Get Started with MindSpore Graph Learning
Get Started with MindSpore Graph Learning
March 30, 2022

The Importance of Graph Learning Framework
Graph Neural Networks (GNNs) are becoming more popular in both industry and academia, and are frequently applied to drug identification and discovery, recommender systems, traffic flow prediction, and chip design workloads.
This explosive growth must grow in line with GNN model research, development, and application. However, if you develop a GNN algorithm based on an existing GNN framework using the message propagation mechanism, you must also program the feature tensors of all nodes. This is inverse to the principles of designing algorithms - start from the central node and aggregate outwards – and makes it difficult to develop GNN algorithms. In addition, existing frameworks may not fully cover optimization of the GNN algorithm process, such as the fusion mechanism and backward recalculation specific to GNNs. In short, the execution efficiency needs to be improved.
MindSpore Graph Learning
The MindSpore Graph Learning framework was jointly developed by Dr. Wu Yidi of the Chinese University of Hong Kong and the MindSpore team. It was built with the goal of making breakthroughs in usability and performance using the innovative point-centric programming paradigm and compilation optimization strategy for graph learning.
The following figure shows the overall architecture of MindSpore Graph Learning.

Node-centric programming model
The design of a GNN algorithm usually starts from the central node to describe how to convert and aggregate the feature vectors of neighboring nodes. This process is local and has low dimension. Take this GCN algorithm as an example:
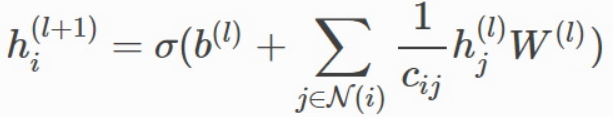
Naturally, we can write the algorithm is written in Python like this:

However, tensor-centric deep learning frameworks do not support such intuitive expressions. Instead, you must use the interfaces provided by the GNN framework, such as message and reduce, to implement the aggregation. What's more, you need to define the message sending and aggregation functions to convert the aggregation logic into the code logic for calculating the high-dimensional tensor consisting of all node features in the graph. This is far more complex than the expression above.
For this reason, we propose a node-centric programming model. With our model, the core steps of GCN can be implemented as follows:

Where v indicates the central node; v.innbs is invoked to obtain the neighboring node list; and then g.sum is used for summation and aggregation. In this way, writing a GNN model is as simple as writing a common Python program. Let's take the GAT model as an example to further demonstrate our programming model.

The GAT formulas are shown on the left. u and v indicate the start and end points of the edge (u, v). We can see that the code based on our GNN framework can largely map to the formulas.
The node-centric programming model greatly makes it easier to develop new models and facilitates model implementation and iteration. In addition, this model has the same expression capability as the message-passing-based method and can support any existing GNN model.
The model's usability and expression allow us to quickly reproduce the convolutional library and model library of DGL, a popular GNN framework. To date, it supports 10 classic models, covering multiple fields such as homogeneous and heterogeneous models, recommendation models, knowledge graph, and life sciences.
To implement node-centric programming, MindSpore Graph Learning must:
Identify new programming model code and execute it on MindSpore.
Integrate the new programming model with the tensor-centric code of MindSpore to seamlessly connect the code of two different programming models.
Reuse MindSpore features, such as automatic differentiation, automatic parallelism, switching between dynamic and static graphs, computational graph compilation, and support new features in the future.
To meet these requirements, MindSpore Graph Learning builds a new parser that uses the source-to-source conversion method to convert node-centric code into native code supported by MindSpore.
This allows different programming models to exchange data using tensors, producing MindSpore code from source-to-source conversion, ensuring full compatibility with all MindSpore features without any modification to the existing framework.
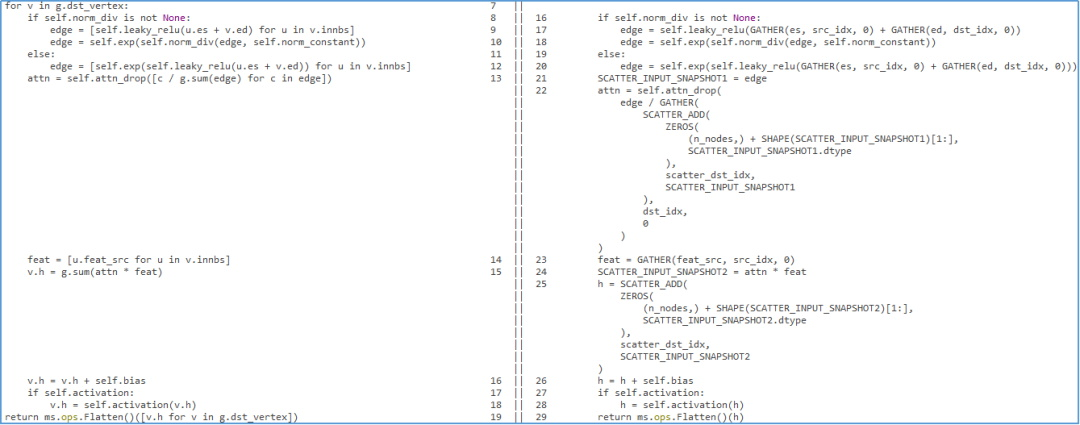
To simplify checks of the generated code, we also provide a line-by-line code conversion comparison tool. The following figure shows the comparison of the original and converted code of the GAT model.
Optimized Compilation
Different from other deep learning models, a GNN model converted into MindSpore tensors using Gather and Scatter operators adopts a Gather-Injective-Scatter (GIS) execution pattern, regardless if it is a homogeneous or heterogeneous graph.
As such, we add the GIS operator fusion pattern to MindSpore, where one or more Gather, Injective, and Scatter operators are fused into one operator. After the operator fusion, the polyhedral technology is used to automatically optimize and generate operators during AKG operator compilation. The process is as follows:
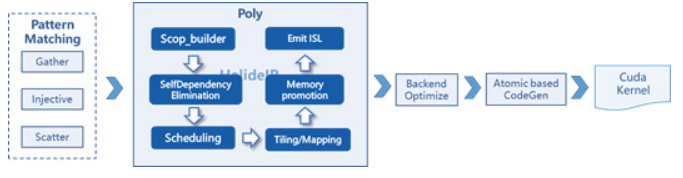
We also implement a recalculation solution based on operator fusion. Based on automatically identified calculation patterns that correspond to ultra-large tensors, the operators are recalculated, replicated, and fused, so that the ultra-large tensors are not generated.
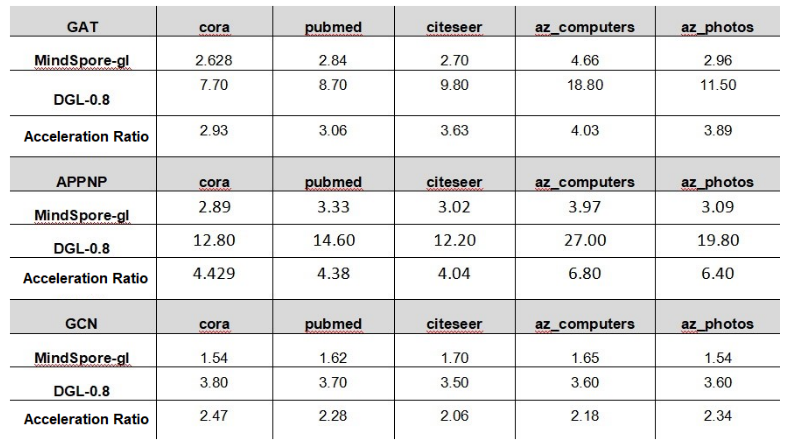
By reducing the instantiation of tensors in video memory, our framework has achieved 3 to 4 times the performance of the DGL framework.
Outlook
In future versions, we will add features such as large-scale graph learning performance optimization, efficient distributed graph sampling and training, and support for multiple heterogeneous hardware backends. These will enable MindSpore Graph Learning to better support GNN models in industrial scenarios based on large-scale interaction graphs, such as product or news recommendation and financial risk control.

MindSpore website: https://www.mindspore.cn/en
MindSpore Repositories