Vertical Federated Learning Data Access
![]()
Unlike horizontal federated learning, two participants (leader and follower) have the same sample space for training or inference in vertical federated learning. Therefore, the data intersection must be done collaboratively before both parties in vertical federated learning initiate training or inference. Both parties must read their respective original data and extract the ID (unique identifier of each data, and none of them is the same) corresponding to each data for intersection (i.e., finding the intersection). Then, both parties obtain features or tags from the original data based on the intersected IDs. Finally, each side exports the persistence file and reads the data in the reordering manner before subsequent training or inference.
Overall Process
Data access can be divided into two parts: data export and data read.
Exporting Data
The MindSpore Federated vertical federated learning data export process framework is shown in Figure 1:
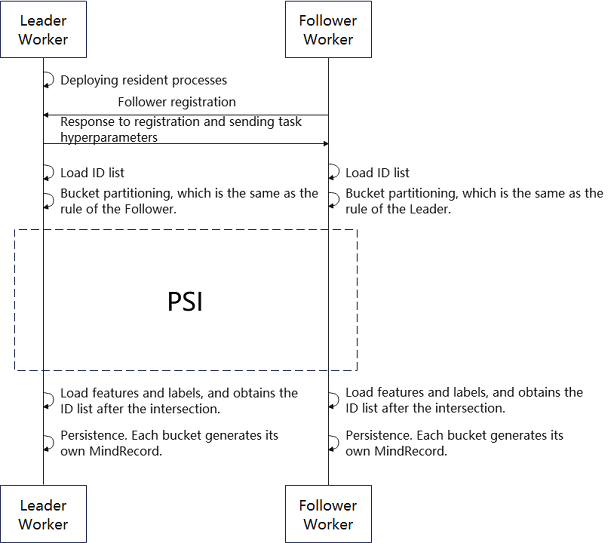
Fig. 1 Vertical Federated Learning Data Export Process Framework Diagram
In the data export process, Leader Worker and Follower Worker are the two participants in the vertical federated learning. The Leader Worker is resident and keeps a listening ear on the Follower Worker, who can enter the data access process at any moment.
After the Leader Worker receives a registration request from the Follower Worker, it checks the registration content. If the registration is successful, the task-related hyperparameters (PSI-related hyperparameters, bucketing rules, ID field names, etc.) are sent to the Follower Worker.
The Leader Worker and Follower Worker read their respective raw data, extract the list of IDs from their raw data and implement bucketing.
Each bucket of Leader Worker and Follower Worker initiates the privacy intersection method to obtain the ID intersections of the two parties.
Finally, the two parties extract the corresponding data from the original data based on the ID intersections and export it to a file in MindRecord format.
Reading Data
Vertical federated requires that both participants have the same value and order of data IDs for each batch of training or inference. MindSpore Federated ensures that the data is read in the same order by using the same random seed and by using dictionary sorting on the exported file sets when both parties read their respective data.
An Example for Quick Experience
Sample Data Preparation
To use the data access method, the original data needs to be prepared first. The user can use random data generation script to generate forged data for each participant as a sample.
python generate_random_data.py \
--seed=0 \
--total_output_path=vfl/input/total_data.csv \
--intersection_output_path=vfl/input/intersection_data.csv \
--leader_output_path=vfl/input/leader_data_*.csv \
--follower_output_path=vfl/input/follower_data_*.csv \
--leader_file_num=4 \
--follower_file_num=2 \
--leader_data_num=300 \
--follower_data_num=200 \
--overlap_num=100 \
--id_len=20 \
--feature_num=30
The user can set the hyperparameter according to the actual situation:
Hyperparameter names |
Hyperparameter description |
|---|---|
seed |
Random seed, int type. |
total_output_path |
The output path of all data, str type. |
intersection_output_path |
The output path of intersection data, str type. |
leader_output_path |
The export path of the leader data. If the configuration includes the |
follower_output_path |
The export path of the follower data. If the configuration includes the |
leader_file_num |
The number of output files for leader data. int type. |
follower_file_num |
The number of output files for follower data. int type. |
leader_data_num |
The total number of leader data. int type. |
follower_data_num |
The total number of follower data. int type. |
overlap_num |
The total amount of data that overlaps between leader and follower data. int type. |
id_len |
The data ID is a string type. The hyperparameter is the length of the string. int type. |
feature_num |
The number of columns of the exported data |
Multiple csv files are generated after running the data preparation:
follower_data_0.csv
follower_data_1.csv
intersection_data.csv
leader_data_0.csv
leader_data_1.csv
leader_data_2.csv
leader_data_3.csv
Sample of Data Export
Users can use script of finding data intersections to implement data intersections between two parties and export it to MindRecord format file. The users need to start Leader and Follower processes separately.
Start Leader:
python run_data_join.py \
--role="leader" \
--main_table_files="vfl/input/leader/" \
--output_dir="vfl/output/leader/" \
--data_schema_path="vfl/leader_schema.yaml" \
--server_name=leader_node \
--http_server_address="127.0.0.1:1086" \
--remote_server_name=follower_node \
--remote_server_address="127.0.0.1:1087" \
--primary_key="oaid" \
--bucket_num=5 \
--store_type="csv" \
--shard_num=1 \
--join_type="psi" \
--thread_num=0
Start Follower:
python run_data_join.py \
--role="follower" \
--main_table_files="vfl/input/follower/" \
--output_dir="vfl/output/follower/" \
--data_schema_path="vfl/follower_schema.yaml" \
--server_name=follower_node \
--http_server_address="127.0.0.1:1087" \
--remote_server_name=leader_node \
--remote_server_address="127.0.0.1:1086" \
--store_type="csv" \
--thread_num=0
The user can set the hyperparameter according to the actual situation.
Hyperparameter names |
Hyperparameter description |
|---|---|
role |
Role types of the worker. str type. Including: “leader”, “follower”. |
main_table_files |
The path of raw data, configure either single or multiple file paths, data directory paths, list or str types |
output_dir |
The directory path of the exported MindRecord related files, str type. |
data_schema_path |
The path of the super reference file to be configured during export, str type. |
server_name |
Name of local http server that used for communication, str type. |
http_server_address |
Local IP and port address, str type. |
remote_server_name |
Name of remote http server that used for communication, str type. |
remote_server_address |
Peer IP and port address, str type. |
primary_key (Follower does not need to be configured) |
The name of data ID, str type. |
bucket_num (Follower does not need to be configured) |
Find the number of sub-buckets when intersecting and exporting, int type. |
store_type |
Raw data storage type, str type. Including: “csv”. |
shard_num (Follower does not need to be configured) |
The number of files exported from a single bucket, int type. |
join_type (Follower does not need to be configured) |
Algorithm of intersection finding, str type. Including: “psi”. |
thread_num |
Calculate the number of threads required when using the PSI intersection algorithm, int type. |
In the above sample, the files corresponding data_schema_path can be referred to the corresponding files configuration of leader_schema.yaml and follower_schema.yaml. The user needs to provide the column names and types of the data to be exported in this file.
After running the data export, generate multiple MindRecord related files.
mindrecord_0
mindrecord_0.db
mindrecord_1
mindrecord_1.db
mindrecord_2
mindrecord_2.db
mindrecord_3
mindrecord_3.db
mindrecord_4
mindrecord_4.db
Sample of Data Reading
The user can use the script of reading data to implement data reading after intersection.
python load_joined_data.py \
--seed=0 \
--input_dir=vfl/output/leader/ \
--shuffle=True
The user can set the hyperparameter according to the actual situation.
Hyperparameter names |
Hyperparameter description |
|---|---|
seed |
Random seed. int type. |
input_dir |
The directory of the input MindRecord related files, str type. |
shuffle |
Whether the data order needs to be changed, bool type. |
If the intersection result is correct, when each of the two parties reads the data, the OAID order of each data of the two parties is the same, while the data of the other columns in each data can be different values. Print the intersection data after running the data read:
Leader data export results:
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'uMbgxIMMwWhMGrVMVtM7')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'IwoGP08kWVtT4WHL2PLu')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'MSRe6mURtxgyEgWzDn0b')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'y7X0WcMKnTLrhxVcWfGF')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'DicKRIVvbOYSiv63TvcL')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'TCHgtynOhH3z11QYemsH')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'OWmhgIfC3k8UTteGUhni')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'NTV3qEYXBHqKBWyHGc7s')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'wuinSeN1bzYgXy4XmSlR')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'SSsCU0Pb46XGzUIa3Erg')}
……
Follower data export results:
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'uMbgxIMMwWhMGrVMVtM7')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'IwoGP08kWVtT4WHL2PLu')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'MSRe6mURtxgyEgWzDn0b')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'y7X0WcMKnTLrhxVcWfGF')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'DicKRIVvbOYSiv63TvcL')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'TCHgtynOhH3z11QYemsH')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'OWmhgIfC3k8UTteGUhni')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'NTV3qEYXBHqKBWyHGc7s')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'wuinSeN1bzYgXy4XmSlR')}
{……, 'oaid': Tensor(shape=[], dtype=String, value= 'SSsCU0Pb46XGzUIa3Erg')}
……
An Example for Deep Experience
For detailed API documentation for the following code, see Data Access Documentation.
Data Export
The user can implement data join and MindRecord related files export by using the encapsulated interface and yaml file in the following way:
from mindspore_federated import FLDataWorker
from mindspore_federated.common.config import get_config
if __name__ == '__main__':
current_dir = os.path.dirname(os.path.abspath(__file__))
args = get_config(os.path.join(current_dir, "vfl/vfl_data_join_config.yaml"))
dict_cfg = args.__dict__
worker = FLDataWorker(config=dict_cfg)
worker.do_worker()
Data Reading
The user can implement data in exported MindRecord related files reading by using the encapsulated interface in the following way:
from mindspore_federated.data_join import load_mindrecord
if __name__ == "__main__":
dataset = load_mindrecord(input_dir="vfl/output/leader/", shuffle=True, seed=0)