mindspore.nn.TransformerEncoderLayer
- class mindspore.nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=2048, dropout=0.1, activation='relu', layer_norm_eps=1e-5, batch_first=False, norm_first=False, dtype=mstype.float32)[source]
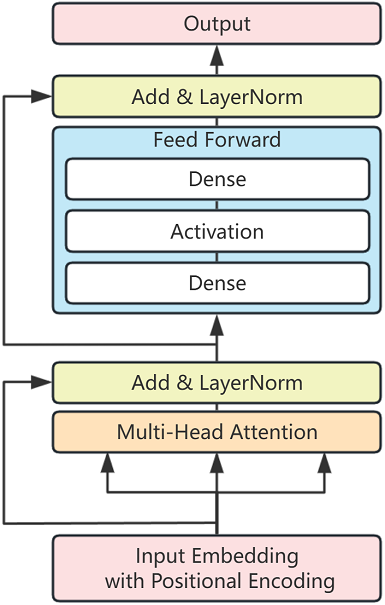
Transformer Encoder Layer. This is an implementation of the single layer of the transformer encoder layer, mainly including Multi-Head Attention, Feed Forward, Add and LayerNorm layer.
The TransformerEncoderLayer structure is shown in the following figure:
Warning
Starting after version 2.9.0, a bias parameter will be added, and the default dtype will change from
mstype.float32toNone.- Parameters:
d_model (int) – The number of features in the input tensor.
nhead (int) – The number of heads in the MultiheadAttention modules.
dim_feedforward (int) – The dimension of the feedforward layer. Default:
2048.dropout (float) – The dropout value. Default:
0.1.activation (Union[str, callable, Cell]) – The activation function of the intermediate layer, can be a string (
"relu"or"gelu"), Cell instance (mindspore.nn.ReLUormindspore.nn.GELU) or a callable (mindspore.ops.relu()ormindspore.ops.gelu()). Default:"relu".layer_norm_eps (float) – The epsilon value in LayerNorm modules. Default:
1e-5.batch_first (bool) – If batch_first=True , then the shape of input and output tensors is \((batch, seq, feature)\) , otherwise the shape is \((seq, batch, feature)\) . Default:
False.norm_first (bool) – If norm_first = True, layer normalization is located prior to attention and feedforward operations; if norm_first = False, layer normalization is located after the attention and feedforward operations. Default:
False.dtype (
mindspore.dtype) – Data type of Parameter. Default:mstype.float32.
- Inputs:
src (Tensor) - the sequence to the encoder layer. For unbatched input, the shape is \((S, E)\) ; otherwise if batch_first=False , the shape is \((S, N, E)\) and if batch_first=True , the shape is \((N, S, E)\), where \((S)\) is the source sequence length, \((N)\) is the batch number and \((E)\) is the feature number. Supported types: float16, float32, float64.
src_mask (Tensor, optional) - the mask for the src sequence. The shape is \((S, S)\) or \((N*nhead, S, S)\). Supported types: float16, float32, float64, bool. Default:
None.src_key_padding_mask (Tensor, optional) - the mask for the src keys per batch. The shape is \((S)\) for unbatched input, otherwise \((N, S)\) . Supported types: float16, float32, float64, bool. Default:
None.
- Outputs:
Tensor. The shape and dtype of Tensor are the same as src .
- Raises:
ValueError – If the init argument activation is not str, callable or Cell instance.
ValueError – If the init argument activation is not
mindspore.nn.ReLU,mindspore.nn.GELUinstance,mindspore.ops.relu(),mindspore.ops.gelu(), "relu" or "gelu" .
- Supported Platforms:
AscendGPUCPU
Examples
>>> import mindspore as ms >>> import numpy as np >>> encoder_layer = ms.nn.TransformerEncoderLayer(d_model=512, nhead=8) >>> src = ms.Tensor(np.random.rand(10, 32, 512), ms.float32) >>> out = encoder_layer(src) >>> print(out.shape) (10, 32, 512) >>> # Alternatively, when batch_first=True: >>> encoder_layer = ms.nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True) >>> src = ms.Tensor(np.random.rand(32, 10, 512), ms.float32) >>> out = encoder_layer(src) >>> print(out.shape) (32, 10, 512)