单节点数据缓存
Ascend GPU CPU 数据准备
![]()
![]()
![]()
![]()
概述
对于需要重复访问远程的数据集或需要重复从磁盘中读取数据集的情况,可以使用单节点缓存算子将数据集缓存于本地内存中,以加速数据集的读取。
缓存算子依赖于在当前节点启动的缓存服务器,缓存服务器作为守护进程独立于用户的训练脚本而存在,主要用于提供缓存数据的管理,支持包括存储、查找、读取以及发生缓存未命中时对于缓存数据的写入等操作。
若用户的内存空间不足以缓存所有数据集,则用户可以配置缓存算子使其将剩余数据缓存至磁盘。
目前,缓存服务只支持单节点缓存,即客户端和服务器均在同一台机器上。该服务支持以下两类使用场景:
缓存加载好的原始数据集
用户可以在数据集加载算子中使用缓存。这将把加载完成的数据存到缓存服务器中,后续若需相同数据则可直接从中读取,避免从磁盘中重复加载。

缓存经过数据增强处理后的数据
用户也可在
map算子中使用缓存。这将允许直接缓存数据增强(如图像裁剪、缩放等)处理后的数据,避免数据增强操作重复进行,减少了不必要的计算量。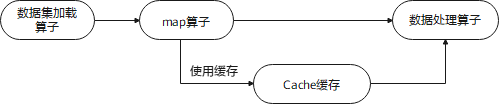
完整示例参见应用单节点数据缓存。
缓存基础使用
1.配置环境。
使用缓存服务前,需要安装MindSpore,并设置相关环境变量。以Conda环境为例,设置环境如下:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:{path_to_conda}/envs/{your_env_name}/lib/python3.7/site-packages/mindspore:{path_to_conda}/envs/{your_env_name}/lib/python3.7/site-packages/mindspore/lib
export PATH=$PATH:{path_to_conda}/envs/{your_env_name}/bin
也可以用以下python设置环境
[1]:
import os
import sys
import mindspore
python_path = "/".join(sys.executable.split("/")[:-1])
mindspore_path = "/".join(mindspore.__file__.split("/")[:-1])
mindspore_lib_path = os.path.join(mindspore_path, "lib")
if 'PATH' not in os.environ:
os.environ['PATH'] = python_path
elif python_path not in os.environ['PATH']:
os.environ['PATH'] += ":" + python_path
print(os.environ['PATH'])
os.environ['LD_LIBRARY_PATH'] = "{}:{}:{}".format(mindspore_path, mindspore_lib_path, mindspore_lib_path.split("python3.7")[0])
print(os.environ['LD_LIBRARY_PATH'])
由于使用缓存可能会造成服务器的内存紧张,因此建议用户在使用缓存前增大服务器的交换内存空间至100GB以上,Ubuntu、EulerOS以及CentOS均可参考相关教程了解如何增大交换内存空间。
2.启动缓存服务器。
在使用单节点缓存服务之前,首先需要在命令行输入以下命令,启动缓存服务器:
[2]:
!cache_admin --start
Cache server startup completed successfully!
The cache server daemon has been created as process id 14678 and listening on port 50052.
Recommendation:
Since the server is detached into its own daemon process, monitor the server logs (under /tmp/mindspore/cache/log) for any issues that may happen after startup
若输出以上信息,则表示缓存服务器启动成功。
cache_admin支持以下命令和参数:
--start:启动缓存服务器,支持通过以下参数进行配置:--workers或-w:设置缓存服务器的工作线程数量,默认情况下工作线程数量为机器CPU个数的一半。该参数需要根据NUMA架构来设置,若设置值不是机器中NUMA结点数的整数倍,则缓存服务器会对其进行自动调整。--spilldir或-s:设置若缓存数据的大小超过内存空间,则溢出至磁盘的数据文件路径,默认为空(表示不启用数据溢出功能)。--hostname或-h:缓存服务器的ip地址,默认为127.0.0.1。--port或-p:缓存服务器的端口号,默认为50052。--loglevel或-l:设置日志等级,默认为1(WARNING级别)。若设置为0(INFO级别),会输出过多日志,导致性能劣化。
--stop:关闭缓存服务器。--generate_session或-g:生成一个缓存会话。--destroy_session或-d:删除一个缓存会话。--list_sessions:查看当前缓存会话列表和详细信息。--server_info:查看当前服务器配置参数及会话列表。--help:查看帮助信息。
以上命令均可使用-h和-p参数来指定服务器,用户也可通过配置环境变量MS_CACHE_HOST和MS_CACHE_PORT来指定。若未指定则默认对ip为127.0.0.1且端口号为50052的服务器执行操作。
用户可通过ps -ef|grep cache_server命令来检查服务器是否已启动以及查询服务器参数。
用户也可通过cache_admin --server_info命令查看服务器的详细参数列表。
[3]:
!cache_admin --server_info
Cache Server Configuration:
----------------------------------------
config name value
----------------------------------------
hostname 127.0.0.1
port 50052
number of workers 8
log level 1
spill dir None
----------------------------------------
Active sessions:
No active sessions.
其中,Cache Server Configuration表格分别列出了当前服务器的IP地址、端口号、工作线程数、日志等级、溢出路径等详细配置信息。Active sessions模块展示了当前服务器中已启用的session ID列表。
缓存服务器日志文件的命名格式为 “cache_server.<主机名>.<用户名>.log.<日志等级>.<日期-时间>.<进程号>”。当GLOG_v=0时,可能会屏显有大量DEBUG日志。
若要启用数据溢出功能,则用户在启动缓存服务器时必须使用
-s参数对溢出路径进行设置,否则该功能默认关闭。
3.创建缓存会话。
若缓存服务器中不存在缓存会话,则需要创建一个缓存会话,得到缓存会话id:
[4]:
!cache_admin -g
Session created for server on port 50052: 780643335
其中780643335为端口50052的服务器分配的缓存会话id,缓存会话id由服务器分配。
通过cache_admin --list_sessions命令可以查看当前服务器中现存的所有缓存会话信息。
[5]:
!cache_admin --list_sessions
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
780643335 n/a n/a n/a n/a n/a
输出参数说明:
Session: 缓存会话id。Cache Id: 当前缓存会话中的cache实例id,n/a表示当前尚未创建缓存实例。Mem cached: 缓存在内存中的数据量。Disk cached: 缓存在磁盘中的数据量。Avg cache size:当前缓存的每行数据的平均大小。Numa hit:Numa命中数,该值越高将获得越好的时间性能。
4.创建缓存实例。
在Python训练脚本中使用DatasetCache API来定义一个名为test_cache的缓存实例,并把上一步中创建的缓存会话id传入session_id参数:
[6]:
import mindspore.dataset as ds
test_cache = ds.DatasetCache(session_id=780643335, size=0, spilling=False)
DatasetCache支持以下参数:
session_id:缓存会话的id,通过cache_admin -g命令来创建并获取。size:缓存最大内存空间占用,该参数以MB为单位,例如512GB的缓存空间应设置size=524288,默认为0。spilling:当内存空间超出所设置的最大内存空间占用时,是否允许将剩余的数据溢出至磁盘,默认为False。hostname:连接至缓存服务器的ip地址,默认为127.0.0.1。port:连接至缓存服务器的端口号,默认为50052。num_connections:建立的TCP/IP连接数,默认为12。prefetch_size:每次预取的数据行数,默认为20。
在实际使用中,通常应当首先使用
cache_admin -g命令从缓存服务器处获得一个缓存会话id并作为session_id的参数,防止发生缓存会话不存在而报错的情况。设置
size=0代表不限制缓存所使用的内存空间,缓存服务器会根据系统的内存资源状况,自动控制缓存服务器的内存空间占用,使其不超过系统总内存的80%。用户也可以根据机器本身的空闲内存大小,给
size参数设置一个合理的取值。注意,当用户自主设置size参数时,要先确认系统可用内存和待加载数据集大小,若cache_server的内存空间占用或待加载数据集空间占耗超过系统可用内存时,有可能导致机器宕机/重启、cache_server自动关闭、训练流程执行失败等问题。若设置
spilling=True,则当内存空间不足时,多余数据将写入磁盘中。因此,用户需确保所设置的磁盘路径具有写入权限以及足够的磁盘空间,以存储溢出至磁盘的缓存数据。注意,若启动服务器时未指定溢出路径,则在调用API时设置spilling=True将会导致报错。若设置
spilling=False,则缓存服务器在耗尽所设置的内存空间后将不再写入新的数据。当使用不支持随机访问的数据集(如
TFRecordDataset)进行数据加载并启用缓存服务时,需要保证整个数据集均存放于本地。在该场景下,若本地内存空间不足以存放所有数据,则必须启用溢出,将数据溢出至磁盘。
num_connections和prefetch_size为内部性能调优参数,一般情况下,用户无需设置这两个参数。
5.插入缓存实例。
当前缓存服务既支持对原始数据集的缓存,也可以用于缓存经过数据增强处理后的数据。下例分别展示了两种使用方式。
需要注意的是,两个例子均需要按照步骤4中的方法分别创建一个缓存实例,并在数据集加载或map算子中将所创建的test_cache作为cache参数分别传入。
下面两个样例中使用到CIFAR-10数据集。运行样例前,需参照数据集加载中的方法下载并存放CIFAR-10数据集。
./datasets/cifar-10-batches-bin
├── readme.html
├── test
│ └── test_batch.bin
└── train
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
└── data_batch_5.bin
[ ]:
!wget -N https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz --no-check-certificate
!mkdir -p datasets
!tar -xzf cifar-10-binary.tar.gz -C datasets
!mkdir -p datasets/cifar-10-batches-bin/train datasets/cifar-10-batches-bin/test
!mv -f datasets/cifar-10-batches-bin/test_batch.bin datasets/cifar-10-batches-bin/test
!mv -f datasets/cifar-10-batches-bin/data_batch*.bin datasets/cifar-10-batches-bin/batches.meta.txt datasets/cifar-10-batches-bin/train
缓存原始数据集加载的数据。
[8]:
dataset_dir = "./datasets/cifar-10-batches-bin/train"
# apply cache to dataset
data = ds.Cifar10Dataset(dataset_dir=dataset_dir, num_samples=4, shuffle=False, num_parallel_workers=1, cache=test_cache)
num_iter = 0
for item in data.create_dict_iterator(num_epochs=1): # each data is a dictionary
# in this example, each dictionary has a key "image"
print("{} image shape: {}".format(num_iter, item["image"].shape))
num_iter += 1
0 image shape: (32, 32, 3)
1 image shape: (32, 32, 3)
2 image shape: (32, 32, 3)
3 image shape: (32, 32, 3)
通过cache_admin --list_sessions命令可以查看当前会话有四条数据,说明数据缓存成功。
[9]:
!cache_admin --list_sessions
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
780643335 2044459912 4 n/a 3226 4
缓存经过数据增强处理后的数据。
[10]:
import mindspore.dataset.vision.c_transforms as c_vision
dataset_dir = "./datasets/cifar-10-batches-bin/train"
# apply cache to dataset
data = ds.Cifar10Dataset(dataset_dir=dataset_dir, num_samples=5, shuffle=False, num_parallel_workers=1)
# apply cache to map
rescale_op = c_vision.Rescale(1.0 / 255.0, -1.0)
test_cache = ds.DatasetCache(session_id=780643335, size=0, spilling=False)
data = data.map(input_columns=["image"], operations=rescale_op, cache=test_cache)
num_iter = 0
for item in data.create_dict_iterator(num_epochs=1): # each data is a dictionary
# in this example, each dictionary has a keys "image"
print("{} image shape: {}".format(num_iter, item["image"].shape))
num_iter += 1
0 image shape: (32, 32, 3)
1 image shape: (32, 32, 3)
2 image shape: (32, 32, 3)
3 image shape: (32, 32, 3)
4 image shape: (32, 32, 3)
通过cache_admin --list_sessions命令可以查看当前会话有五条数据,说明数据缓存成功。
[11]:
!cache_admin --list_sessions
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
780643335 112867845 5 n/a 12442 5
780643335 2044459912 4 n/a 3226 4
6.销毁缓存会话。
在训练结束后,可以选择将当前的缓存销毁并释放内存:
[12]:
!cache_admin --destroy_session 780643335
Drop session successfully for server on port 50052
以上命令将销毁端口50052服务器中缓存会话id为1456416665的缓存。
若选择不销毁缓存,则该缓存会话中的缓存数据将继续存在,用户下次启动训练脚本时可以继续使用该缓存。
7.关闭缓存服务器。
使用完毕后,可以通过以下命令关闭缓存服务器,该操作将销毁当前服务器中存在的所有缓存会话并释放内存。
[13]:
!cache_admin --stop
Cache server on port 50052 has been stopped successfully.
以上命令将关闭端口50052的服务器。
若选择不关闭服务器,则服务器中已创建的缓存会话将保留,并供下次使用。下次训练时,用户可以新建缓存会话或重复使用已有缓存。
缓存共享
对于单机多卡的分布式训练的场景,缓存算子还允许多个相同的训练脚本共享同一个缓存,共同从缓存中读写数据。
1.启动缓存服务器。
$cache_admin --start
Cache server startup completed successfully!
The cache server daemon has been created as process id 39337 and listening on port 50052
Recommendation:
Since the server is detached into its own daemon process, monitor the server logs (under /tmp/mindspore/cache/log) for any issues that may happen after startup
2.创建缓存会话。
创建启动Python训练的Shell脚本cache.sh,通过以下命令生成一个缓存会话id:
#!/bin/bash
# This shell script will launch parallel pipelines
# get path to dataset directory
if [ $# != 1 ]
then
echo "Usage: sh cache.sh DATASET_PATH"
exit 1
fi
dataset_path=$1
# generate a session id that these parallel pipelines can share
result=$(cache_admin -g 2>&1)
rc=$?
if [ $rc -ne 0 ]; then
echo "some error"
exit 1
fi
# grab the session id from the result string
session_id=$(echo $result | awk '{print $NF}')
3.将缓存会话id传入训练脚本。
继续编写Shell脚本,添加以下命令在启动Python训练时将session_id以及其他参数传入:
# make the session_id available to the python scripts
num_devices=4
for p in $(seq 0 $((${num_devices}-1))); do
python my_training_script.py --num_devices "$num_devices" --device "$p" --session_id $session_id --dataset_path $dataset_path
done
直接获取完整样例代码:cache.sh
4.创建并应用缓存实例。
下面样例中使用到CIFAR-10数据集。运行样例前,需参照数据集加载中的方法下载并存放CIFAR-10数据集。目录结构如下:
├─cache.sh
├─my_training_script.py
└─cifar-10-batches-bin
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
创建并编写Python脚本my_training_script.py,通过以下代码接收传入的session_id,并在定义缓存实例时将其作为参数传入。
import argparse
import mindspore.dataset as ds
parser = argparse.ArgumentParser(description='Cache Example')
parser.add_argument('--num_devices', type=int, default=1, help='Device num.')
parser.add_argument('--device', type=int, default=0, help='Device id.')
parser.add_argument('--session_id', type=int, default=1, help='Session id.')
parser.add_argument('--dataset_path', type=str, default=None, help='Dataset path')
args_opt = parser.parse_args()
# apply cache to dataset
test_cache = ds.DatasetCache(session_id=args_opt.session_id, size=0, spilling=False)
dataset = ds.Cifar10Dataset(dataset_dir=args_opt.dataset_path, num_samples=4, shuffle=False, num_parallel_workers=1,
num_shards=args_opt.num_devices, shard_id=args_opt.device, cache=test_cache)
num_iter = 0
for _ in dataset.create_dict_iterator():
num_iter += 1
print("Got {} samples on device {}".format(num_iter, args_opt.device))
直接获取完整样例代码:my_training_script.py
5.运行训练脚本。
运行Shell脚本cache.sh开启分布式训练:
$ sh cache.sh cifar-10-batches-bin/
Got 4 samples on device 0
Got 4 samples on device 1
Got 4 samples on device 2
Got 4 samples on device 3
通过cache_admin --list_sessions命令可以查看当前会话中只有一组数据,说明缓存共享成功。
$ cache_admin --list_sessions
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
3392558708 821590605 16 n/a 3227 16
6.销毁缓存会话。
在训练结束后,可以选择将当前的缓存销毁并释放内存:
$ cache_admin --destroy_session 3392558708
Drop session successfully for server on port 50052
7.关闭缓存服务器。
使用完毕后,可以选择关闭缓存服务器:
$ cache_admin --stop
Cache server on port 50052 has been stopped successfully.
当前限制
当前
GraphDataset、GeneratorDataset、PaddedDataset和NumpySlicesDataset等数据集类不支持缓存。其中,GeneratorDataset、PaddedDataset和NumpySlicesDataset属于GeneratorOp,在不支持的报错信息中会呈现“There is currently no support for GeneratorOp under cache”。经过
batch、concat、filter、repeat、skip、split、take和zip处理后的数据不支持缓存。经过随机数据增强操作(如
RandomCrop)后的数据不支持缓存。不支持在同个数据管道的不同位置嵌套使用同一个缓存实例。
缓存性能调优
使用缓存服务能够在一些场景下获得显著的性能提升,例如:
缓存经过数据增强处理后的数据,尤其是当数据预处理管道中包含decode等高复杂度操作时。在该场景下,用户不需要在每个epoch重复执行数据增强操作,可节省较多时间。
在简单网络的训练和推理过程中使用缓存服务。相比于复杂网络,简单网络的训练耗时占比更小,因此在该场景下应用缓存,能获得更显著的时间性能提升。
然而,在以下场景中使用缓存可能不会获得明显的性能收益,例如:
系统内存不足、缓存未命中等因素将导致缓存服务在时间性能上提升不明显。因此,可在使用缓存前检查可用系统内存是否充足,选择一个适当的缓存大小。
过多缓存溢出会导致时间性能变差。因此,在使用可随机访问的数据集(如
ImageFolderDataset)进行数据加载的场景,尽量不要允许缓存溢出至磁盘。在Bert等NLP类网络中使用缓存,通常不会取得性能提升。因为在NLP场景下通常不会使用到decode等高复杂度的数据增强操作。
使用non-mappable数据集(如
TFRecordDataset)的pipeline在第一个epoch的时间开销较大。根据当前的缓存机制,non-mappable数据集需要在第一个epoch训练开始前将所有数据写入缓存服务器中,因此这使得第一个epoch时间较长。