DCPUE Network Performance Optimization – CPU Training
DCPUE Network Performance Optimization – CPU Training
Problem Description
1. Training conditions:
Linux Euler OS x86;
8 graphics cards;
Physical CPU: 2;
Number of cores in each physical CPU: 26;
Logical CPU: 104;
MindSpore 1.2.0
TensorFlow 1.15.0
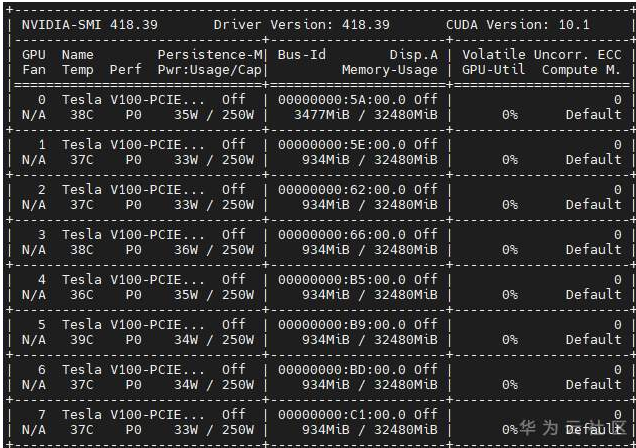
2. CPU training duration
MindSpore (without core binding): 33 minutes
TensorFlow (without core binding): 1 hour 6 minutes
MindSpore (bound to a logical CPU): around 3 hours
TensorFlow (bound to a logical CPU): 1 hour 47 minutes
3. Optimization purpose
To achieve a training duration on MindSpore that is less than or equal to that on TensorFlow under the same conditions.
Cause Analysis
Typically, if one logical CPU is bound to MindSpore, training is very slow. Even worse, if no cores are bound, the training on MindSpore requires the use of 56 logical CPUs.
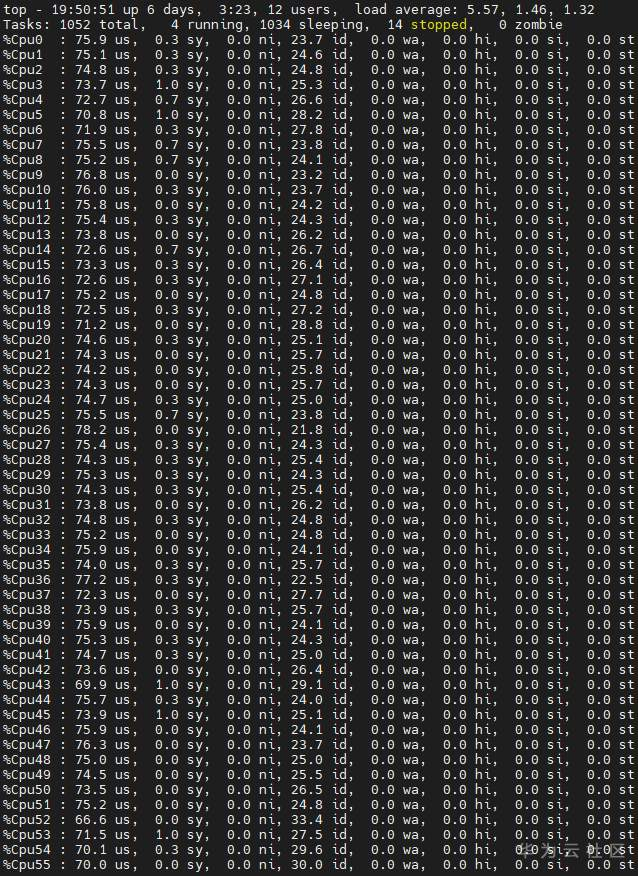
To find out the reason for the slow training, we first used MindInsight – MindSpore's network analysis tool – to view the execution time of specific operators, then used TensorFlow to train the neural network, and finally used the TensorFlow profiler to analyze the execution information of the five operators that consumed the most time. The results show that the operators on TensorFlow took microseconds to execute, whereas the operators on MindSpore took seconds to execute. It is obviously anomalous that the MindSpore training speed is millions of times slower than TensorFlow.
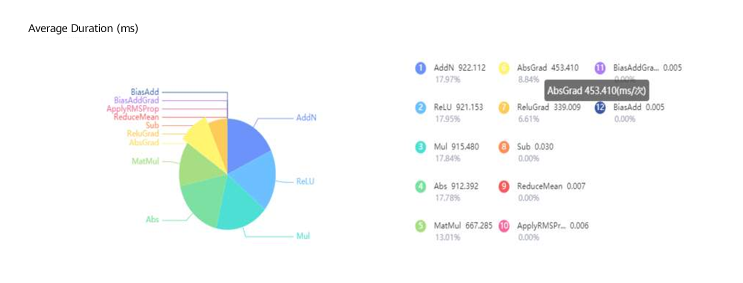

After checking the source code of the top five MindSpore operators that consumed the most time (AddN, Relu, Mul, MatMul, and Abs), we found that they were implemented through the third-party library Math Kernel Library for Deep Neural Networks (MKL-DNN), which was released by Intel a few years ago to optimize the performance of some common operators for deep learning on CPUs. We hypothesized that this library was being used incorrectly, so we looked up some references and found that the following environment variable needs to be set when this library is being used.
export OMP_NUM_THREADS = num physical cores
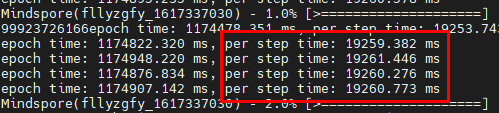
To test the performance of the neural network, we set the value of the environment variable to 1. (Generally, a physical CPU contains N logical CPUs, so theoretically the environment variable should be set to 1/N. However, the neural network is bound to one logical CPU, so the value is rounded up to 1.) The results of the test were that the total execution time was reduced from 3 hours to around 3 minutes 13 seconds, and per step time was reduced from 19260 milliseconds to around 6 milliseconds.
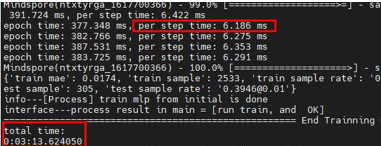
From the following figure, we can see that the performance of the five operators is greatly improved. With the exception of MatMul, the performances of AddN, Relu, Abs, and Mul are the same as those on TensorFlow.
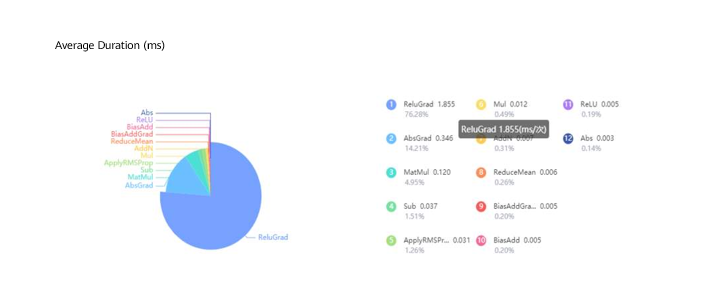
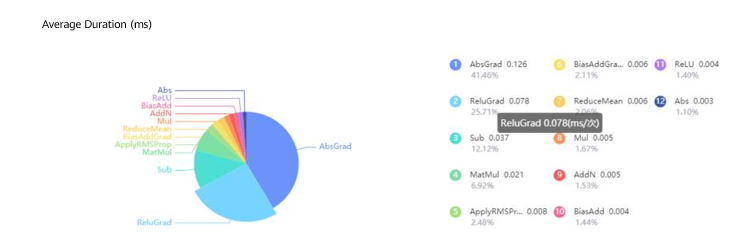
Even though the CPU training duration of the neural network on MindSpore was now reduced by 99.97%, it still lagged far behind TensorFlow, which only requires 1 minute and 47 seconds to complete, due to the fact that even though MKL-DNN had been optimized, ReluGrad (backward Relu operator) still now accounted for 76% of the total training time. After reviewing the source code of this operator, we found that it triggered the maximum number of threads instead of using a unified thread pool when it implemented multiple threads. This wastes CPU resources, causes thread competition, and adds extra overheads for starting and destroying threads.
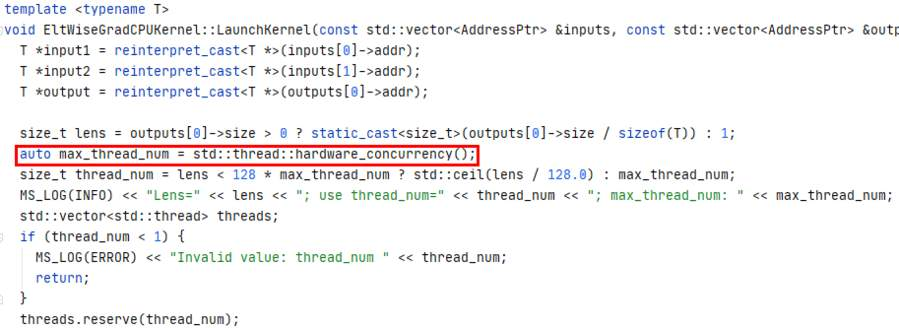
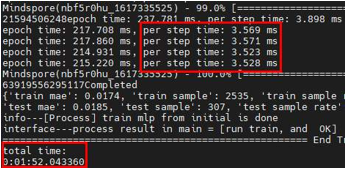
All the aforementioned problems considerably increase the CPU load and reduce the performance of the neural network. To resolve these problems, we reconstructed the code, used a unified thread pool to manage threads, and deleted redundant operations before testing the performance of the neural network again. The figures below show that the total training duration was reduced from 3 minutes and 13 seconds to 1 minute and 52 seconds, and the single-step execution time was reduced from around 6 milliseconds to around 3.5 milliseconds. In addition, all operators on MindSpore were executed in just microseconds, reaching a similar performance to that on TensorFlow.
References
Accelerating Deep Learning on CPU with Intel MKL-DNN
Maximize TensorFlow* Performance on CPU: Considerations and Recommendations for Inference Workloads