Idea Sharing (36): MPI Advanced Features and Scientific Computing Cases
Idea Sharing (36): MPI Advanced Features and Scientific Computing Cases
I. Basics About MPI
Message Passing Interface (MPI) is a standard specification for message passing function libraries. It is developed by the MPI forum, and is one of the most commonly used key parallel distributed interfaces for scientific and high-performance computing. MPI belongs to the fifth layer or higher of the Open System Interconnection (OSI) reference model. Generally, the bottom layer is implemented through Sockets or Transmission Control Protocol (TCP) at the transport layer.
MPI 1.0 was proposed in 1994, which introduced the basic concept of message passing. It then evolved to version 2.0 in 1997, with features such as one-sided communication and parallel I/O added, defining the fundamental MPI functionality. Starting from version 3.0, numerous interfaces were gradually added to enhance performance and expand application scenarios, including non-blocking collective communication, neighborhood collective communication, shared memory extension, MPI_T interface extension, and more. The recent releases of version 4.0 and 4.1 further enhance the features, such as hybrid programming model extension, fault tolerance, persistent collections, performance assertions and hints, RMA/one-sided communication, and more, making it capable of supporting large-scale distributed super applications.
II. Implementation Editions and Main Features
Popular MPI implementation editions include MPICH, Open MPI, and MVAPICH. In addition, various vendors also develop their own editions with specific optimizations based on their own chips or systems, such as Intel, IBM, Microsoft, etc. The currently mature MPI 3.1 has support and implementations from multiple vendors, while MPI 4.0 is currently well-supported mainly by MPICH and Open MPI, with main features covered.

Figure 1 Overview of MPI 3.1 software implementation
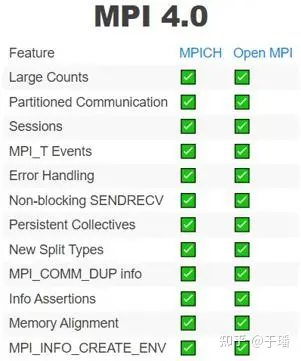
Figure 2 Overview of MPI 4.0 software implementation
III. MPI Advanced Features
(1) Memory sharing: MPI 1 and MPI 2 do not support direct memory sharing, and can read or update only through message passing. In essence, the memory space between processes is not shared, so it cannot be loaded and stored in the conventional way. The explicit message passing and remote memory access operations require additional memory copying, which reduces memory performance and increases memory consumption. Starting from MPI 3, part of the memory space of the memory sharing window is exposed to other processes. This portable memory sharing mechanism allows for regular MPI and memory sharing operations in a unified programming mode, avoiding the issues associated with external memory sharing programming models.
(2) Hybrid programming: To cope with the hybrid architectures of a large number of CPUs, CPU cores, GPUs, and other acceleration hardware, MPI introduced the hybrid programming feature from version 3.0, enabling better handling of node and data parallel programming models. One common method is MPI + OpenMP that allows for node-level and thread-level hybrid parallelism. Additionally, mixing MPI with pthreads is also commonly used. MPI also provides a secure thread programming interface, MPI_Thread_init, to support MPI_THREAD_SINGLE (single-thread scenario), MPI_THREAD_FUNNELLED (cycling scenario), and MPI_THREAD_MULTIPLE (complete multi-thread scenario).
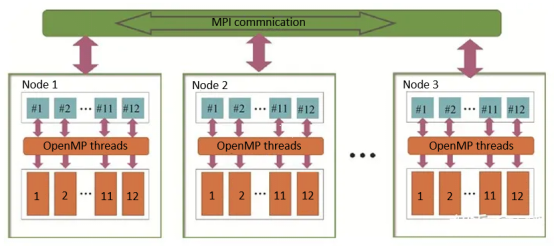
Figure 3 MPI + OpenMP hybrid programming model
(3) Fault tolerance: This is a key feature introduced in MPI 4, which mainly provides portable application fault tolerance and fast recovery mechanisms. In each iteration, status data of MPIs and applications is recorded as checkpoints. If a failure occurs, data can be restored from the latest checkpoint.
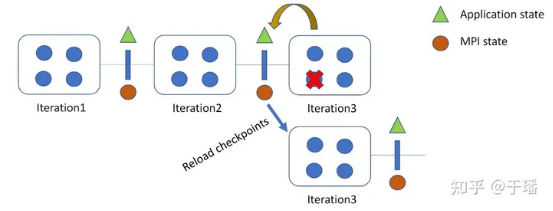
Figure 4 Fault tolerance mechanism of MPI 4
(4) RMA/One-sided communication: One-sided communication decouples data exchange from synchronization, so that remote processes do not need to synchronize data during data exchange. This makes it easier to implement irregular communication patterns without the need for additional steps to determine the number of Send/Recv operations required. If the system hardware supports Remote Memory Access (RMA), better performance can be achieved compared to Send/Recv. The one-sided communication feature was introduced in MPI 3 and further optimized and enhanced in MPI 4.

Figure 5 Two-sided communication vs. One-sided communication
IV. MPI Cases in Scientific Computing
(1) Meteorological Simulation
In weather simulation, the atmosphere can be regarded as a three-dimensional sphere. To simulate it, it is necessary to compute the temperature, humidity, wind speed, precipitation, and atmospheric pressure at each grid point around the world. By using MPI, the global grid points can be divided into several sub-regions, which are then assigned to different compute nodes for parallel computation and simulation. Due to the mutual influence of grid boundaries in the simulation process, it is necessary to exchange information within a certain range of boundaries at each simulation time step. Using MPI for parallel computation and data communication can accelerate weather simulation and achieve higher forecast accuracy and efficiency. However, based on practice, the basic MPI operations are not enough to achieve high performance in the simulation system. For example, imbalances often occur between communication orthogonality and appropriate cache utilization, which requires researchers to design proper process allocation strategies. For scenarios with large amounts of boundary data in simulation, techniques such as one-sided asynchronous communication and RMA memory sharing are needed to mask the computation and communication from each other.
(2) Molecular Dynamics Simulation
By simulating the motions of molecular systems, molecular dynamics not only allows for the determination of atomic trajectories and observation of various microscopic details in atomic motions, but also enables the extraction of samples from different system configurations for further computation of thermodynamic properties and other macroscopic characteristics. The accuracy of molecular dynamics simulation depends on the interactions of atoms, including their interactions with the environment and other atoms within the system. These interactions can be described using quantum mechanical theories, or be calculated using empirical methods or the recently popular AI4Sci approach, which utilizes neural networks for inference. Depending on the level of approximation for the interactions, the research scope can range from a few atoms to several thousand, tens of thousands, or even billions of atoms.
For a large-scale molecular simulation, it is common to divide the system into several grid regions based on geometric space and assume that the forces acting on each grid region are only influenced by the current region and its neighborhood. This allows the computation of the complex system to be decomposed into different compute nodes according to the grid regions. At each time step or every few time steps, due to atomic motions and other factors, the atoms within a grid region and the neighborhood undergo changes. This requires the use of MPI communication to exchange data. Since the neighborhood is shared by multiple regions or is irregularly partitioned and shared, data synchronization needs to be precisely done using the MPI mechanism to prevent dirty reads and writes.
(3) Fluid Mechanics Simulation
The principle of fluid mechanics simulation is based on a series of governing equations. Due to the difficulty in solving equations such as the Navier-Stokes, numerical methods such as the finite volume or finite element methods are commonly used in practical applications. Specifically, divide the fluid into numerous small volume elements, known as grids, and then compute and simulate the mechanical characteristics of each grid.
Parallel modes used in fluid mechanics simulation include data parallelism, task parallelism, and hybrid parallelism. For data parallelism, such as OpenMP, the compute domain is not partitioned but the memory can be shared. Each thread computes different data in the same partition. This mode is easy to implement but has low scalability. For task parallelism, such as MPI, the compute domain is partitioned but the memory is not shared. Each process independently computes the corresponding partition, and MPI communication is performed between partitions. This mode is suitable for large-scale expansion but is more complex to implement and has higher software architecture requirements. Hybrid parallelism refers to the combination of MPI and OpenMP, where OpenMP is used within a node and MPI is used across nodes. This mode ensures efficient communication and is suitable for large-scale expansion. Hybrid parallelism can be further divided into coarse-grained and fine-grained parallelism, as described in the relevant documentation for the CFD software PHengLEI.
References
[2] https://github.com/mpiwg-ft/ft-issues/blob/master/slides/MPI\_Stages.pdf
[3] HE Qiang, LI Yongjian, HUANG Weifeng, LI Decai, HU Yang, WANG Yuming. Parallel simulations of large-scale particle-fluid two-phase flows with the lattice Boltzmann method based on an MPI+OpenMP mixed programming model. Journal of Tsinghua University (Science and Technology), 2019, 59(10): 847-853.
[4] https://spcl.inf.ethz.ch/Publications/.pdf/hoefler-hpcac19-fompi-spin.pdf