways to train PaLM, but discovered that, pardon my ignorance, there are no benefits. Let me explain.
First, let's have a look at the whole picture.
Last year, the computer scientist and Google Senior Fellow, Jeff Dean introduced Pathways as "a new AI architecture multi-tasking, multi-modal, and more efficient".
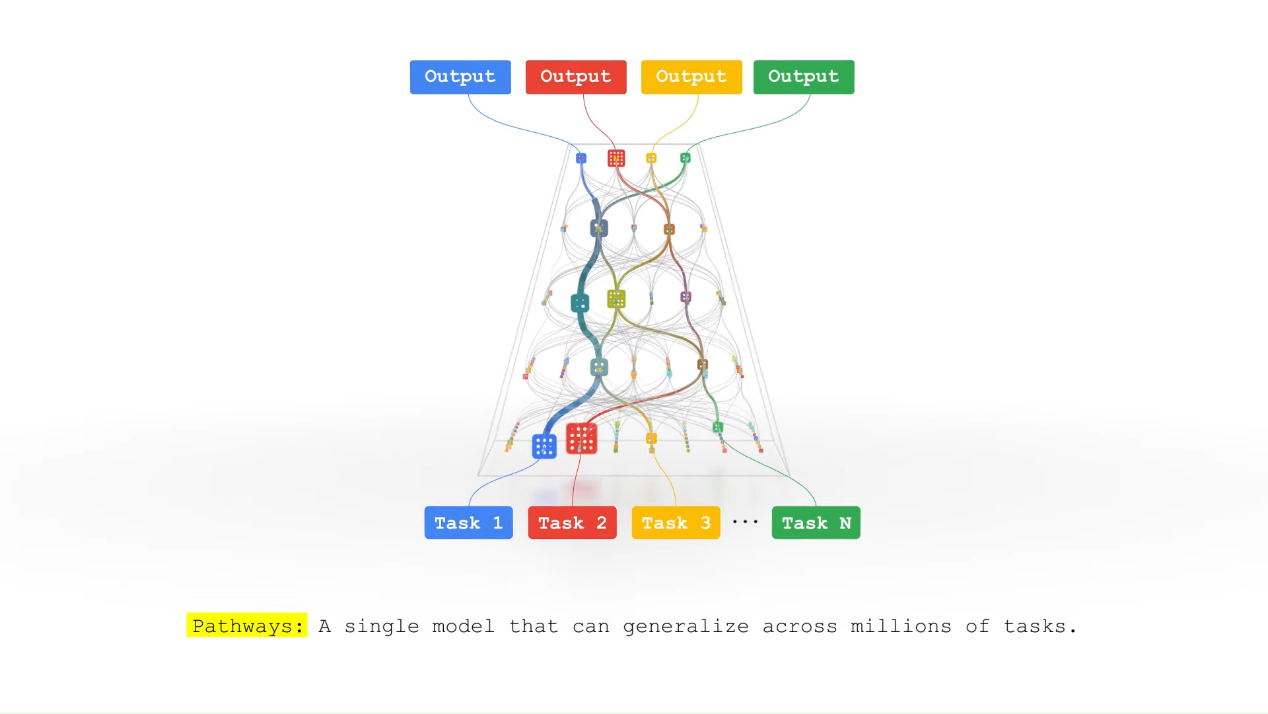
His vision aims to unify processes and tasks into a single model: multi-task/multi-modal capabilities with multiple inputs/outputs, weight sharing, asynchronization, and sparse activation.
Recently, Google published a paper that presents the Pathways system architecture, and the multiple program multiple data (MPMD) programming and scheduling that combines Single- and Multiple-Controller approaches, to provide multi-tenant, flexible graph sharding, and dynamic resource scheduling.
Furthermore, Google released the PaLM model trained using Pathways.
Introduction of PaLM
The AI model Pathways Language Model, or PaLM, differs from the Pathways model promoted by Jeff Dean last year. It is still a single program multiple data (SPMD) model that doesn't include the sparse activation, dynamic routes, and multi-task/multi-modal capabilities.
An Improved GPT3 Structure
PaLM adopts a dense, decoder-only structure similar to GPT3 with 8B, 62B, and 540B variants. This model has the following modifications to the standard Transformer model architecture:
Ÿ SwiGLU activations: These activation functions require larger calculation amount but significantly increase quality compared to standard ReLU, GeLU, or Swish activations.
Ÿ Parallel Layers: This model uses a parallelized standard formulation written as y = x + MLP(LayerNorm(x + Attention(LayerNorm(x)))->y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x)) to fuse the MLP and Attention input matrix multiplications. The parallel formulation results in 15% faster training speed with a small quality degradation.
Ÿ Multi-Query Attention: The standard Transformer formulation is modified to project the key and value to a single-headed tensor while the query to a multi-headed tensor. This approach reduces the calculation workload of the Attention part by approximately two-thirds.
Ÿ RoPE Embeddings: The rotary positional embedding (RePE) encoding is used, which has shown better performance on long sequences.
Ÿ No biases or dropout: More large models are beginning to adopt this approach.
Ÿ Adafactor optimizer: This optimizer slightly affects the accuracy, but reduces the number of optimizer statuses and saves memory.
The overall performance is quite impressive according to the results shown in the paper.
Training Setup
Parallel training: Each TPUv4 pod uses 12-way model parallelism and 256-way fully sharded data parallelism. Data is paralleled between two pods, and is recomputed at each layer. The overall throughput is high without pipeline parallelism due to the high throughput of the bandwidth within the pods.
Cluster scale: Two TPUv4 pods are used to implement model training based on Pathways. Each pod has 3,072 chips attached to 768 hosts. The system has a total of 6,144 chips.
How Does PaLM Benefit from Pathways?
Using Pathways to perform cross-pod training isn't worthwhile because only data parallelism is performed across pods. In this case, the traditional SPMD approach is better.
Intra-pod operator-level model parallelism and inter-pod data parallelism exclusively occupy resources, impacting the effectiveness of Pathways. Although Pathways is used for communication between pods, I think its architecture is not conducive to communication performance.
The author also mentions the concepts of hardware FLOPS utilization (HFU) and model FLOPS utilization (MFU):
Ÿ HFU: Actual FLOPS/theoretical peak FLOPS
Ÿ MFU: Actual throughput/theoretical maximum throughput of a system operating at peak FLOPS
The author recognizes that HFU is not a consistent and meaningful metric for training efficiency because rematerialization, which is a technique widely used to trade off memory usage with compute, generates more compute workload but reduces throughput. Since the ultimate goal of a training system is to achieve a high throughput (achieve the fastest training time), MFU is proposed. For example, the HFU of Megatron-Turing NLG is 50%, while the MFU is only 30.2%.
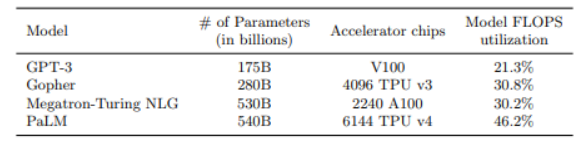
It remains unknown whether the MFU improvement of PaLM is the result of the Pathways architecture or the algorithm improvement of the model itself (see figure).
Conclusion
In my opinion, defining PaLM as a Pathways Language Model is inaccurate, because the advantages of the Pathways architecture are not observed in PaLM. Pathways should be used in large models with pipeline and subgraph parallelism, preferably in multiple large models on multiple pods.

MindSpore website: https://www.mindspore.cn/en
MindSpore Repositories