MindSpore Golden Stick
MindSpore Golden Stick is a model compression algorithm tool, which reduces computing power, memory, and power consumption during AI deployment and enables AI deployment in all scenarios.
MindSpore Golden jointly designed and developed by Huawei’s Noah team and Huawei’s MindSpore team. The architecture diagram is shown in the figure below, which is divided into five parts:

The underlying MindSpore Rewrite module provides the ability to modify the front-end network. Based on the interface provided by this module, algorithm developers can add, delete, query and modify the nodes and topology relationships of the MindSpore front-end network according to specific rules;
Based on MindSpore Rewrite, MindSpore Golden Stick will provide various types of algorithms, such as SimQAT algorithm, SLB quantization algorithm, SCOP pruning algorithm, etc.;
At the upper level of the algorithm, MindSpore Golden Stick also plans advanced technologies such as AMC (AutoML for Model Compression), NAS (Neural Architecture Search), and HAQ (Hardware-aware Automated Quantization);
In order to facilitate developers to analyze and debug algorithms, MindSpore Golden Stick provides some tools, such as visualization tool, profiler tool, summary tool, etc.;
In the outermost layer, MindSpore Golden Stick encapsulates a set of concise user interface.
Note
The architecture diagram is the overall picture of MindSpore Golden Stick, which includes the features that have been implemented in the current version and the capabilities planned in RoadMap. Please refer to release notes for available features in current version.
Design Guidelines
In addition to providing rich model compression algorithms, an important design concept of MindSpore Golden Stick is try to provide users with the most unified and concise experience for a wide variety of model compression algorithms in the industry, and reduce the cost of algorithm application for users. MindSpore Golden Stick implements this philosophy through two initiatives:
Unified algorithm interface design to reduce user application costs:
There are many types of model compression algorithms, such as quantization-aware training algorithms, pruning algorithms, matrix decomposition algorithms, knowledge distillation algorithms, etc. In each type of compression algorithm, there are also various specific algorithms, such as LSQ and PACT, which are both quantization-aware training algorithms. Different algorithms are often applied in different ways, which increases the learning cost for users to apply algorithms. MindSpore Golden Stick sorts out and abstracts the algorithm application process, and provides a set of unified algorithm application interfaces to minimize the learning cost of algorithm application. At the same time, this also facilitates the exploration of advanced technologies such as AMC, NAS, and HAQ based on the algorithm ecology.
Provide front-end network modification capabilities to reduce algorithm development costs:
Model compression algorithms are often designed or optimized for specific network structures. For example, perceptual quantization algorithms often insert fake-quantization nodes on the Conv2d, Conv2d + BatchNorm2d, or Conv2d + BatchNorm2d + Relu structures in the network. MindSpore Golden Stick provides the ability to modify the front-end network through API. Based on this ability, algorithm developers can formulate general network transform rules to implement the algorithm logic without needing to implement the algorithm logic for each specific network. In addition, MindSpore Golden Stick also provides some debugging capabilities, including network dump, level-wise profiling, algorithm effect analysis and visualization tool, aiming to help algorithm developers improve development and research efficiency, and help users find algorithms that meet their needs.
General Process of Applying the MindSpore Golden Stick
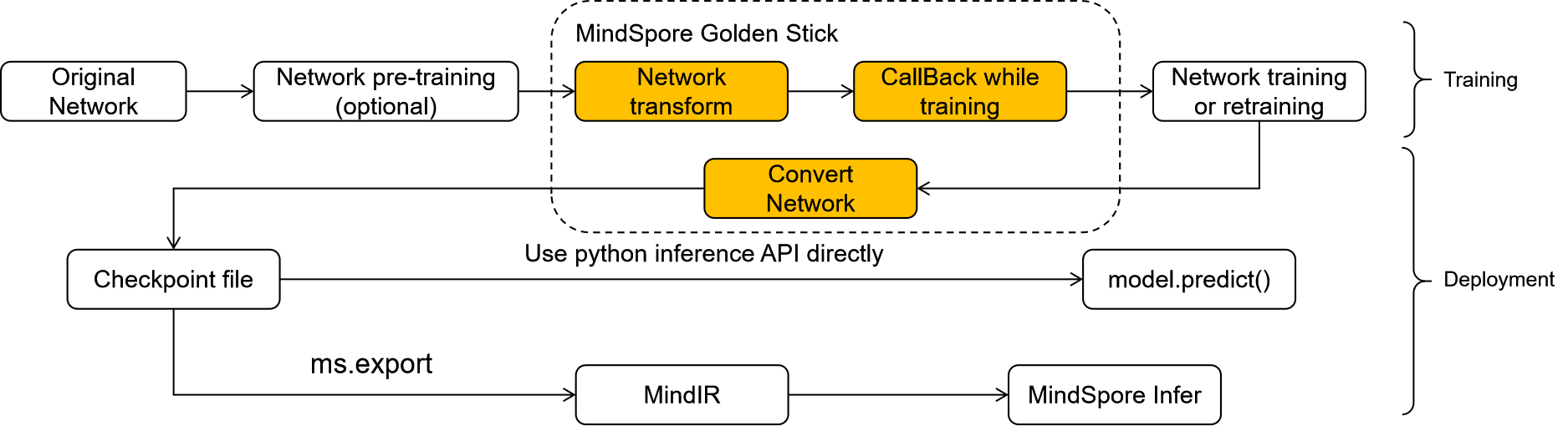
Training
During network training, the MindSpore Golden Stick does not have great impact on the original training script logic. As shown in the highlighted part in the preceding figure, only the following two steps need to be added:
Optimize the network using the MindSpore Golden Stick: In the original training process, after the original network is defined and before the network is trained, use the MindSpore Golden Stick to optimize the network structure. Generally, this step is implemented by calling the apply API of MindSpore Golden Stick. For details, see Applying the SimQAT Algorithm .
Register the MindSpore Golden Stick callback: Register the callback of the MindSpore Golden Stick into the model to be trained. Generally, in this step, the callback function of MindSpore Golden Stick is called to obtain the corresponding callback object and register the object into the model .
Deployment
Network conversion: A network compressed by MindSpore Golden Stick may require additional steps to convert the model compression structure from training mode to deployment mode, facilitating model export and deployment. For example, in the quantization aware scenario, a fake quantization node in a network usually needs to be eliminated, and converted into an operator attribute in the network.
Note
For details about how to apply the MindSpore Golden Stick, see the detailed description and sample code in each algorithm section.
For details about the “ms.export” step in the process, see Exporting MINDIR Model .
For details about the “MindSpore infer” step in the process, see MindSpore Inference Runtime .
Roadmap
The current release version of MindSpore Golden Stick provides a stable API and provides a linear quantization algorithm, a nonlinear quantization algorithm and a structured pruning algorithm. More algorithms and better network support will be provided in the future version, and debugging capabilities will also be provided in subsequent versions. With the enrichment of algorithms in the future, MindSpore Golden Stick will also explore capabilities such as AMC, HAQ, NAS, etc., so stay tuned.
Installation and Deployment
Quantization Algorithms
Pruning Algorithms
Model Deployment
API References
RELEASE NOTES