Using C++ Interface to Perform Inference
![]()
MindSpore has unified the inference API. If you want to continue to use the MindSpore Lite independent API for inference, you can refer to the document.
Overview
After the model is converted into a .ms model by using the MindSpore Lite model conversion tool, the inference process can be performed in Runtime. For details, see Converting Models for Inference. This tutorial describes how to use the C++ API to perform inference.
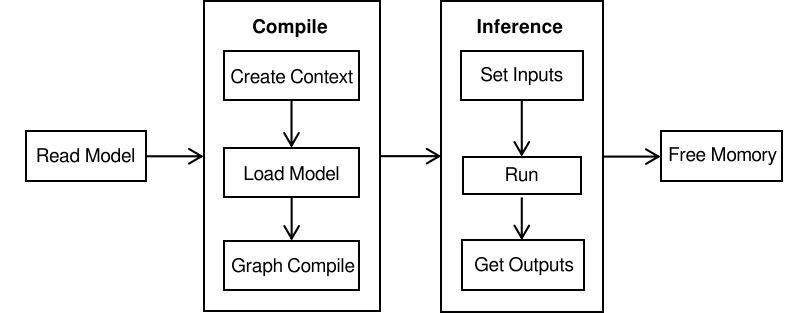
To use the MindSpore Lite inference framework, perform the following steps:
Read the model: Read the
.msmodel file converted by the model conversion tool from the file system.Create and configure context: Create and configure Context to save some basic configuration parameters required to build and execute the model.
Create, load and build a model: Use Build of Model to create and build the model, and configure the Context obtained in the previous step. In the model loading phase, the file cache is parsed into a runtime model. In the model building phase, subgraph partition, operator selection and scheduling are performed, which will take a long time. Therefore, it is recommended that the model should be created once, built once, and performed for multiple times.
Input data: Before the model is executed, data needs to be filled in the
Input Tensor.Perform inference: Use Predict of Model to perform model inference.
Obtain the output: After the model execution is complete, you can obtain the inference result by
Output Tensor.Release the memory: If the MindSpore Lite inference framework is not required, release the created Model.
For details about the calling process of MindSpore Lite inference, see Simplified MindSpore Lite C++ Demo.
Model Reading
When MindSpore Lite is used for model inference, read the .ms model file converted by using the model conversion tool from the file system and store it in the memory buffer. For details, see Converting Models for Inference.
The following sample code from main.cc demonstrates how to load a MindSpore Lite model from the file system:
// Read model file.
size_t size = 0;
char *model_buf = ReadFile(model_path, &size);
if (model_buf == nullptr) {
std::cerr << "Read model file failed." << std::endl;
}
Creating and Configuring Context
The context saves some basic configuration parameters required to build and execute the model. If you use new to create a Context and do not need it any more, use delete to release it. Generally, the Context is released after the Model is created and built.
The default backend of MindSpore Lite is CPU. After Context is created, call MutableDeviceInfo to return list of backend device information. Add the default CPUDeviceInfo to the list.
The following sample code from main.cc demonstrates how to create a context, configure the default CPU backend, and enable CPU float16 inference.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
}
// CPU use float16 operator as priority.
cpu_device_info->SetEnableFP16(true);
device_list.push_back(cpu_device_info);
MutableDeviceInfosupports multiple DeviceInfos, including CPUDeviceInfo, GPUDeviceInfo, KirinNPUDeviceInfo. The device number limit is 3. During the inference, the operator will choose device in order.float16 takes effect only when the CPU is under the ARM v8.2 architecture. Other models and x86 platforms that do not supported float16 will be automatically rolled back to float32.
For the iOS platform, only the CPU backend is supported, and float16 is temporarily not supported.
The advanced interfaces contained in Context are defined as follows:
Configuring the Number of Threads
Use SetThreadNum of Context to configure the number of threads:
// Configure the number of worker threads in the thread pool to 2, including the main thread.
context->SetThreadNum(2);
Configuring the Thread Affinity
Use SetThreadAffinity of Context to configure the thread affinity. If the parameter is int mode, configure the binding strategy. The effective value is 0-2, 0 means no core binding by default, 1 means preferential binding to large cores, and 2 means preferential binding to small cores. If the parameter is const std::vector<int> &core_list, configure the binding core list. When configuring at the same time, the core_list is effective, but the mode is not effective.
// Configure the thread to be bound to the big core first.
// Valid value: 0: no affinities, 1: big cores first, 2: little cores first
context->SetThreadAffinity(1);
Configuring the Parallelization
Use SetEnableParallel of Context to configure whether to support parallelism when executing inference:
// Configure the inference supports parallel.
context->SetEnableParallel(true);
Configuring the GPU Backend
If the backend to be executed is GPUs, you need to set GPUDeviceInfo as the first choice. It is suggested to set CPUDeviceInfo as the second choice, to ensure model inference. Use SetEnableFP16 to enable GPU float16 inference.
The following sample code from main.cc demonstrates how to create the CPU and GPU heterogeneous inference backend and how to enable float16 inference for the GPU.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
// Set GPU device first, make GPU preferred backend.
auto gpu_device_info = std::make_shared<mindspore::GPUDeviceInfo>();
if (gpu_device_info == nullptr) {
std::cerr << "New GPUDeviceInfo failed." << std::endl;
}
// GPU use float16 operator as priority.
gpu_device_info->SetEnableFP16(true);
// Set VNIDIA device id, only valid when GPU backend is TensorRT.
gpu_device_info->SetDeviceID(0);
// The GPU device context needs to be push_back into device_list to work.
device_list.push_back(gpu_device_info);
// Set CPU device after GPU as second choice.
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
}
// CPU use float16 operator as priority.
cpu_device_info->SetEnableFP16(true);
device_list.push_back(cpu_device_info);
The current GPU backend distinguishes
arm64andx86_64platforms.
On
arm64, the backend of GPU is based on OpenCL. GPUs of Mali and Adreno are supported. The OpenCL version is 2.0.The configuration is as follows:
CL_TARGET_OPENCL_VERSION=200
CL_HPP_TARGET_OPENCL_VERSION=120
CL_HPP_MINIMUM_OPENCL_VERSION=120
On
x86_64, the backend of GPU is based on TensorRT. The TensorRT version is 6.0.1.5.Whether the attribute
SetEnableFP16can be set successfully depends on the CUDA computer capability of the current device.The attribute
SetDeviceIDonly valid for TensorRT, used to specify the NVIDIA device ID.
Configuring the NPU Backend
If the backend to be executed is NPUs, you need to set KirinNPUDeviceInfo as the first choice. It is suggested to set CPUDeviceInfo as the second choice, to ensure model inference. Use SetFrequency to set npu frequency.
The following sample code from main.cc shows how to create the CPU and NPU heterogeneous inference backend and set the NPU frequency to 3. It can be set to 1 (low power consumption), 2 (balanced), 3 (high performance), 4 (extreme performance).
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
// Set NPU device first, make NPU preferred backend.
auto npu_device_info = std::make_shared<mindspore::KirinNPUDeviceInfo>();
if (npu_device_info == nullptr) {
std::cerr << "New KirinNPUDeviceInfo failed." << std::endl;
}
// NPU set frequency to be 3.
npu_device_info->SetFrequency(3);
// The NPU device context needs to be push_back into device_list to work.
device_list.push_back(npu_device_info);
// Set CPU device after NPU as second choice.
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
}
// CPU use float16 operator as priority.
cpu_device_info->SetEnableFP16(true);
device_list.push_back(cpu_device_info);
Configuring the NNIE Backend
When the backend that needs to be executed is the heterogeneous inference based on CPU and NNIE, you only need to create the Context according to the configuration method of CPU Backend without specifying a provider.
Configuring the ASCEND Backend
If the backend to be executed is Ascend(only support Atlas 200/300/500 inference product), you need to set AscendDeviceInfo as the first choice. It is suggested to set CPUDeviceInfo as the second choice, to ensure model inference. Use SetDeviceID to set ascend device id.
The following sample code shows how to create the CPU and ASCEND heterogeneous inference backend and set ascend device id to 0.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
// Set Atlas 200/300/500 inference product device first, make Atlas 200/300/500 inference product preferred backend.
auto ascend_device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (ascend_device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
}
// Atlas 200/300/500 inference product set device id to be 0.
ascend_device_info->SetDeviceId(0);
// The Atlas 200/300/500 inference product device context needs to be push_back into device_list to work.
device_list.push_back(ascend_device_info);
// Set CPU device after Atlas 200/300/500 inference product as second choice.
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
}
device_list.push_back(cpu_device_info);
Configuring the CoreML Backend
If the backend to be executed is CoreML, you need to instantiate the CoreMLDelegate class,and use SetDelegate to pass the instance object into the context object. It is slightly different from the configuring steps of backends defined by hardware such as NPU and GPU.
The following sample code shows how to create the CPU and CoreML heterogeneous inference backend:
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
// Set CPU device after NPU as second choice.
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
}
device_list.push_back(cpu_device_info);
auto coreml_delegate = std::make_shared<CoreMLDelegate>();
if (coreml_delegate == nullptr) {
std::cerr << "New CoreMLDelegate failed." << std::endl;
}
context->SetDelegate(coreml_delegate);
The CoreML backend is only supported on devices whose operating system version is not lower than iOS 11 for now.
Model Creating Loading and Building
When MindSpore Lite is used for inference, Model is the main entry for inference. You can use Model to load, build and execute model. Use the Context created in the previous step to call the Build of Model to load and build the runtime model.
The following sample code from main.cc demonstrates how to create, load and build a model:
// Create model
auto model = new (std::nothrow) mindspore::Model();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
}
// Build model
auto build_ret = model->Build(model_buf, size, mindspore::kMindIR, context);
delete[](model_buf);
// After the model is built, the Context can be released.
...
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
}
After the Model is loaded and built, the Context created in the previous step can be released.
For large models, when using the model buffer to load and compile, you need to set the path of the weight file separately, sets the model path through LoadConfig or UpdateConfig interface, where
sectionismodel_File,keyismindir_path. When using the model path to load and compile, you do not need to set other parameters. The weight parameters will be automatically read.If the user enables the
MSLITE_ENABLE_MODEL_PRE_INFERENCEfunction when compiling the source code, the runtime will perform pre-inference by default in the Build phase(non-encrypted scenario) to check whether the program can execute normally. This function can be disabled through LoadConfig or UpdateConfig interface, wheresectioniscommon,keyisenable_pre_inference,valueistrueorfalse.
Inputting Data
Before executing a model, obtain the input MSTensor of the model and copy the input data to the input Tensor using memcpy. In addition, you can use the DataSize method to obtain the size of the data to be filled in to the tensor, use the DataType method to obtain the data type of the tensor, and use the MutableData method to obtain the writable data pointer.
MindSpore Lite provides two methods to obtain the input tensor of a model.
Use the GetInputByTensorName method to obtain the input tensor based on the name. The following sample code from main.cc demonstrates how to call
GetInputByTensorNameto obtain the input tensor and fill in data.// Pre-processing of input data, convert input data format to NHWC. ... // Assume that the model has only one input tensor named graph_input-173. auto in_tensor = model->GetInputByTensorName("graph_input-173"); if (in_tensor.impl() == nullptr) { std::cerr << "Input tensor is nullptr" << std::endl; } auto input_data = in_tensor.MutableData(); if (input_data == nullptr) { std::cerr << "MallocData for inTensor failed." << std::endl; } memcpy(in_data, input_buf, data_size); // Users need to free input_buf.
Use the GetInputs method to directly obtain the vectors of all model input tensors. The following sample code from main.cc demonstrates how to call
GetInputsto obtain the input tensor and fill in data.// Pre-processing of input data, convert input data format to NHWC. ... // Assume we have created a Model instance named model. auto inputs = model->GetInputs(); // Assume that the model has only one input tensor. auto in_tensor = inputs.front(); if (in_tensor == nullptr) { std::cerr << "Input tensor is nullptr" << std::endl; } auto *in_data = in_tensor.MutableData(); if (in_data == nullptr) { std::cerr << "Data of in_tensor is nullptr" << std::endl; } memcpy(in_data, input_buf, data_size); // Users need to free input_buf.
The data layout in the input tensor of the MindSpore Lite model must be
NHWC. For more information about data pre-processing, see step 2 in Writing On-Device Inference Code in Android Application Development Based on JNI Interface to convert the input image into the Tensor format of the MindSpore model.GetInputs and GetInputByTensorName methods return data that do not need to be released by users.
Executing Inference
Call the Predict function of Model for model inference.
The following sample code from main.cc demonstrates how to call Predict to perform inference.
auto inputs = model->GetInputs();
auto outputs = model->GetOutputs();
auto predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Predict error " << predict_ret << std::endl;
}
Obtaining Output
After performing inference, MindSpore Lite can obtain the inference result of the model. MindSpore Lite provides three methods to obtain the output MSTensor of a model.
Use the GetOutputsByNodeName method to obtain the vector of the tensor connected to the model output tensor based on the name of the model output node. The following sample code from main.cc demonstrates how to call
GetOutputsByNodeNameto obtain the output tensor.// Assume we have created a Model instance named model before. // Assume that model has a output node named Softmax-65. auto output_vec = model->GetOutputsByNodeName("Softmax-65"); // Assume that output node named Default/Sigmoid-op204 has only one output tensor. auto out_tensor = output_vec.front(); if (out_tensor == nullptr) { std::cerr << "Output tensor is nullptr" << std::endl; } // Post-processing your result data.
Use the GetOutputByTensorName method to obtain the corresponding model output tensor based on the name of the model output tensor. The following sample code from main.cc demonstrates how to call
GetOutputsByTensorNameto obtain the output tensor.// Assume we have created a Model instance named model. // We can use GetOutputTensorNames method to get all name of output tensor of model which is in order. auto tensor_names = model->GetOutputTensorNames(); // Assume we have created a Model instance named model before. for (auto tensor_name : tensor_names) { auto out_tensor = model->GetOutputByTensorName(tensor_name); if (out_tensor == nullptr) { std::cerr << "Output tensor is nullptr" << std::endl; } // Post-processing the result data. }
Use the GetOutputs method to directly obtain the names of all model output tensors vector. The following sample code from main.cc demonstrates how to call
GetOutputsto obtain the output tensor.// Assume we have created a Model instance named model. auto out_tensors = model->GetOutputs(); for (auto out_tensor : out_tensors) { // Post-processing the result data. }
The data returned by the GetOutputsByNodeName, GetOutputByTensorName, and GetOutputs methods does not need to be released by the user.
Releasing Memory
If the MindSpore Lite inference framework is not required, you need to release the created Model. The following sample code from main.cc demonstrates how to release the memory before the program ends.
// Delete model.
// Assume that the variable of Model * is named model.
delete model;
Advanced Usage
Resizing the Input Dimension
When MindSpore Lite is used for inference, if the input shape needs to be resized, you can call the Resize API of Model to resize the shape of the input tensor after a model is created and built.
Some networks do not support variable dimensions. As a result, an error message is displayed and the model exits unexpectedly. For example, the model contains the MatMul operator, one input tensor of the MatMul operator is the weight, and the other input tensor is the input. If a variable dimension API is called, the input tensor does not match the shape of the weight tensor. As a result, the inference fails.
When the GPU backend is TensorRT, Resize only valid at dims NHW for NHWC format inputs, resize shape value should not be larger than the model inputs.
The following sample code from main.cc demonstrates how to perform Resize on the input tensor of MindSpore Lite:
// Assume we have created a Model instance named model.
auto inputs = model->GetInputs();
std::vector<int64_t> resize_shape = {1, 128, 128, 3};
// Assume the model has only one input,resize input shape to [1, 128, 128, 3]
std::vector<std::vector<int64_t>> new_shapes;
new_shapes.push_back(resize_shape);
return model->Resize(inputs, new_shapes);
Mixed Precision Inference
MindSpore Lite supports mixed precision inference. Users can set mixed precision information by calling the LoadConfig API of Model after a model is created and before built. The example of the config file is as follows:
[execution_plan]
op_name1=data_type:float16
op_name2=data_type:float32
The following sample code from main.cc demonstrates how to infer model in the mixed precision:
Status load_config_ret = model->LoadConfig(config_file_path);
if (load_config_ret != mindspore::kSuccess) {
std::cerr << "Model load config error " << load_config_ret << std::endl;
return -1;
}
Status build_ret = model->Build(graph_cell, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Model build error " << build_ret << std::endl;
return -1;
}
auto inputs = model->GetInputs();
auto outputs = model->GetOutputs();
Status predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Model predict error " << predict_ret << std::endl;
return -1;
}
Multiple Heterogeneous Devices Inference
MindSpore Lite supports multiple heterogeneous devices inference. Users can set multiple heterogeneous devices inference information by set multiple DeviceInfoContext in Context.
The following sample code from main.cc demonstrates how to infer the model in multiple heterogeneous devices:
mindspore::Context context;
// enable NPU CPU GPU in inference. NPU is preferentially used, then the CPU, and GPU get the lowest priority.
context.MutableDeviceInfo().push_back(std::make_shared<mindspore::KirinNPUDeviceInfo>());
context.MutableDeviceInfo().push_back(std::make_shared<mindspore::CPUDeviceInfo>());
context.MutableDeviceInfo().push_back(std::make_shared<mindspore::GPUDeviceInfo>());
Status build_ret = model->Build(graph_cell, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Model build error " << build_ret << std::endl;
return -1;
}
auto inputs = model->GetInputs();
auto outputs = model->GetOutputs();
Status predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Model predict error " << predict_ret << std::endl;
return -1;
}
OpenGL Texture Data Input
MindSpore Lite supports OpenGL texture input, performs end-to-end GPU isomorphic inference, and the inference result is returned as OpenGL texture data. This function needs to be configured in the Context during use, and OpenGL texture data is bound to it during inference. These two processes.
Configured Context
The user needs to set the SetEnableGLTexture property in dev.gpu_device_info_ in Context to true, and configure the user’s current OpenGL EGLContext and EGLDisplay through the SetGLContext interface and SetGLDisplay interface respectively.
const std::shared_ptr<mindspore::Context> context; auto &device_list = context->MutableDeviceInfo(); // 1. Set EnableGLTexture true gpu_device_info->SetEnableGLTexture(true); // 2. Set GLContext auto gl_context = eglGetCurrentContext(); gpu_device_info->SetGLContext(gl_context); // 3. Set GLDisplay auto gl_display = eglGetCurrentDisplay(); gpu_device_info->SetGLDisplay(gl_display);
Bind OpenGL Texture Data
After the model is compiled and before the model runs, the user needs to call BindGLTexture2DMemory(const std::map<std::string, GLuint> &inputGlTexture, std::map<std::string, GLuint> *outputGLTexture;) function to bind the input Output texture, instead of the original input data step. Because MindSpore Lite itself does not allocate OpenGL memory, the user is required to create the input and output texture memory in advance according to the tensor size of the model input and output, and the texture memory corresponding to the texture ID Bind to the input and output of the model, the sample code is as follows:
std::map<std::string, GLuint> input_gl_texture; std::map<std::string, GLuint> output_gl_texture; ... // Write OpenGL Texture data(GLuint) into input_gl_texture and output_gl_texture // Bind texture data with input and output tensors auto status = ms_model_.BindGLTexture2DMemory(input_gl_texture, &output_gl_texture); if (status != kSuccess) { MS_LOG(ERROR) << "BindGLTexture2DMemory failed"; return kLiteError; } return kSuccess;
In std::map<std::string, GLuint> input_gl_texture, the key is the model input tensor name, and the value is the corresponding GLuint texture; std::map<std::string, GLuint> the key in the output_gl_texture variable is the model output tensor name, Value is the corresponding GLuint texture. The model input and output tensor name can be obtained through the tensor.Name() interface. The sample code is as follows:
std::vector<mindspore::MSTensor> inputs; vector<GLuint> inTextureIDs; for (auto i; i < inputs.size(); i++) { inputGlTexture.insert(std::pair<std::string, GLuint>(inputs.at(i).Name(), inTextureIDs.at(i)); } std::vector<mindspore::MSTensor> outputs; vector<GLuint> outTextureIDs; for (auto i; i < inputs.size(); i++) { outputGlTexture.insert(std::pair<std::string, GLuint>(inputs.at(i).Name(), outTextureIDs.at(i)); }
Predict
After the binding is completed, you can directly call the Predict interface of ms_model_ for inference. The model output will be copied to the memory corresponding to the bound output texture ID, and the user can obtain the inference result from the outputs.
std::vector<MSTensor> outputs; auto ret = ms_model_.Predict(ms_inputs_for_api_, &outputs, ms_before_call_back_, ms_after_call_back_); if (ret != kSuccess) { MS_LOG(ERROR) << "Inference error "; std::cerr << "Inference error " << std::endl; return kLiteError; }
Calling Back a Model During the Running Process
MindSpore Lite can pass two MSKernelCallBack function pointers to Predict to call back a model for inference. Compared with common graph execution, callback execution can obtain additional information during the running process to help developers analyze performance and debug bugs. Additional information includes:
Name of the running node
Input and output tensors before the current node is inferred
Input and output tensors after the current node is inferred
The following sample code from main.cc demonstrates how to define two callback functions as the pre-callback pointer and post-callback pointer and pass them to the Predict API for callback inference.
// Definition of callback function before forwarding operator.
auto before_call_back = [](const std::vector<mindspore::MSTensor> &before_inputs,
const std::vector<mindspore::MSTensor> &before_outputs,
const mindspore::MSCallBackParam &call_param) {
std::cout << "Before forwarding " << call_param.node_name_ << " " << call_param.node_type_ << std::endl;
return true;
};
// Definition of callback function after forwarding operator.
auto after_call_back = [](const std::vector<mindspore::MSTensor> &after_inputs,
const std::vector<mindspore::MSTensor> &after_outputs,
const mindspore::MSCallBackParam &call_param) {
std::cout << "After forwarding " << call_param.node_name_ << " " << call_param.node_type_ << std::endl;
return true;
};
auto inputs = model->GetInputs();
auto outputs = model->GetOutputs();
auto predict_ret = model->Predict(inputs, &outputs, before_call_back, after_call_back);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Predict error " << predict_ret << std::endl;
}
Separating Graph Loading and Model Build
Use Load of Serialization to load Graph and use Build of Model to build the model.
The following sample code from main.cc demonstrates how to load graph and build model separately.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
}
auto &device_list = context->MutableDeviceInfo();
auto cpu_device_info = CreateCPUDeviceInfo();
if (cpu_device_info == nullptr) {
std::cerr << "Create CPUDeviceInfo failed." << std::endl;
}
device_list.push_back(cpu_device_info);
// Load graph
mindspore::Graph graph;
auto load_ret = mindspore::Serialization::Load(model_buf, size, mindspore::kMindIR, &graph);
if (load_ret != mindspore::kSuccess) {
std::cerr << "Load graph failed." << std::endl;
}
// Create model
auto model = new (std::nothrow) mindspore::Model();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
return nullptr;
}
// Build model
mindspore::GraphCell graph_cell(graph);
auto build_ret = model->Build(graph_cell, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
}
Decrypted Model Prediction
If the model is encrypted by the converter_lite tool,the decryption key and decryption library are necessary to pass into the program. The dec_key should be the same as the encryption key used in converter_lite tool,which both are hexadecimal character strings, for example, the hexadecimal string corresponding to b’0123456789ABCDEF is 30313233343536373839414243444546. On the Linux platform, you can use the xxd tool to convert the key represented by bytes to a hexadecimal string. The crypto_lib_path is the path for the installed OpenSSL library, for example, “/home/root/openssl”.
The following sample code from main.cc demonstrates how to load graph and build model separately:
int RunEncryptedInfer(const char *model_path, const std::string dec_key_str,
const std::string crypto_lib_path) {
// Set Context
auto context = std::make_shared<mindspore::Context>();
auto &device_list = context->MutableDeviceInfo();
auto device_info = std::make_shared<mindspore::CPUDeviceInfo>();
device_list.push_back(device_info);
// Create model
auto model = new (std::nothrow) mindspore::Model();
// Set Decrypt Parameters
mindspore::Key dec_key;
std::string dec_mode = "AES-GCM";
dec_key.len = Hex2ByteArray(dec_key_str, dec_key.key, kEncMaxLen);
// Build model
auto build_ret = model->Build(model_path, mindspore::kMindIR, context, dec_key, dec_mode, crypto_lib_path);
if (build_ret != mindspore::kSuccess) {
delete model;
std::cerr << "Build model error " << build_ret << std::endl;
return -1;
}
// Predict
auto inputs = model->GetInputs();
auto outputs = model->GetOutputs();
auto predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
delete model;
std::cerr << "Predict error " << predict_ret << std::endl;
return -1;
}
// Delete model.
delete model;
return 0;
If the command for using the converter_lite is:
./converter_lite --fmk=MINDIR --modelFile=./lenet.mindir --outputFile=lenet_enc --encryptKey=30313233343536373839414243444546 --encryption=true
Compile the source code in the mindspore/lite/examples/runtime_cpp directory, and generate build/runtime_cpp:
cd mindspore/lite/examples/runtime_cpp
bash build.sh
cd build
Run Mindspore Lite inference on the encrypted model file:
./runtime_cpp --modelFile=./lenet_enc.ms 6 30313233343536373839414243444546 ${your_openssl_path}
Viewing Logs
If an exception occurs during inference, you can view logs to locate the fault. For the Android platform, use the Logcat command line to view the MindSpore Lite inference log information and use MS_LITE to filter the log information.
logcat -s "MS_LITE"
For the iOS platform, does not support viewing logs temporarily.
Obtaining the Version Number
MindSpore Lite provides the Version method to obtain the version number, which is included in the include/api/types.h header file. You can call this method to obtain the version number of MindSpore Lite.
The following sample code from main.cc demonstrates how to obtain the version number of MindSpore Lite:
#include "include/api/types.h"
std::string version = mindspore::Version();
Extension Usage
In this chapter, we will show the users an example of extending MindSpore Lite inference, covering the whole process of creation and registration of custom operator. The example will help the users understand the extension usage as soon as possible. The chapter takes a simple model that consists of a single operator Add as an example. The code related to the example can be obtained from the directory mindspore/lite/examples/runtime_extend.
The chapter only provides instruction in the Linux System.
Operator InferShape Extension
The users need to inherit the basic class KernelInterface, and override the interface function Infer.
Status CheckInputs(const std::vector<mindspore::MSTensor> &inputs) { // check function when compiling, to judge the shape of input tensor is valid or not
for (auto &input : inputs) {
auto input_shape = input.Shape();
if (std::find(input_shape.begin(), input_shape.end(), -1) != input_shape.end()) {
return kLiteInferInvalid;
}
}
return kSuccess;
}
class CustomAddInfer : public kernel::KernelInterface {
public:
CustomAddInfer() = default;
~CustomAddInfer() = default;
Status Infer(std::vector<mindspore::MSTensor> *inputs, std::vector<mindspore::MSTensor> *outputs,
const schema::Primitive *primitive) override { // override interface
(*outputs)[0].SetFormat((*inputs)[0].format());
(*outputs)[0].SetDataType((*inputs)[0].DataType());
auto ret = CheckInputs(inputs);
if (ret == kLiteInferInvalid) {
(*outputs)[0].SetShape({-1}); // set the shape as {-1},which represents the inferring process will be called again when running
return kLiteInferInvalid;
} else if (ret != kSuccess) {
return kLiteError;
}
(*outputs)[0].SetShape((*inputs)[0].Shape());
return kSuccess;
}
};
std::shared_ptr<kernel::KernelInterface> CustomAddInferCreator() { return std::make_shared<CustomAddInfer>(); }
REGISTER_CUSTOM_KERNEL_INTERFACE(CustomOpTutorial, Custom_Add, CustomAddInferCreator) // call the registration interface
The process of inferring shape is composed of two periods, one is static inference when compiling graph, and the other is dynamic inference when running.
Static inference:
If the called function
CheckInputsreturns false or the current node needs to be inferred in the period of running, the shape of output tensor should be set as {-1}, which will be viewed as an identification to infer again when running. In such situation, the return code needs to be set tokLiteInferInvalid.In other situation, please return other code. If the code is not
kSuccess, the program will be aborted and please check the program accordingly.Dynamic inference
In this period, whether the dynamic inference is needed is up to the shape of output tensor of current node. Please refer to the
Operator Extensionas follows.
Operator Extension
The users need to inherit the basic class Kernel, and override the related interface.
Prepare: The interface will be called during graph compilation. Users can make preparations or necessary verifications for the current node before running.
Execute:The interface is running interface. Users can call dynamic inference PreProcess in this interface.
Status CheckOutputs(const std::vector<mindspore::MSTensor> &outputs) { // Check function when running, to judge whether the shape inference is needed for (auto &output : outputs) { auto output_shape = output.Shape(); if (std::find(output_shape.begin(), output_shape.end(), -1) != output_shape.end()) { return kLiteInferInvalid; } } return kSuccess; }
ReSize: The interface is used to handle the changeable information of the current node due to the shape change of graph inputs.
Attribute Parsing: The users need to provide their own parsing of custom operator, which can refer to ParseAttrData.
Operator registration. The users can refer to the interface REGISTER_CUSTOM_KERNEL.
const auto kFloat32 = DataType::kNumberTypeFloat32; std::shared_ptr<Kernel> CustomAddCreator(const std::vector<mindspore::MSTensor> &inputs, const std::vector<mindspore::MSTensor> &outputs, const schema::Primitive *primitive, const mindspore::Context *ctx) { return std::make_shared<CustomAddKernel>(inputs, outputs, primitive, ctx); } REGISTER_CUSTOM_KERNEL(CPU, CustomOpTutorial, kFloat32, Custom_Add, CustomAddCreator)
Example
Compile
Environment Requirements
Compilation and Build
Execute the script build.sh in the directory of
mindspore/lite/examples/runtime_extend, And then, the released package of MindSpore Lite will be downloaded and the demo will be compiled automatically.bash build.shIf the automatic download is failed, users can download the specified package manually. The hardware platform is CPU and the system is Ubuntu-x64 mindspore-lite-{version}-linux-x64.tar.gz. After unzipping, please copy the dynamic library
libmindspore-lite.soin the directory ofruntime/libto the directory ofmindspore/lite/examples/runtime_extend/liband copy the directory ofruntime/includeto the directory ofmindspore/lite/examples/runtime_extend.If the model
add_extend.msis failed to download, please download add_extend.ms manually, and copy to the directory ofmindspore/lite/examples/runtime_extend/model.After manually downloading and storing the specified file, users need to execute the
build.shscript to complete the compilation and build process.Compilation Result
The executable program
runtime_extend_tutorialwill be generated in the directory ofmindspore/lite/examples/runtime_extend/build.
Execute Program
After compiling and building, please enter the directory of
mindspore/lite/examples/runtime_extend/build, and then execute the following command to experience the extension usaged../runtime_extend_tutorial ../model/add_extend.msAfter the execution, the following information is displayed, including the tensor name, tensor size, number of output tensors, and the first 20 pieces of data.
tensor name is:add-0 tensor size is:400 tensor elements num is:100 output data is:2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2