MindSpore Lite云侧推理文档
MindSpore Lite推理包含云侧推理和端侧推理两部分,该文档主要介绍MindSpore Lite云侧推理,端侧推理请参考 端侧推理文档 。
使用场景
MindSpore Lite云侧推理主要用于服务侧设备的推理,可以兼容MindSpore训练框架导出的模型结构,以及开源ONNX、TFLite、Pb等多种不同格式的模型结构。主要适用于Atlas 300I Duo、Atlas 800I A2、Atlas 800I A3等系列昇腾卡,以及X86/Arm架构的CPU硬件。MindSpore Lite针对不同的算法场景也做了针对性的优化适配,当前MindSpore Lite特性功能与优化主要集中在多模态生成、语音识别、语音合成、自动驾驶、向量模型、传统CV等领域。
优势
MindSpore Lite在模型推理过程中,通过整图下沉的方式,有效地降低了算子下发时延,从而提升模型推理性能;
针对多模态生成类算法模型,MindSpore Lite支持多种Cache缓存方式、量化、显存共享、多维度混合并行等关键特性能力。针对昇腾硬件,MindSpore Lite支持用户自定义算子接入能力;
针对语音类算法模型,MindSpore Lite支持IO数据免拷贝等关键特性能力;
针对自动驾驶领域模型,在昇腾硬件上推理时,MindSpore Lite支持单算子与子图的混合调度,保证了子图下沉的推理性能,同时可以通过混合调度实现自动驾驶类的自定义算子快速接入。
开发流程
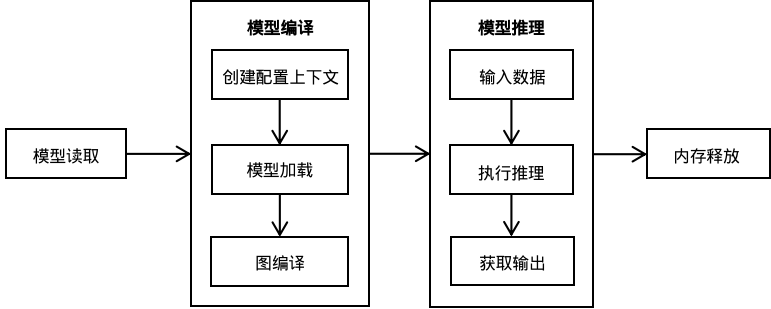
使用MindSpore Lite推理框架主要包括以下步骤:
模型读取:可以直接加载MindSpore训练导出的MindIR模型,或者通过MindSpore Lite转换工具将第三方框架导出的模型格式转换为MindIR模型,并通过MindSpore Lite的接口进行模型加载。
模型编译:
创建配置上下文:通过创建
Context,保存需要的一些基本配置参数,用于指导图编译和模型执行。模型加载:执行推理之前,需要调用
Model的Build接口进行模型加载,会将文件缓存解析成运行时的模型。图编译:模型加载完成后,MindSpore Lite运行时会对图进行编译,模型编译阶段会耗费较多时间,所以建议Model创建一次,编译一次,多次推理。
模型推理:
模型执行之前需要填充输入数据。
执行推理:使用
Model的Predict进行模型推理。获取输出:
Predict接口中的outputs出参为推理结果的返回值,可以通过对MSTensor对象的解析获取模型的推理结果以及输出的数据类型和大小。
内存释放:在模型编译阶段会申请常驻内存、显存、线程池等资源,需要在模型推理结束后进行释放,从而避免资源泄漏。