Parameter Server for Distributed Training
Parameter Server for Distributed Training
As machine learning develops rapidly, the number of datasets and parameters used in model training is growing exponentially in order to improve the accuracy and generalization of neural networks. However, the hardware performance of a single node can hardly catch up growing needs for computing power, which will bring about potential bottlenecks.
Distributed training has risen as an effective solution to resolve performance bottlenecks on ultra-large-scale networks. It enables horizontal resource scaling to provide higher overall computing power while reducing requirements on hardware resources such as memory and CPUs of each single node.
Among those solutions, the Parameter Server framework is well suited for MindSpore. It addresses performance challenges using distributed machine learning algorithms. Parameter Server supports both asynchronous and synchronous stochastic gradient descent (SGD) training. It deploys model computing and model update in worker and server processes respectively, so that worker and server resources can scale out independently from each other. In addition, in a large data center, one or more computing, network, and storage nodes may break down. The Parameter Server framework can isolate the failed nodes to prevent them from interrupting ongoing training jobs.
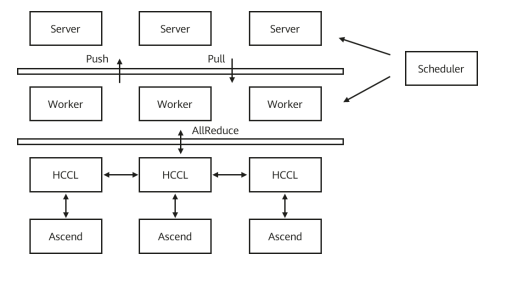
MindSpore uses the open source ps-lite, which is light and efficient implementation of the Parameter Server framework. The ps-lite architecture consists of three components: server, worker, and scheduler.
· Server: saves model weights and backward computation gradients, and updates the model using gradients pushed by workers.
· Worker: performs forward and backward computation on the network. The gradient value for backward computation is uploaded to a server through the Push API, and the model updated by the server is downloaded to the worker through the Pull API.
· Scheduler: establishes the communication relationship between the server and worker.
Based on the remote communication capability provided by the ps-lite and abstract Push/Pull primitives, MindSpore supports synchronous SGD for distributed training. Compared with the synchronous AllReduce training method, Parameter Server offers better flexibility and scalability as well as node failover capability.
Furthermore, with the high-performance collective communication libraries in Ascend and GPUs, that is, Huawei Collective Communication Library (HCCL) and NVIDIA Collective Communications Library (NCCL), MindSpore also provides the hybrid training mode of Parameter Server and AllReduce. Some weights can be stored and updated through Parameter Server, and others are trained using the AllReduce algorithm.
Figure: Distributed training with Parameter Server
For how to use the Parameter Server framework, go to: https://gitee.com/mindspore/docs/blob/r1.1/tutorials/training/source_en/advanced_use/apply_parameter_server_training.md
Click here to Meet MindSpore and explore more content like this.
References
[1] TensorFlow's tutorials for parameter server training
[2] Article by "MS xiaobai" at CNBlogs.com
[3] Microsoft's Azure Machine Learning Documentation