Horizontal FL-Local Differential Privacy SignDS training
![]()
Privacy Protection Background
Federated learning enables the client user to participate in global model training without uploading the original dataset by allowing the participant to upload only the new model after local training or update the update information of the model, breaking through the data silos. This common scenario of federated learning corresponds to the default scheme in the MindSpore federated learning framework, where the encrypt_train_type switch defaults to not_encrypt when starting the server. The installation and deployment and application practices in the federated learning tutorial both use this approach by default, which is a common federated seeking averaging scheme without any privacy-protecting treatment such as cryptographic perturbation. For the convenience of description, `not_encrypt’ is used below to refer specifically to this default scheme.
This federated learning scheme is not free from privacy leakage, using the above not_encrypt scheme for training. The Server receives the local training model uploaded by the Client, which can still reconstruct the user training data through some attack methods [1], thus leaking user privacy, so the not_encrypt scheme needs to further increase the user privacy protection mechanism.
The global model oldModel received by the Client in each round of federated learning is issued by the Server, which does not involve user privacy issues. However, the local model newModel obtained by each Client after several epochs of local training fits its local privacy data, so the privacy protection focuses on the weight difference between the two newModel-oldModel=update.
The DP_ENCRYPT differential noise scheme already implemented in the MindSpore Federated framework achieves privacy preservation by iteratively perturbing Gaussian random noise to update. However, as the dimensionality of the model increases, the increase in the update paradigm will increase the noise, thus requiring more Clients to participate in the same round of aggregation to neutralize the noise impact, otherwise the convergence and accuracy of the model will be reduced. If the noise is set too small, although the convergence and accuracy are close to the performance of the not_encrypt scheme, the privacy protection is not strong enough. Also each Client needs to send the perturbed model, and as the model increases, the communication overhead increases. We expect the Client represented by the cell phone to achieve convergence of the global model with as little communication overhead as possible.
Algorithm Flow Introduction
SignDS [2] is the abbreviation of Sign Dimension Select, and the processing object is the update of Client. Preparation: each layer of Tensor of update is flattened and expanded into a one-dimensional vector, connected together, and the number of splicing vector dimensions is noted as \(d\).
One sentence summarizes the algorithm: Each participant only uploads information about the important dimensions, including their gradient directions and privacy-preserving steps, which corresponds to the SignDS and MagRR (Magnitude Random Response) modules in the figure below, respectively.

Here is an example: there are 3 clients Client1, 2, 3, whose update is a \(d=8\)-dimensional vector after flattening and expanding, and the Server calculates the avg of these 3 clients Client and updates the global model with the value, that is, completes a round of federated learning.
Client |
d_1 |
d_2 |
d_3 |
d_4 |
d_5 |
d_6 |
d_7 |
d_8 |
|---|---|---|---|---|---|---|---|---|
1 |
0.4 |
0.1 |
-0.2 |
0.3 |
0.5 |
0.1 |
-0.2 |
-0.3 |
2 |
0.5 |
0.2 |
0 |
0.1 |
0.3 |
0.2 |
-0.1 |
-0.2 |
3 |
0.3 |
0.1 |
-0.1 |
0.5 |
0.2 |
0.3 |
0 |
0.1 |
avg |
0.4 |
0.13 |
-0.1 |
0.3 |
0.33 |
0.2 |
-0.1 |
-0.13 |
SignDS
The dimension with higher importance should be selected, and the importance measure is the size of the fetching value, and the update needs to be sorted. update takes positive and negative values to represent different update directions, so in each round of federated learning, the sign values of Client each have 0.5 probability of taking 1 or -1. If sign=1, the largest \(k\) number of update dimensions are noted as the topk set and the remaining ones are noted as the non-topk set. If sign=-1, the smallest \(k\) number of ones are noted as the topk set.
If the Server specifies h, the total number of selected dimensions, the Client will directly use this value, otherwise each Client will locally calculate the optimal output dimension h.
The SignDS algorithm outputs the number of dimensions (denoted as \(v\)) that should be selected from the topk set and the non-topk set, as in the example in the table below, where the two sets pick a total of dimensions h=3.
Client selects dimensions uniformly and randomly according to the number of dimensions output by the SignDS algorithm, sends the dimension number and sign value to the Server. If the dimension number is output in the order of picking from topk first and then from non-topk, the dimension number list index needs to be shuffled and disordered. The following table shows the part of information finally transferred from each Client of this algorithm to the Server.
Client |
index |
sign |
|---|---|---|
1 |
1,5,8 |
1 |
2 |
2,3,4 |
-1 |
3 |
3,6,7 |
1 |
MagRR
The Server receives the dimension direction from the client, but it is not clear what the step size to update in that direction is. Generally speaking, the step length tends to be large at the beginning of training, and shrinks as the training gradually converges. The general trend of step length change is shown in the following figure:

The Server wants to estimate a dynamic range \([0,2∗r_{est}]\) for the actual step \(r\), and thus compute the global learning rate \(lr_{global}=2∗r_{est}*num_{clients}\).
The \(r\) adjustment uses a similar dichotomous idea. The specific process is as follows:
The server initializes a smaller \(r_{est}\) before the start of training (which does not affect the direction of model convergence too much);
After each round of local training, the participant calculates the true magnitude \(r\) (mean of topk dimensions) and converts \(r\) to \(b\) with certain rules based on the current \(r_{est}\) issued from the cloud side;
The participant performs local differential Binary Randomized Response (BRR) perturbation on \(b\) and upload the results.
The whole training process is divided into two phases, namely the fast growth phase and the contraction phase. The rules for \(r \rightarrow b\) conversions and server-side updates of \(r_{est}\) are slightly different for the participant in the two phases:
In the fast growth phase, a smaller \(r_{est}\) is chosen, such as \(e^{-5}\). At this point, \(r_{est}\) is expanded by a certain multiple. Therefore, we can define:
\[\begin{split} b = \begin{cases} 0 & r \in [2*r_{est}, \infty] \\ 1 & r \in [0,2*r_{est})] \end{cases} \end{split}\]The server aggregates all device-side random response results for frequency statistics and calculates the plurality \(B\). If \(B=0\), it is considered that \(r_{est}\) has not reached the range of 𝑟 at present and needs to continue increasing \(r_{est}\); If \(B=1\), \(r_{est}\) is considered to have reached the range of 𝑟, and keep \(r_{est}\) unchanged.
In the contraction phase, it is necessary to fine-tune \(r_{est}\) according to the changes in \(r\). Therefore we can define:
\[\begin{split} b = \begin{cases} 0 & r \in [r_{est}, \infty] \\ 1 & r \in [0,r_{est})] \end{cases} \end{split}\]Calculate \(B\), and if \(B=0\) , consider that \(r_{est}\) and \(r\) are currently closer and keep \(r_{est}\) unchanged; If \(B=1\), \(r\) is considered to be generally smaller than \(r_{est}\), and \(r_{est}\) is halved.
The Server constructs update with privacy protection based on the dimension serial number, sign value and \(r_{est}\) uploaded by each Client, and aggregates and averages all update and updates the current oldModel to complete one round of federated learning. The following table shows the aggregation when \(2∗r_{est}*num_{clients}=1\).
Client |
d_1 |
d_2 |
d_3 |
d_4 |
d_5 |
d_6 |
d_7 |
d_8 |
|---|---|---|---|---|---|---|---|---|
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
2 |
0 |
-1 |
-1 |
-1 |
0 |
0 |
0 |
0 |
3 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
avg |
1/3 |
-1/3 |
0 |
-1/3 |
1/3 |
1/3 |
1/3 |
1/3 |
The SignDS scheme enables the device-side client to upload only a list of dimensional ordinal numbers of type int output by the algorithm, a random Sign value of type boolean and feedback results on the estimated value to the cloud side, which significantly reduces the communication overhead compared to uploading tens of thousands of float-level complete model weights or gradients in a common scenario. From the perspective of the actual reconstruction attack, the cloud side only obtains the dimension serial number, a Sign value representing the direction of gradient update and the step estimation feedback value for privacy protection, and the attack is more difficult to achieve. The data flow fields of the overall scheme are shown in the following figure:

Privacy Protection Certificate
The differential privacy noise scheme achieves privacy protection by adding noise so that the attacker cannot determine the original information, while the differential privacy SignDS scheme activates partial dimensions and replaces the original value with the sign value, which largely protects user privacy. Further, using the differential privacy index mechanism makes it impossible for an attacker to confirm whether the activated dimensions are significant (from the topk set) and whether the number of dimensions from topk in the output dimensions exceeds a given threshold.
Dimensional Selection Mechanism Based on Index Mechanism
For any two updates \(\Delta\) and \(\Delta'\) of each Client, the set of topk dimensions is \(S_{topk}\) , \({S'}_{topk}\) , respectively. The set of any possible output dimensions of the algorithm is \({J}\in {\mathcal{J}}\) . Note that \(\nu=|{S}_ {topk}\cap {J}|\) , \(\nu'=|{S'}_{topk}\cap {J}|\) is the number of intersections of \({J}\) and topk sets, and the algorithm such that the following inequality holds:
It is proved that the algorithm satisfies local differential privacy.
Local Differential Privacy-Random Response Mechanism
The participant receives the estimate sent from the server, and after the local training is completed, the topk dimensional weight mean of the real update is calculated, and 0 or 1 is output according to the magRR strategy. We consider that 0 or 1 still carries the weight mean range information, and it needs further protection.
The input of the random response mechanism is the data to be protected (\(\b\in \{0,1\}\)) and the privacy parameter \(\epsilon\), which flips the data according to a certain probability and outputs \(\hat{b} \in \{0,1\}\) with the following rules:
where \(P=\frac{e^\epsilon}{1+e^\epsilon}\).
Frequency Statistics Based on Random Response Mechanism
It is difficult for adversaries to distinguish real data from scrambled data by random responses, but it also affects the availability of cloud-side statistical tasks. The server side can approximate the true statistical frequency values by noise reduction, but it is difficult to infer the true input of the user in reverse. Let \(N\) be the total number of participants in a round, \(N^T\) be the total number of 1 originally, and \(N^C\) be the total number of 1 collected by the server, then we have:
Preparation
To use the algorithm, one first needs to successfully complete the training aggregation process for either cross-device federated scenario. Implementing an Image Classification Application of Cross-device Federated Learning (x86) describes the preparation work such as datasets, network models, and simulations to initiate the process of multi-client participation in federated learning in detail.
Algorithm Opening Script
Local differential privacy SignDS training currently only supports cross-device federated learning scenarios. The opening method needs to change the following parameter configuration in the yaml file when opening the cloud-side service. The complete cloud-side opening script can be referred to the cloud-side deployment, and the relevant parameter configuration for opening this algorithm is given here. Taking LeNet task as an example, the yaml related configuration is as follows:
encrypt:
encrypt_train_type: SIGNDS
...
signds:
sign_k: 0.2
sign_eps: 100
sign_thr_ratio: 0.6
sign_global_lr: 0.1
sign_dim_out: 0
For the detailed example, refer to Implementing an Image Classification Application of Cross-device Federated Learning (x86). The cloud-side code implementation gives the definition domain of each parameter. If it is not in the definition domain, Server will report an error prompting the definition domain. The following parameter changes are subject to keeping the remaining 4 parameters unchanged.
sign_k: (0,0.25], k*inputDim>50. default=0.01.inputDimis the pulling length of the model or update. If not satisfied, there is a device-side warning. Sort update, and thetopkset is composed of the first k (%) of it. Decreasing k means to pick from more important dimensions with greater probability. The output will have fewer dimensions, but the dimensions are more important and the change in convergence cannot be determined. The user needs to observe the sparsity of model update to determine the value. When it is quite sparse (update has many zeros), it should be taken smaller.sign_eps: (0,100], default=100. Privacy-preserving budget. The number sequence symbol is \(\epsilon\), abbreviated as eps. When eps decreases, the probability of picking unimportant dimensions increases. When privacy protection is enhanced, output dimensions decrease, the percentage remains the same, and precision decreases.sign_thr_ratio: [0.5,1], default=0.6. The dimension fromtopkin the activation dimension is occupied threshold lower bound. Increasing will reduce the output dimension, but the proportion of output dimensions fromtopkwill increase. When the value is increased excessively, more fromtopkis required in the output, and the total output dimension can only be reduced to meet the requirement, and the accuracy decreases when the number of clients is not large enough.sign_global_lr: (0,), default=1. This value is multiplied by sign instead of update, which directly affects the convergence speed and accuracy. Moderately increasing this value will improve the convergence speed, but it may make the model oscillate and the gradient explode. If more epochs are run locally per client and the learning rate used for local training is increased, the value needs to be increased accordingly. If the number of clients involved in the aggregation increases, the value also needs to be increased, because the value needs to be aggregated and then divided by the number of users when reconstruction. The result will remain the same only if the value is increased. If the percentage of participants in the new version (r0.2) involved in aggregation is less than 5%, the \(lr_{global}\) of the MagRR algorithm is directly adjusted to this parameter.sign_dim_out: [0,50], default=0. If a non-zero value is given, the client side uses the value directly, increasing the value to output more dimensions, but the proportion of dimensions fromtopkwill decrease. If it is 0, the client user has to calculate the optimal output parameters. If eps is not large enough, and the value is increased, manynon-topkinsignificant dimensions will be output leading to affect the mode convergence and accuracy decrease. When eps is large enough, increasing the value will allow important dimension information of more users to leave the local area and improve the accuracy.
LeNet Experiment Results
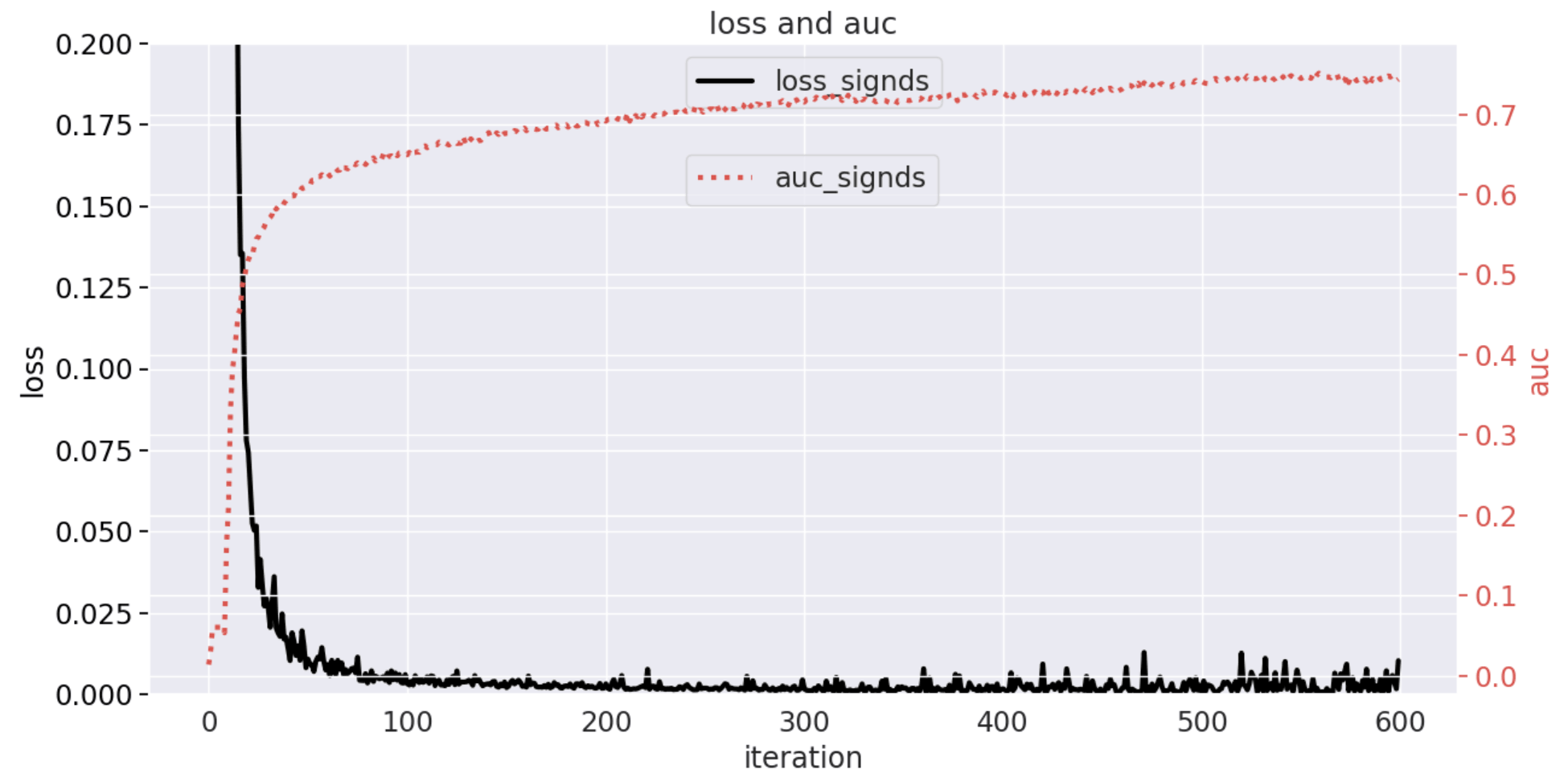
Use 100 client datasets of 3500_clients_bin, 600 iterations of federated aggregation. 20 epochs run locally per client, and using learning rate of device-side local training is 0.01. The related parameter of SignDS is k=0.2, eps=100, ratio=0.6, lr=4, out=0, and the variation curves of Loss and Auc are shown in the following figure. In the unencrypted scenario, the length of the data uploaded to the cloud side at the end of training on the device side is 266,084, but the length of the data uploaded by SignDS is only 656.
References
[1] Ligeng Zhu, Zhijian Liu, and Song Han. Deep Leakage from Gradients. NeurIPS, 2019.
[2] Xue Jiang, Xuebing Zhou, and Jens Grossklags. “SignDS-FL: Local Differentially-Private Federated Learning with Sign-based Dimension Selection.” ACM Transactions on Intelligent Systems and Technology, 2022.