Introduction to a New Method for Edge-Cloud Collaborative Training for Privacy Protection
Introduction to a New Method for Edge-Cloud Collaborative Training for Privacy Protection
Authors: Wang Sen, Wang Peng, Yao Xin, Cui Jinkai, Hu Qintao, Chen Renhai, Zhang Gong | Organization: Theory Lab, 2012 Laboratories
Paper Title
MistNet: Towards Private Neural Network Training with Local Differential Privacy
Paper URL: https://github.com/TL-System/plato/blob/main/docs/papers/MistNet.pdf
Code URLs
Plato: https://github.com/TL-System/plato
Sedna: https://github.com/kubeedge/sedna
01 Research Background
Since Google first proposed federated learning in the edge AI field, it has been a rapidly developing topic in both academia and industry. Two major challenges in edge AI are data heterogeneity and data privacy, which can be addressed by applying federated learning to edge computing. FedAvg, an algorithm used in federated learning, selects clients to participate in training during each round. This reduces the communication pressure and avoids unreliable communication. Additionally, clients only need to upload training gradients, which helps prevent the leakage of user data. Nevertheless, FedAvg still faces three main bottlenecks:
(1) As the size of the model increases, the volume of data transmitted surges, which can become a bottleneck that hinders system performance.
(2) Research in deep learning has shown that gradients can still contain information about the native data, allowing attackers to potentially infer users' private data.
(3) Edge computing capabilities vary greatly, with some devices being unable to complete the training process or slowing down the synchronization progress of federated learning due to insufficient computing power.
02 Paper Abstract
To address the three main issues of the FedAvg algorithm, we propose the MistNet algorithm. This algorithm divides a pre-trained DNN model into two parts: a feature extractor at the edge side and a classifier on the cloud. Deep learning training rules show that new data rarely updates the parameters of the feature extractor, but does update the parameters of the classifier. As a result, we keep the edge-side parameters fixed and use the feature extractor to process input data and obtain corresponding representation data. Then we send the representation data from the client to the server, and train the classifier on the cloud. The MistNet algorithm has been optimized according to the following edge scenarios:
(1) Reduces the volume of network transmission required for communication between the edge and the cloud. Instead of performing multiple rounds of gradient transmission between the cloud and edge, as is done in traditional federated learning, the extracted representation data is transmitted to the cloud for aggregated training. This reduces the frequency of network transmission between the cloud and edge, thereby reducing the overall volume of data transmitted for communication between the two.
(2) Enhances privacy protection by quantifying, adding noise to, compressing and disturbing the representation data. This makes it more difficult to infer the original data from the representation data on the cloud, thereby increasing the level of privacy protection for the data.
(3) Reduces computing resource requirements on the edge side by segmenting the pre-trained model and using the first several layers as a feature extractor, thereby reducing computing workloads on the client. The process of extracting features on the edge can be considered as an inference process, which allows federated learning to be completed using edge-side hardware that has only inference capabilities.
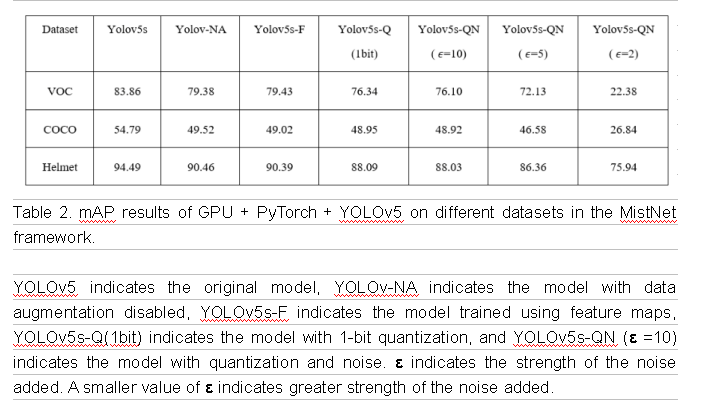
Experiments have shown that the MistNet algorithm can significantly reduce communication overheads and edge computing workloads compared to the FedAvg algorithm, with reductions of up to five times and ten times, respectively. Additionally, the training accuracy of the MistNet algorithm is better than that of FedAvg, with an improvement in convergence efficiency for automatic training in object detection tasks of up to 30%.
03 Algorithm Framework and Technical Key Points
Technical Key Point 1: Model Segmentation and Representation Migration
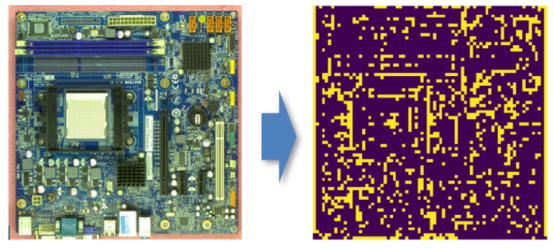
By utilizing the migration feature of the first several layers of a deep neural network, the server can train a model using existing data from a related or similar field and extract the first several layers to use as a feature extractor. The client can then obtain the feature extractor from a secure third party or server and randomly select the feature extractor and local data for fine-tuning.
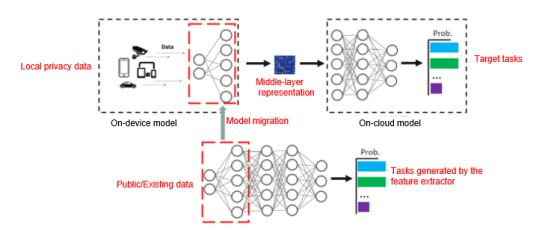
Figure 1: Schematic diagram of feature extraction
Technical Key Point 2: Quantization Solution for Representation Data
The communication volume can be effectively reduced by quantizing and compressing the representation data at the middle layer. An extreme solution is to use 1-bit quantization on the output of the activation function. Although this causes most of the representation data content to be lost, it effectively prevents information leakage.
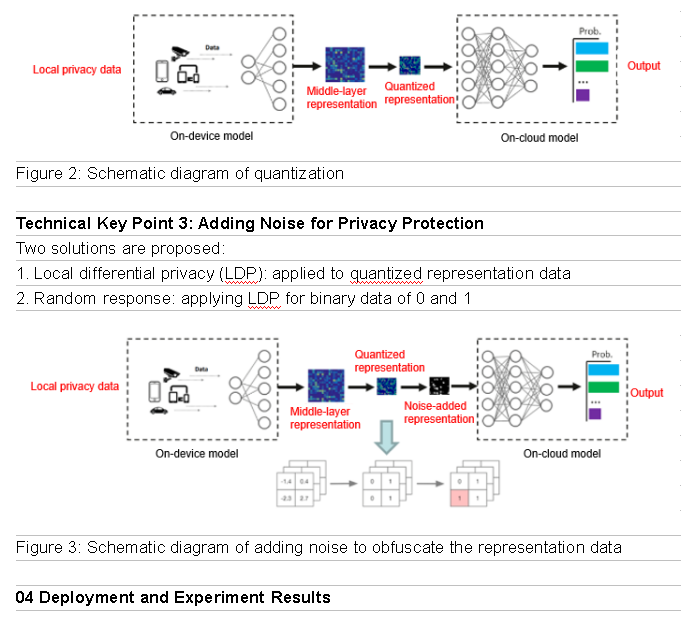
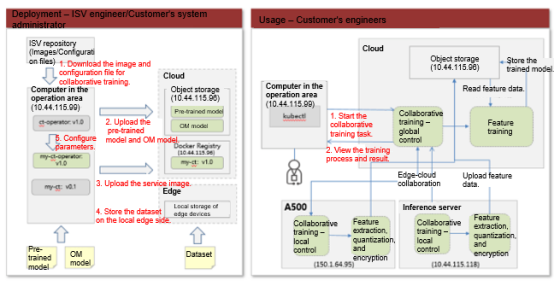
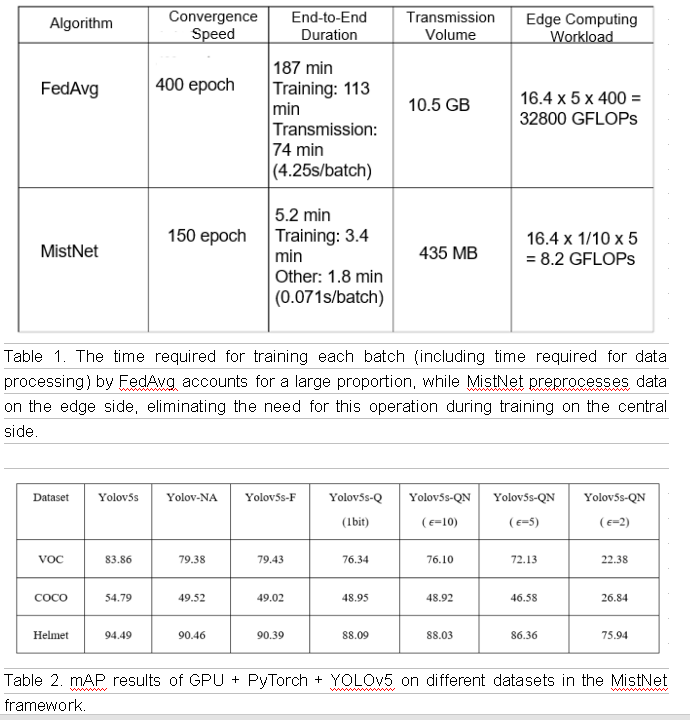
Figure 4: One-click deployment of the edge-cloud collaborative training framework for privacy protection on the Sedna platform
Software and Hardware
Hardware: Atlas 800 (9000) + Atlas 500 (3000)
Software: Ubuntu 18.04.5 LTS x86_64 + EulerOS V2R8 + CANN 5.0.2 + KubeEdge 1.8.2 + Sedna 0.4.0
Test Results
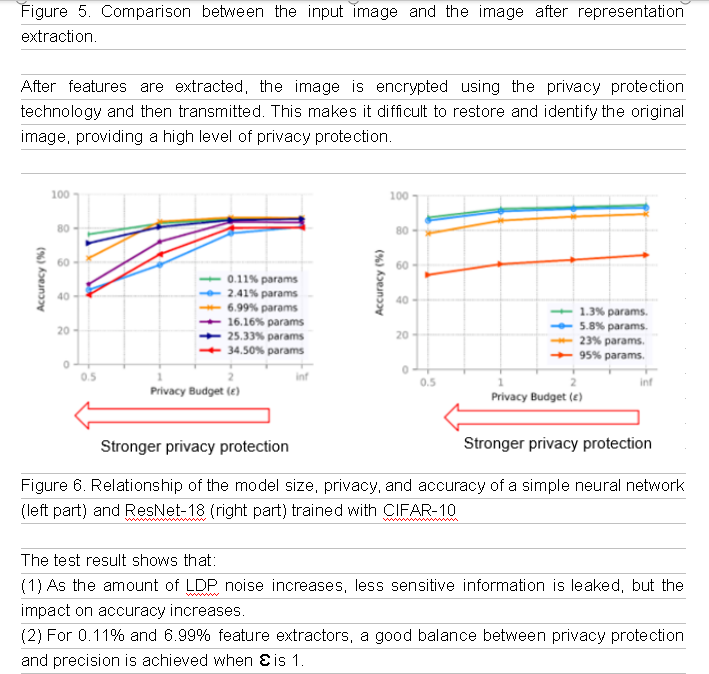
(3) The complex model has a stronger resistance to noise. For 1.3% and 5.8% feature extractors, a good balance between privacy protection and precision is achieved when Ɛ is 1.
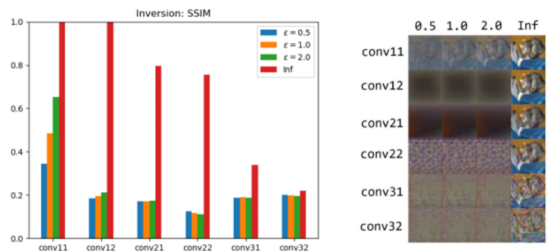
Figure 7. Defense effect against model inversion attacks.
We perform white-box tests to simulate model inversion attacks and use SSIM to verify the effect. If the SSIM is less than 0.3, the original image cannot be identified. As shown in the preceding figure, most feature extractors can effectively defend against model inversion attacks after using 1-bit quantization and LDP.
05 Code Implementation of NPU + MindSpore + YOLOv5
The code mainly includes the modules for data loading, network design, data privacy protection design, loss function design, and trainer design.
Data loading module:
def _has_only_empty_bbox(anno):
return all(any(o <= 1 for o in obj["bbox"][2:]) for obj in anno)
def _count_visible_keypoints(anno):
return sum(sum(1 for v in ann["keypoints"][2::3] if v > 0) for ann in anno)
def has_valid_annotation(anno):
"""Check annotation file."""
# if it's empty, there is no annotation
if not anno:
return False
# if all boxes have close to zero area, there is no annotation
if _has_only_empty_bbox(anno):
return False
# keypoints task have a slight different criteria for considering
# if an annotation is valid
if "keypoints" not in anno[0]:
return True
# for keypoint detection tasks, only consider valid images those
# containing at least min_keypoints_per_image
if _count_visible_keypoints(anno) >= min_keypoints_per_image:
return True
return False
class COCOYoloDataset:
"""YOLOV5 Dataset for COCO."""
def __init__(self, root, ann_file, remove_images_without_annotations=True,
filter_crowd_anno=True, is_training=True):
self.coco = COCO(ann_file)
self.root = root
self.img_ids = list(sorted(self.coco.imgs.keys()))
self.filter_crowd_anno = filter_crowd_anno
self.is_training = is_training
self.mosaic = True
# filter images without any annotations
if remove_images_without_annotations:
img_ids = []
for img_id in self.img_ids:
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = self.coco.loadAnns(ann_ids)
if has_valid_annotation(anno):
img_ids.append(img_id)
self.img_ids = img_ids
self.categories = {cat["id"]: cat["name"] for cat in self.coco.cats.values()}
self.cat_ids_to_continuous_ids = {
v: i for i, v in enumerate(self.coco.getCatIds())
}
self.continuous_ids_cat_ids = {
v: k for k, v in self.cat_ids_to_continuous_ids.items()
}
self.count = 0
def _mosaic_preprocess(self, index, input_size):
labels4 = []
s = 384
self.mosaic_border = [-s // 2, -s // 2]
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border]
indices = [index] + [random.randint(0, len(self.img_ids) - 1) for _ in range(3)]
for i, img_ids_index in enumerate(indices):
coco = self.coco
img_id = self.img_ids[img_ids_index]
img_path = coco.loadImgs(img_id)[0]["file_name"]
img = Image.open(os.path.join(self.root, img_path)).convert("RGB")
img = np.array(img)
h, w = img.shape[:2]
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 128, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
# filter crowd annotations
if self.filter_crowd_anno:
annos = [anno for anno in target if anno["iscrowd"] == 0]
else:
annos = [anno for anno in target]
target = {}
boxes = [anno["bbox"] for anno in annos]
target["bboxes"] = boxes
classes = [anno["category_id"] for anno in annos]
classes = [self.cat_ids_to_continuous_ids[cl] for cl in classes]
target["labels"] = classes
bboxes = target['bboxes']
labels = target['labels']
out_target = []
for bbox, label in zip(bboxes, labels):
tmp = []
# convert to [x_min y_min x_max y_max]
bbox = self._convetTopDown(bbox)
tmp.extend(bbox)
tmp.append(int(label))
# tmp [x_min y_min x_max y_max, label]
out_target.append(tmp) # out_target indicates the actual width and height of label, which corresponds to the actual measurement values of the image.
labels = out_target.copy()
labels = np.array(labels)
out_target = np.array(out_target)
labels[:, 0] = out_target[:, 0] + padw
labels[:, 1] = out_target[:, 1] + padh
labels[:, 2] = out_target[:, 2] + padw
labels[:, 3] = out_target[:, 3] + padh
labels4.append(labels)
if labels4:
labels4 = np.concatenate(labels4, 0)
np.clip(labels4[:, :4], 0, 2 * s, out=labels4[:, :4]) # use with random_perspective
flag = np.array([1])
return img4, labels4, input_size, flag
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
(img, target) (tuple): target is a dictionary contains "bbox", "segmentation" or "keypoints",
generated by the image's annotation. img is a PIL image.
"""
coco = self.coco
img_id = self.img_ids[index]
img_path = coco.loadImgs(img_id)[0]["file_name"]
if not self.is_training:
img = Image.open(os.path.join(self.root, img_path)).convert("RGB")
return img, img_id
input_size = [640, 640]
if self.mosaic and random.random() < 0.5:
return self._mosaic_preprocess(index, input_size)
img = np.fromfile(os.path.join(self.root, img_path), dtype='int8')
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
# filter crowd annotations
if self.filter_crowd_anno:
annos = [anno for anno in target if anno["iscrowd"] == 0]
else:
annos = [anno for anno in target]
target = {}
boxes = [anno["bbox"] for anno in annos]
target["bboxes"] = boxes
classes = [anno["category_id"] for anno in annos]
classes = [self.cat_ids_to_continuous_ids[cl] for cl in classes]
target["labels"] = classes
bboxes = target['bboxes']
labels = target['labels']
out_target = []
for bbox, label in zip(bboxes, labels):
tmp = []
# convert to [x_min y_min x_max y_max]
bbox = self._convetTopDown(bbox)
tmp.extend(bbox)
tmp.append(int(label))
# tmp [x_min y_min x_max y_max, label]
out_target.append(tmp)
flag = np.array([0])
return img, out_target, input_size, flag
def __len__(self):
return len(self.img_ids)
def _convetTopDown(self, bbox):
x_min = bbox[0]
y_min = bbox[1]
w = bbox[2]
h = bbox[3]
return [x_min, y_min, x_min+w, y_min+h]
def create_yolo_dataset(image_dir, anno_path, batch_size, max_epoch, device_num, rank,
config=None, is_training=True, shuffle=True):
"""Create dataset for YOLOV5."""
cv2.setNumThreads(0)
de.config.set_enable_shared_mem(True)
if is_training:
filter_crowd = True
remove_empty_anno = True
else:
filter_crowd = False
remove_empty_anno = False
yolo_dataset = COCOYoloDataset(root=image_dir, ann_file=anno_path, filter_crowd_anno=filter_crowd,
remove_images_without_annotations=remove_empty_anno, is_training=is_training)
distributed_sampler = DistributedSampler(len(yolo_dataset), device_num, rank, shuffle=shuffle)
yolo_dataset.size = len(distributed_sampler)
hwc_to_chw = CV.HWC2CHW()
config.dataset_size = len(yolo_dataset)
cores = multiprocessing.cpu_count()
num_parallel_workers = int(cores / device_num)
if is_training:
multi_scale_trans = MultiScaleTrans(config, device_num)
yolo_dataset.transforms = multi_scale_trans
dataset_column_names = ["image", "annotation", "input_size", "mosaic_flag"]
output_column_names = ["image", "annotation", "bbox1", "bbox2", "bbox3",
"gt_box1", "gt_box2", "gt_box3"]
map1_out_column_names = ["image", "annotation", "size"]
map2_in_column_names = ["annotation", "size"]
map2_out_column_names = ["annotation", "bbox1", "bbox2", "bbox3",
"gt_box1", "gt_box2", "gt_box3"]
ds = de.GeneratorDataset(yolo_dataset, column_names=dataset_column_names, sampler=distributed_sampler,
python_multiprocessing=True, num_parallel_workers=min(4, num_parallel_workers))
ds = ds.map(operations=multi_scale_trans, input_columns=dataset_column_names,
output_columns=map1_out_column_names, column_order=map1_out_column_names,
num_parallel_workers=min(12, num_parallel_workers), python_multiprocessing=True)
ds = ds.map(operations=PreprocessTrueBox(config), input_columns=map2_in_column_names,
output_columns=map2_out_column_names, column_order=output_column_names,
num_parallel_workers=min(4, num_parallel_workers), python_multiprocessing=False)
mean = [m * 255 for m in [0.485, 0.456, 0.406]]
std = [s * 255 for s in [0.229, 0.224, 0.225]]
ds = ds.map([CV.Normalize(mean, std),
hwc_to_chw], num_parallel_workers=min(4, num_parallel_workers))
def concatenate(images):
images = np.concatenate((images[..., ::2, ::2], images[..., 1::2, ::2],
images[..., ::2, 1::2], images[..., 1::2, 1::2]), axis=0)
return images
ds = ds.map(operations=concatenate, input_columns="image", num_parallel_workers=min(4, num_parallel_workers))
ds = ds.batch(batch_size, num_parallel_workers=min(4, num_parallel_workers), drop_remainder=True)
else:
ds = de.GeneratorDataset(yolo_dataset, column_names=["image", "img_id"],
sampler=distributed_sampler)
compose_map_func = (lambda image, img_id: reshape_fn(image, img_id, config))
ds = ds.map(operations=compose_map_func, input_columns=["image", "img_id"],
output_columns=["image", "image_shape", "img_id"],
column_order=["image", "image_shape", "img_id"],
num_parallel_workers=8)
ds = ds.map(operations=hwc_to_chw, input_columns=["image"], num_parallel_workers=8)
ds = ds.batch(batch_size, drop_remainder=True)
ds = ds.repeat(max_epoch)
return ds, len(yolo_dataset)
Network design module:
BackBone is divided into two parts, one on the client and the other on the server.
class YOLOv5Backbone_from(nn.Cell):
def __init__(self):
super(YOLOv5Backbone_from, self).__init__()
self.tenser_to_array = P.TupleToArray()
self.focusv2 = Focusv2(3, 32, k=3, s=1)
self.conv1 = Conv(32, 64, k=3, s=2)
self.C31 = C3(64, 64, n=1)
self.conv2 = Conv(64, 128, k=3, s=2)
def construct(self, x, input_shape):
"""construct method"""
#img_hight = P.Shape()(x)[2] * 2
#img_width = P.Shape()(x)[3] * 2
input_shape = F.shape(x)[2:4]
input_shape = F.cast(self.tenser_to_array(input_shape) * 2, ms.float32)
fcs = self.focusv2(x)
cv1 = self.conv1(fcs)
bcsp1 = self.C31(cv1)
cv2 = self.conv2(bcsp1)
return cv2, input_shape
class YOLOv5Backbone_to(nn.Cell):
def __init__(self):
super(YOLOv5Backbone_to, self).__init__()
self.C32 = C3(128, 128, n=3)
self.conv3 = Conv(128, 256, k=3, s=2)
self.C33 = C3(256, 256, n=3)
self.conv4 = Conv(256, 512, k=3, s=2)
self.spp = SPP(512, 512, k=[5, 9, 13])
self.C34 = C3(512, 512, n=1, shortcut=False)
def construct(self, cv2):
"""construct method"""
bcsp2 = self.C32(cv2)
cv3 = self.conv3(bcsp2)
bcsp3 = self.C33(cv3)
cv4 = self.conv4(bcsp3)
spp1 = self.spp(cv4)
bcsp4 = self.C34(spp1)
return bcsp2, bcsp3, bcsp4
Overall network architecture of the server:
class YOLOV5s(nn.Cell):
"""
YOLOV5 network.
Args:
is_training: Bool. Whether train or not.
Returns:
Cell, cell instance of YOLOV5 neural network.
Examples:
YOLOV5s(True)
"""
def __init__(self, is_training):
super(YOLOV5s, self).__init__()
self.config = ConfigYOLOV5()
# YOLOv5 network
self.feature_map = YOLOv5(backbone=YOLOv5Backbone_to(),
out_channel=self.config.out_channel)
# prediction on the default anchor boxes
self.detect_1 = DetectionBlock('l', is_training=is_training)
self.detect_2 = DetectionBlock('m', is_training=is_training)
self.detect_3 = DetectionBlock('s', is_training=is_training)
def construct(self, x, img_hight, img_width, input_shape):
small_object_output, medium_object_output, big_object_output = self.feature_map(x, img_hight, img_width)
output_big = self.detect_1(big_object_output, input_shape)
output_me = self.detect_2(medium_object_output, input_shape)
output_small = self.detect_3(small_object_output, input_shape)
# big is the final output which has smallest feature map
return output_big, output_me, output_small
class YOLOv5(nn.Cell):
def __init__(self, backbone, out_channel):
super(YOLOv5, self).__init__()
self.out_channel = out_channel
self.backbone = backbone
#print("self.backbone: ", self.backbone)
self.conv1 = Conv(512, 256, k=1, s=1) # 10
self.C31 = C3(512, 256, n=1, shortcut=False) # 11
self.conv2 = Conv(256, 128, k=1, s=1)
self.C32 = C3(256, 128, n=1, shortcut=False) # 13
self.conv3 = Conv(128, 128, k=3, s=2)
self.C33 = C3(256, 256, n=1, shortcut=False) # 15
self.conv4 = Conv(256, 256, k=3, s=2)
self.C34 = C3(512, 512, n=1, shortcut=False) # 17
self.backblock1 = YoloBlock(128, 255)
self.backblock2 = YoloBlock(256, 255)
self.backblock3 = YoloBlock(512, 255)
self.concat = P.Concat(axis=1)
def construct(self, x, img_hight, img_width):
"""
input_shape of x is (batch_size, 3, h, w)
feature_map1 is (batch_size, backbone_shape[2], h/8, w/8)
feature_map2 is (batch_size, backbone_shape[3], h/16, w/16)
feature_map3 is (batch_size, backbone_shape[4], h/32, w/32)
"""
#img_hight = P.Shape()(x)[2] * 2
#img_width = P.Shape()(x)[3] * 2
backbone4, backbone6, backbone9 = self.backbone(x)
cv1 = self.conv1(backbone9) # 10
ups1 = P.ResizeNearestNeighbor((img_hight / 16, img_width / 16))(cv1)
concat1 = self.concat((ups1, backbone6))
bcsp1 = self.C31(concat1) # 13
cv2 = self.conv2(bcsp1)
ups2 = P.ResizeNearestNeighbor((img_hight / 8, img_width / 8))(cv2) # 15
concat2 = self.concat((ups2, backbone4))
bcsp2 = self.C32(concat2) # 17
cv3 = self.conv3(bcsp2)
concat3 = self.concat((cv3, cv2))
bcsp3 = self.C33(concat3) # 20
cv4 = self.conv4(bcsp3)
concat4 = self.concat((cv4, cv1))
bcsp4 = self.C34(concat4) # 23
small_object_output = self.backblock1(bcsp2) # h/8, w/8
medium_object_output = self.backblock2(bcsp3) # h/16, w/16
big_object_output = self.backblock3(bcsp4) # h/32, w/32
return small_object_output, medium_object_output, big_object_output
Data privacy protection design module:
def encode_1b(x):
x[(x <= 0)] = 0
x[(x > 0)] = 1
return x
def randomize_1b(bit_tensor, epsilon):
"""
The default unary encoding method is symmetric.
"""
#assert isinstance(bit_tensor, tensor), 'the type of input data is not matched with the expected type(tensor)'
return symmetric_tensor_encoding_1b(bit_tensor, epsilon)
def symmetric_tensor_encoding_1b(bit_tensor, epsilon):
p = mnp.exp(epsilon / 2) / (mnp.exp(epsilon / 2) + 1)
q = 1 / (mnp.exp(epsilon / 2) + 1)
return produce_random_response_1b(bit_tensor, p, q)
def produce_random_response_1b(bit_tensor, p, q=None):
"""
Implements random response as the perturbation method.
when using torch tensor, we use Uniform Distribution to create Binomial Distribution
because torch have not binomial function
"""
q = 1 - p if q is None else q
uniformreal = mindspore.ops.UniformReal(seed=2)
binomial = uniformreal(bit_tensor.shape)
zeroslike = mindspore.ops.ZerosLike()
oneslike = mindspore.ops.OnesLike()
p_binomial = mnp.where(binomial > q, oneslike(bit_tensor), zeroslike(bit_tensor))
q_binomial = mnp.where(binomial <= q, oneslike(bit_tensor), zeroslike(bit_tensor))
return mnp.where(bit_tensor == 1, p_binomial, q_binomial)
Loss function module:
class YoloWithLossCell(nn.Cell):
"""YOLOV5 loss."""
def __init__(self, network):
super(YoloWithLossCell, self).__init__()
self.yolo_network = network
self.config = ConfigYOLOV5()
self.loss_big = YoloLossBlock('l', self.config)
self.loss_me = YoloLossBlock('m', self.config)
self.loss_small = YoloLossBlock('s', self.config)
def construct(self, x, y_true_0, y_true_1, y_true_2, gt_0, gt_1, gt_2, img_hight, img_width, input_shape):
yolo_out = self.yolo_network(x, img_hight, img_width, input_shape)
loss_l = self.loss_big(*yolo_out[0], y_true_0, gt_0, input_shape)
loss_m = self.loss_me(*yolo_out[1], y_true_1, gt_1, input_shape)
loss_s = self.loss_small(*yolo_out[2], y_true_2, gt_2, input_shape)
return loss_l + loss_m + loss_s * 0.2
class TrainingWrapper(nn.Cell):
"""Training wrapper."""
def __init__(self, network, optimizer, sens=1.0):
super(TrainingWrapper, self).__init__(auto_prefix=False)
self.network = network
self.network.set_grad()
self.weights = optimizer.parameters
self.optimizer = optimizer
self.grad = C.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.reducer_flag = False
self.grad_reducer = None
self.parallel_mode = context.get_auto_parallel_context("parallel_mode")
if self.parallel_mode in [ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL]:
self.reducer_flag = True
if self.reducer_flag:
mean = context.get_auto_parallel_context("gradients_mean")
if auto_parallel_context().get_device_num_is_set():
degree = context.get_auto_parallel_context("device_num")
else:
degree = get_group_size()
self.grad_reducer = nn.DistributedGradReducer(optimizer.parameters, mean, degree)
def construct(self, *args):
weights = self.weights
loss = self.network(*args)
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = self.grad(self.network, weights)(*args, sens)
if self.reducer_flag:
grads = self.grad_reducer(grads)
return F.depend(loss, self.optimizer(grads))
class Giou(nn.Cell):
"""Calculating giou"""
def __init__(self):
super(Giou, self).__init__()
self.cast = P.Cast()
self.reshape = P.Reshape()
self.min = P.Minimum()
self.max = P.Maximum()
self.concat = P.Concat(axis=1)
self.mean = P.ReduceMean()
self.div = P.RealDiv()
self.eps = 0.000001
def construct(self, box_p, box_gt):
"""construct method"""
box_p_area = (box_p[..., 2:3] - box_p[..., 0:1]) * (box_p[..., 3:4] - box_p[..., 1:2])
box_gt_area = (box_gt[..., 2:3] - box_gt[..., 0:1]) * (box_gt[..., 3:4] - box_gt[..., 1:2])
x_1 = self.max(box_p[..., 0:1], box_gt[..., 0:1])
x_2 = self.min(box_p[..., 2:3], box_gt[..., 2:3])
y_1 = self.max(box_p[..., 1:2], box_gt[..., 1:2])
y_2 = self.min(box_p[..., 3:4], box_gt[..., 3:4])
intersection = (y_2 - y_1) * (x_2 - x_1)
xc_1 = self.min(box_p[..., 0:1], box_gt[..., 0:1])
xc_2 = self.max(box_p[..., 2:3], box_gt[..., 2:3])
yc_1 = self.min(box_p[..., 1:2], box_gt[..., 1:2])
yc_2 = self.max(box_p[..., 3:4], box_gt[..., 3:4])
c_area = (xc_2 - xc_1) * (yc_2 - yc_1)
union = box_p_area + box_gt_area - intersection
union = union + self.eps
c_area = c_area + self.eps
iou = self.div(self.cast(intersection, ms.float32), self.cast(union, ms.float32))
res_mid0 = c_area - union
res_mid1 = self.div(self.cast(res_mid0, ms.float32), self.cast(c_area, ms.float32))
giou = iou - res_mid1
giou = C.clip_by_value(giou, -1.0, 1.0)
return giou
class Iou(nn.Cell):
"""Calculate the iou of boxes"""
def __init__(self):
super(Iou, self).__init__()
self.min = P.Minimum()
self.max = P.Maximum()
def construct(self, box1, box2):
"""
box1: pred_box [batch, gx, gy, anchors, 1, 4] ->4: [x_center, y_center, w, h]
box2: gt_box [batch, 1, 1, 1, maxbox, 4]
convert to topLeft and rightDown
"""
box1_xy = box1[:, :, :, :, :, :2]
box1_wh = box1[:, :, :, :, :, 2:4]
box1_mins = box1_xy - box1_wh / F.scalar_to_array(2.0) # topLeft
box1_maxs = box1_xy + box1_wh / F.scalar_to_array(2.0) # rightDown
box2_xy = box2[:, :, :, :, :, :2]
box2_wh = box2[:, :, :, :, :, 2:4]
box2_mins = box2_xy - box2_wh / F.scalar_to_array(2.0)
box2_maxs = box2_xy + box2_wh / F.scalar_to_array(2.0)
intersect_mins = self.max(box1_mins, box2_mins)
intersect_maxs = self.min(box1_maxs, box2_maxs)
intersect_wh = self.max(intersect_maxs - intersect_mins, F.scalar_to_array(0.0))
# P.squeeze: for effiecient slice
intersect_area = P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 0:1]) * \
P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 1:2])
box1_area = P.Squeeze(-1)(box1_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box1_wh[:, :, :, :, :, 1:2])
box2_area = P.Squeeze(-1)(box2_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box2_wh[:, :, :, :, :, 1:2])
iou = intersect_area / (box1_area + box2_area - intersect_area)
# iou : [batch, gx, gy, anchors, maxboxes]
return iou
class YoloLossBlock(nn.Cell):
"""
Loss block cell of YOLOV5 network.
"""
def __init__(self, scale, config=ConfigYOLOV5()):
super(YoloLossBlock, self).__init__()
self.config = config
if scale == 's':
# anchor mask
idx = (0, 1, 2)
elif scale == 'm':
idx = (3, 4, 5)
elif scale == 'l':
idx = (6, 7, 8)
else:
raise KeyError("Invalid scale value for DetectionBlock")
self.anchors = Tensor([self.config.anchor_scales[i] for i in idx], ms.float32)
self.ignore_threshold = Tensor(self.config.ignore_threshold, ms.float32)
self.concat = P.Concat(axis=-1)
self.iou = Iou()
self.reduce_max = P.ReduceMax(keep_dims=False)
self.confidence_loss = ConfidenceLoss()
self.class_loss = ClassLoss()
self.reduce_sum = P.ReduceSum()
self.giou = Giou()
def construct(self, prediction, pred_xy, pred_wh, y_true, gt_box, input_shape):
"""
prediction : origin output from yolo
pred_xy: (sigmoid(xy)+grid)/grid_size
pred_wh: (exp(wh)*anchors)/input_shape
y_true : after normalize
gt_box: [batch, maxboxes, xyhw] after normalize
"""
object_mask = y_true[:, :, :, :, 4:5]
class_probs = y_true[:, :, :, :, 5:]
true_boxes = y_true[:, :, :, :, :4]
grid_shape = P.Shape()(prediction)[1:3]
grid_shape = P.Cast()(F.tuple_to_array(grid_shape[::-1]), ms.float32)
pred_boxes = self.concat((pred_xy, pred_wh))
true_wh = y_true[:, :, :, :, 2:4]
true_wh = P.Select()(P.Equal()(true_wh, 0.0),
P.Fill()(P.DType()(true_wh),
P.Shape()(true_wh), 1.0),
true_wh)
true_wh = P.Log()(true_wh / self.anchors * input_shape)
# 2-w*h for large picture, use small scale, since small obj need more precise
box_loss_scale = 2 - y_true[:, :, :, :, 2:3] * y_true[:, :, :, :, 3:4]
gt_shape = P.Shape()(gt_box)
gt_box = P.Reshape()(gt_box, (gt_shape[0], 1, 1, 1, gt_shape[1], gt_shape[2]))
# add one more dimension for broadcast
iou = self.iou(P.ExpandDims()(pred_boxes, -2), gt_box)
# gt_box is x,y,h,w after normalize
# [batch, grid[0], grid[1], num_anchor, num_gt]
best_iou = self.reduce_max(iou, -1)
# [batch, grid[0], grid[1], num_anchor]
# ignore_mask IOU too small
ignore_mask = best_iou < self.ignore_threshold
ignore_mask = P.Cast()(ignore_mask, ms.float32)
ignore_mask = P.ExpandDims()(ignore_mask, -1)
# ignore_mask backpro will cause a lot maximunGrad and minimumGrad time consume.
# so we turn off its gradient
ignore_mask = F.stop_gradient(ignore_mask)
confidence_loss = self.confidence_loss(object_mask, prediction[:, :, :, :, 4:5], ignore_mask)
class_loss = self.class_loss(object_mask, prediction[:, :, :, :, 5:], class_probs)
object_mask_me = P.Reshape()(object_mask, (-1, 1)) # [8, 72, 72, 3, 1]
box_loss_scale_me = P.Reshape()(box_loss_scale, (-1, 1))
pred_boxes_me = xywh2x1y1x2y2(pred_boxes)
pred_boxes_me = P.Reshape()(pred_boxes_me, (-1, 4))
true_boxes_me = xywh2x1y1x2y2(true_boxes)
true_boxes_me = P.Reshape()(true_boxes_me, (-1, 4))
ciou = self.giou(pred_boxes_me, true_boxes_me)
ciou_loss = object_mask_me * box_loss_scale_me * (1 - ciou)
ciou_loss_me = self.reduce_sum(ciou_loss, ())
loss = ciou_loss_me * 4 + confidence_loss + class_loss
batch_size = P.Shape()(prediction)[0]
return loss / batch_size
Trainer design module:
def linear_warmup_lr(current_step, warmup_steps, base_lr, init_lr):
"""Linear learning rate."""
lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps)
lr = float(init_lr) + lr_inc * current_step
return lr
def warmup_step_lr(lr, lr_epochs, steps_per_epoch, warmup_epochs, max_epoch, gamma=0.1):
"""Warmup step learning rate."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
milestones = lr_epochs
milestones_steps = []
for milestone in milestones:
milestones_step = milestone * steps_per_epoch
milestones_steps.append(milestones_step)
lr_each_step = []
lr = base_lr
milestones_steps_counter = Counter(milestones_steps)
for i in range(total_steps):
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = lr * gamma**milestones_steps_counter[i]
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def multi_step_lr(lr, milestones, steps_per_epoch, max_epoch, gamma=0.1):
return warmup_step_lr(lr, milestones, steps_per_epoch, 0, max_epoch, gamma=gamma)
def step_lr(lr, epoch_size, steps_per_epoch, max_epoch, gamma=0.1):
lr_epochs = []
for i in range(1, max_epoch):
if i % epoch_size == 0:
lr_epochs.append(i)
return multi_step_lr(lr, lr_epochs, steps_per_epoch, max_epoch, gamma=gamma)
def warmup_cosine_annealing_lr(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Cosine annealing learning rate."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
lr_each_step = []
for i in range(total_steps):
last_epoch = i // steps_per_epoch
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def warmup_cosine_annealing_lr_V2(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Cosine annealing learning rate V2."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
last_lr = 0
last_epoch_V1 = 0
T_max_V2 = int(max_epoch*1/3)
lr_each_step = []
for i in range(total_steps):
last_epoch = i // steps_per_epoch
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
if i < total_steps*2/3:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
last_lr = lr
last_epoch_V1 = last_epoch
else:
base_lr = last_lr
last_epoch = last_epoch-last_epoch_V1
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi * last_epoch / T_max_V2)) / 2
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def warmup_cosine_annealing_lr_sample(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Warmup cosine annealing learning rate."""
start_sample_epoch = 60
step_sample = 2
tobe_sampled_epoch = 60
end_sampled_epoch = start_sample_epoch + step_sample*tobe_sampled_epoch
max_sampled_epoch = max_epoch+tobe_sampled_epoch
T_max = max_sampled_epoch
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
total_sampled_steps = int(max_sampled_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
lr_each_step = []
for i in range(total_sampled_steps):
last_epoch = i // steps_per_epoch
if last_epoch in range(start_sample_epoch, end_sampled_epoch, step_sample):
continue
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
lr_each_step.append(lr)
assert total_steps == len(lr_each_step)
return np.array(lr_each_step).astype(np.float32)
def get_lr(args):
"""generate learning rate."""
if args.lr_scheduler == 'exponential':
lr = warmup_step_lr(args.lr,
args.lr_epochs,
args.steps_per_epoch,
args.warmup_epochs,
args.max_epoch,
gamma=args.lr_gamma,
)
elif args.lr_scheduler == 'cosine_annealing':
lr = warmup_cosine_annealing_lr(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
elif args.lr_scheduler == 'cosine_annealing_V2':
lr = warmup_cosine_annealing_lr_V2(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
elif args.lr_scheduler == 'cosine_annealing_sample':
lr = warmup_cosine_annealing_lr_sample(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
else:
raise NotImplementedError(args.lr_scheduler)
return lr
06 Conclusion and Outlook
In this paper, a novel edge-cloud collaborative training method for privacy protection is proposed. Different from previous methods that require frequent communication between edge devices and cloud devices, MistNet only needs to upload intermediate features from the edge to the cloud once during training, significantly reducing the communication volume transmitted between the edge and cloud. By quantifying, adding noise to, compressing and disturbing the representation data, the method presented in this paper makes it more difficult to infer the original data from the representation data on the cloud, thereby increasing the level of privacy protection for the data.
In addition, the first several layers of the model are used as a feature extractor after the pre-trained model is segmented, thereby reducing computing workloads on the client. The MistNet algorithm further alleviates the defects of federated learning algorithms such as FedAvg. Nevertheless, new Federated learning-based algorithms that require low communication volume, strong privacy protection, and minimal edge computing workloads, are certainly worth further exploration and research.